字體:小 中 大
字體:小 中 大 |
|
|
|
| 2024/04/10 06:56:28瀏覽733|回應0|推薦8 | |
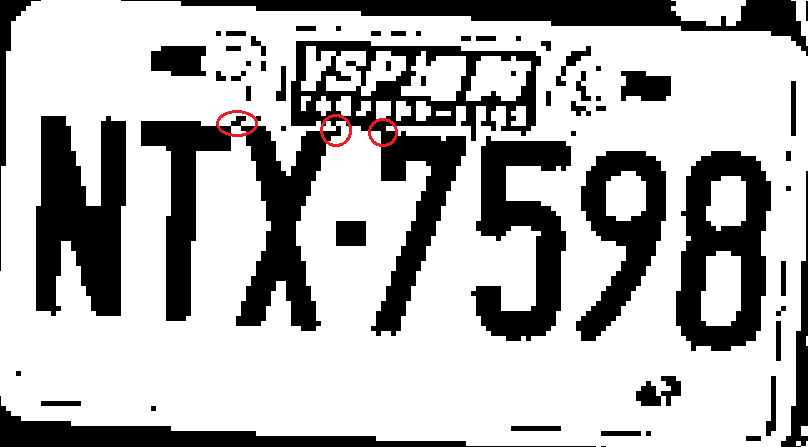
如上這一張以人眼的標準不可能辨識錯誤的車牌,但是卻會讓現階段的影像辨識技術都大為尷尬!如上放大的二值化圖所示,因為貼紙與隨機的背景雜訊,會藕斷絲連的將T、X與7三個字元沾連,按照OCR的邏輯,這個形狀怪異的連體嬰當然無法被辨識為任何一個合理的字元! 那聰明的「AI」呢?就是用CNN類神經網路應該就可以辨識了吧!是的!絕對可以!但是必須掃描全圖,在不能預知實際字元大小的前提下,還必須作好幾個不同尺度的全域掃描!你家有錢太多花不完,可以去買超級電腦AI晶片加上CNN軟體來做這件事!但是我的客戶多半買不起(或不願花大錢)買這種軟體與設備。AI誰都想要,但是太貴就以後再說了! 所以我的事業挑戰已經不只是「做到」困難的辨識!還必須發明出計算量盡量少,在一般人買得起(也願意買)的電腦設備上就可以表現得很「AI」的辨識軟體!如果現在那些高唱AI的公司是在研發影像辨識的千萬超跑,我就像是正在研發便宜好開幾十萬就可以入手的國民車的廠商了!我做的AI影像辨識不管研發或運轉成本都很低的!但是辨識效能卻能始終保持領先!CNN目前還完全跟不上我的! 我的技術是以OCR為基底的,碰到上面這種案例,我當然可以輕易辨識出N、5、9與8四個字,信心符合度還很高!但是因為中間缺了三個字元,要猜測相距很遠的N與其他三個589是屬於同一車牌?很勉強的!如果條件放得那麼鬆,那我的計算量與誤判機率都會升高,又會掉進跟CNN一樣,計算量大到不合理的窘境了! 如同稍早研究印尼車牌時發表的技術,我決定將Local CNN的概念導入我的OCR程式!就是當我用OCR找到確定可靠的車牌字元時,在可能有因為沾連而被忽視的字元存在的周邊小區域做CNN方式的掃描探索!譬如5字的右邊已經有個9字就不必找了,但可以試試掃描左邊就會發現有個漂亮的7字了!車牌就是很多字元組成的嘛!不會孤立存在的!只要集中火力在清楚的字旁邊搜索,那些生了小病原本無法辨識的字元就都被釋放了! 而且你在某字旁邊找到隱藏的鄰居時,這個迴路可以持續下去,譬如上例找到7字之後可以7為中心繼續找到X甚至T!所以只要七個車牌字元有一個被清晰辨識到,其他因為一些奇怪隨機的因素被沾連的字元都可以順藤摸瓜式的一一用CNN挖掘出來了!這對於常常因為貼紙干擾而無法辨識的機車車牌用處可大了! 最終的結果就是如下圖所示,實心的TX7三個字元都是藉由前處理階段已辨識出來的N與5在其周邊做CNN掃描運算找到的!因為OCR本來運算量就遠低於CNN,我用這種方式只在局部很可能有隱藏字元的小範圍作CNN探索,運算量增加就非常少了!也證明效果非常好!低成本高效率的AI辨識就做出來了!
天底下沒有甚麼超自然的新鮮事!當大家看到我可以辨識很糟糕狀況的車牌時不必覺得我有甚麼神奇的法力?我只是努力整合所有已知技術嘗試解決問題有點成效而已!所有成功的AI工作者都應該是這樣在上班的!千萬不要迷信只用ML、DL與CNN就可以解決所有的問題!讓自己眼界更開闊一點吧!至少在影像辨識領域,迷信狹義的AI鐵定會讓你傾家蕩產還一事無成的! 最累人的工作其實不是發明這些方法,而是適用於這些方法的「病例」埋藏在數千數萬張正常的照片之中,沒有足夠的適用病例我就很難驗證我的方法是否有效?或是否會有副作用?這跟使用機器學習的人困擾相似,資料或許很多,但適合訓練特殊狀況的案例非常少!自己模擬做出來的假資料是可以做實驗研究用,但沒有真實資料作驗證永遠不會讓人放心的! 目前我的這個新程序玩了兩三天也只找到十幾二十個可用於驗證的實例而已!微妙的是:這些案例用我以前的舊藥方多數也可以辨識成功的!但是就好像醫療方法的進步,有了更好更可靠有效的療法,傳統的偏方即使能治好病也應該被取代了!所以最近幾天必須一一檢視個案找到這些罕見病例,讓我的新方法更成熟,要上班囉! |
|
| ( 心情隨筆|工作職場 ) |