字體:小 中 大
字體:小 中 大 |
|
|
|
| 2019/10/29 09:23:42瀏覽39533|回應9|推薦20 | |
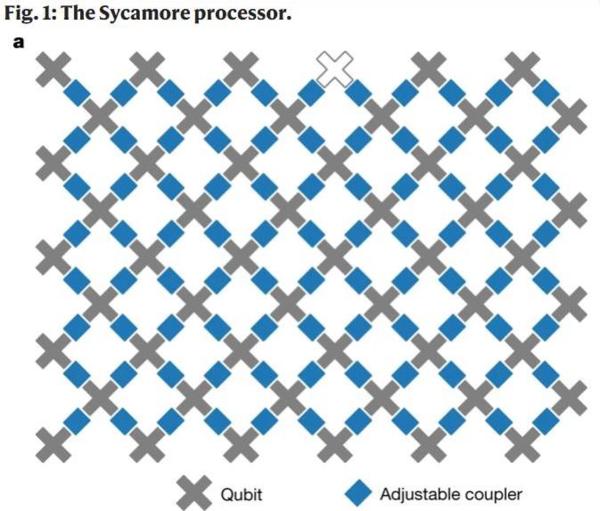
上周應《觀察者網》的邀請,針對Google在十月23日正式發表的“量子霸權”論文寫了一篇評論。我基本上是基於上月寫的《Google的量子霸權是怎麽回事》一文,加入了新公開的技術細節,重新修飾整理,所以這篇新文章並不是後續或補充,而是早先文章的增訂版。 《觀察者網》最近稿子多,所以一直到今天(十月28日)才刊出,參見http://www.guancha.cn/wangmengyuan/2019_10_29_523101.shtml。 ================================================================ 上個月,NASA大意提前泄露了Google的量子霸權論文,因爲違反了Google公關部門的計劃,所以很快就撤下。其後,Google遵循典型的商業炒作方案,始終三緘其口,一直到2019年十月23日,論文正式在《Nature》發表(參見https://www.nature.com/articles/s41586-019-1666-5),伴隨著各式各樣的公關吹噓,鋪天蓋地而來。 有趣的是,與其同時,IBM在官方博客公然唱反調,發表了一篇自己的論文稿,宣稱已經證明Google並沒有達到量子霸權。那麽到底誰是誰非呢? 首先,我們先回顧一下什麽是“量子霸權”;它指的是量子計算機在某個有實用價值的程序上能比現有的古典電腦高效許多。請注意,一般人往往忘記這個定義中要求有實用價值的那部分,所以我一開始就疑心Google團隊鑽的是這個漏洞,而且已經寫過一篇文章來推測其中的奧秘(參見前文《Google的量子霸權是怎麽回事?》)。現在因爲有了更詳細的消息,我可以更精確地解釋Google的這篇論文,希望讓理工科出身的讀者都能理解。 下面是Google所用的Sycamore(梧桐;名字純屬巧合,不要亂做聯想)量子處理器的示意圖;其中灰色的叉叉是個別量子位元,藍色的長方塊是耦合器,共有88個,它們負責將兩個相鄰的位元轉化為糾纏態。原本應該有54個量子位元,但是其中一個失效無法修復(白色叉叉),所以整個實驗只能用上53個位元;有效的耦合器也因而減少了兩個,剩下86個。
Google所做的程序是先從86個耦合器和53個位元中隨機選出部分,被選中的會被開啓而發生作用,叫做閘門(Gate)。位元的閘門(Single-Qubit Gate)作用是產生對應著隨機古典結果的量子態;耦合器的閘門(Two-Qubit Gate)作用則是將相鄰的位元糾纏起來。這些作用合起來,形成一個循環(Cycle);全部總共有20多個循環被事先隨機確定,它們一起組成一個綫路(Circuit)。Google在實驗中所用的最複雜綫路,包含了1113個單位元閘門和430個雙位元閘門。 接下去是重複以下的這個程序圈子(Loop):首先把所有的位元清零;接著讓事先選定的固定綫路發生作用,製造出新的量子態;然後全部位元進行塌縮,以便形成古典的0或1讀出。所以結果是一個看似隨機的53位元序列,但是内含量子糾纏,所以位元之間並非真正的統計獨立,而是有由量子糾纏來決定的複雜相關性(Correlation)。 經過小規模的試用之後,最終Google團隊用全部53個量子位元跑這個程序圈子3千萬次,這一共費時200秒。Google估計最新的古典超級電腦也要耗時10000年,所以可以自誇量子霸權。 IBM出來潑冷水的研究,是采用了更高效的古典超級電腦設置,結果只用了兩天半,大約比Google團隊的估計快了八個數量級,所以並非沒有意義的。 然而這個古典程序的運行時間(Runtime),可以在數學上證明是與2^n成正比,這裏n是量子位元的數目,亦即Google實驗中的53。所以即使在n=53的條件下古典電腦還可以一搏,到n=90左右的時候,也會重現量子霸權。這大概也就是三四年的研發時間。 IBM的算法(Algorithm)仍然是以蠻力(Brute Force)為主,如果未來發明了更巧妙的算法,可能會讓古典程序又再增速幾個數量級,不過這頂多是把門檻擡高到n=200。換句話說,最多最多也就是延遲Google的量子霸權十年左右罷了。 那麽我們的結論是量子霸權在2030年之前必然會發生嗎?不是的,Google這篇論文的真正問題,不在這些細節上,而在於整體設計,也就是我在本文開頭所提的,程序的實用價值。 要比較兩個不同工程方案的優劣,一個很重要的隱性前提是要達成同樣的、有實用價值的目標。Google的公關文稿,把他們的這個“成就”和100多年前Wright Brothers的首次飛行相比,就是故意混肴視聽:Wright Brothers的飛機是圍繞著一個歷史長久、公認有價值的目標(亦即動力飛行)而設計製造的成品;Google的Sycamore卻執行了一個一點用處都沒有的程序。真正類似的,是建造出一個複雜而沒有實用性的機器,然後說它在產生獨特的噪音上,有無可比擬的效率。換句話説,他們是先射箭、再畫靶,Sycamore自己隨便動一動,然後叫古典電腦來做模擬;如果這樣也算量子霸權,那麽隨便找一個有53個原子的系統,要求古典電腦來模擬它歷時200秒的演變,同樣也會需要萬年以上。 事實上,Google的這個結果,比毫無實用價值還要糟糕。要理解這一點,我們先回顧一下當前量子計算界的處境。現在的世界記錄是大約100個量子位元(DWave的量子計算機是假的);但是這些位元很不穩定,非常容易與周圍的巨觀環境起作用而喪失量子態,這是我以前詳細討論過的量子退相干過程(Quantum Decoherence)。要知道計算的輸出(Output)是程序邏輯的結果,而不是量子噪音的後果,就必須有糾錯機制。 目前人類所知的量子糾錯機制,必須用上80-10000個原始的量子位元,才能產生1個穩定可靠的位元(叫做邏輯位元,Logical Bit)。世界記錄是連1個邏輯位元都沒有的。 Google的這個“突破”,第一個巧妙之處在於用的是内生的(Endogenous)隨機量子態,而不是事先指定的(亦即Exogenous,外源性的)串列。雖然Google團隊可以試圖去影響這些原始量子位元之間的糾纏,實際上是否成功,並不能絕對精確地驗證。換句話說,他們根本沒有解決糾錯的基本難關,而只估計出Sycamore保持量子態的半衰期大約是10微秒,那麽因爲每一輪程序圈子費時不到7微秒(=200秒/30000000輪),大部分時候量子退相干還沒有發生。然後又再巧妙地只考慮統計結果,那麽少部分的噪音就可以遮蓋住了。 這裏最基本的毛病,在於Google的量子計算機並無法自行保證結果是正確的,事實上我們知道它不可能是絕對正確的,頂多只能是近似正確。相對的,古典電腦給出的結果卻是絕對精確可靠的。這時硬要比較兩者所費的時間,顯然不是公平的。
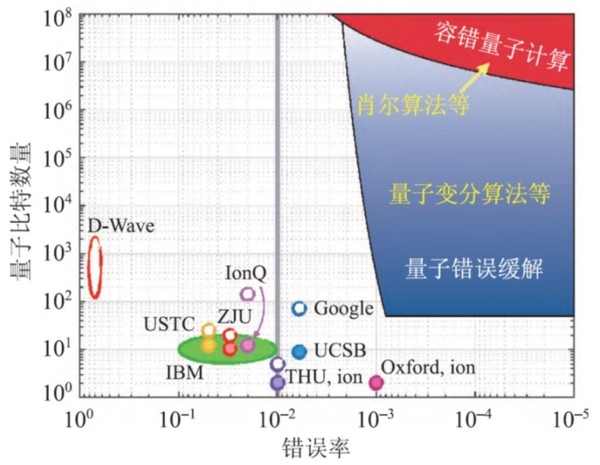
其實要有丁點實用價值的量子計算,至少也必須達到上圖(来自孙昌璞院士等作者的论文)的藍色區域。目前量子計算被吹捧並獲得各國政府極度重視的真正原因,是能夠破解通信上的公開碼,那麽就必須達到上圖中的紅色區域。Google的量子計算機雖然算是先進,但距離實用目標還有至少九個數量級之遙;現在就宣稱勝利,純屬忽悠大衆的商業宣傳。 【後註一】Google量子計算機團隊負責硬件的主管John Martinis上周忽然宣佈離職,昨天(2020年四月30日)《Forbes》登出對他的采訪(參見《Googles top quantum scientist explains in detail why he resigned》),内容是標準的八股,不過有一個有趣的細節,可能解釋這位Martinis教授真正被排斥的原因:他説他堅決要求整個團隊投入量子霸權項目,受到多數研究人員的反對。嗯...Google量子計算機的團隊成員反對搞這個項目,我不知道是否與它是假大空有關... 【後註二,2021/09/29】對量子計算行業内的專家來説,Google和中國研究團隊過去幾年的所謂“量子霸權”突破,都很明顯是忽悠大衆的胡扯,這是因爲這些公關稿完全忽略Error Correction(亦即正文裏所談的糾錯機制),所以先天就不可能實用化。行内人用來安撫自己良心的“真實進展”,其實來自2018年在《Nature》發表的一篇論文(參見《Quantized Majorana conductance》;請注意名列前茅的中國籍作者,當年也曾經在中文媒體上大肆吹噓過,雖然當時我心中立刻嚴重存疑,但沒有實證,所以也就不予置評)。簡單來説,他們宣稱創造了虛擬的Majorana粒子,這些粒子可以抗拒外來的擾動,從而規避量子態容易塌縮的問題,從根本解決對糾錯機制的依賴。 沒有多久,遠遠比我更熟悉這些技術細節的實驗物理學家就出面質疑這個結果,雙方爭論到今年三月,原作者團隊全軍覆沒,承認扭曲了統計分析,但仍堅持不是故意造假,而是“無意間”過濾掉部分不想要的數據,導致假陽性結果(“無意間的錯誤分析”,似乎是專門感染中國科學界的流行性疾病,我在此再一次强烈建議中國政府高層對病源做溯源研究)。不論如何,這篇論文已經撤稿;其折衝細節,《Quantum》剛剛發表了一篇檢討回顧(參見《Major Quantum Computing Strategy Suffers Serious Setbacks》),有興趣的讀者可以參考。當然,這代表著量子計算那整個行業又回歸100%忽悠的純量子態;拜中國的學術管理體制所賜,這個量子態倒是能夠抗拒塌縮、也無從糾錯的。 【後註三,2022/08/02】2019年Google大肆吹噓量子霸權的時候,我立刻指出這是雙重謊言:一方面精選無實際意義、但特別適合自己機器自然運行的“題目”,另一方面特意大幅低估傳統電腦複製同一結果的效率;現在《Science》引用《Physics Review Letters》上的新論文(參見《Ordinary computers can beat Google’s quantum computer after all》)證實我的推論。我想提醒大家,之所以要等三年,正是因爲那個程序毫無實用價值,所以以往全世界從來沒有任何專業人員關心過,直到Google利用這個漏洞來做虛假宣傳才有人開始研究與之對應的傳統電腦算法。 |
|
| ( 不分類|不分類 ) |