字體:小 中 大
字體:小 中 大 |
|
|
|
| 2024/10/08 04:40:53瀏覽630|回應0|推薦6 | |
影像辨識是非常複雜的工作,尤其是要在如上這種資訊複雜的畫面中「迅速」找到你想辨識的目標,在實務的需求上,不僅辨識必須正確,辨識率至少要到95%以上的高標準!辨識速度也不能太慢,至少必須比人眼辨識的速度更快,而且在一樣的電腦設備上,速度越快表示越省電,如果軟體效能好速度夠快也表示可以使用較低階便宜的設備做運算達標,那就是降低系統的成本了!那才是我們導入AI的最重要目的! 我的軟體開發一向都是以更準也更快作為具體目標,當然對於複雜環境的容忍度與辨識能力也是不斷強化不會迴避的!如上圖字元小環境複雜的難度下,我的軟體還是可以在一般規格的電腦上跑出驚人的35毫秒的速度!我特地附上原圖,讓所有高手們也可以下載一試身手!歡迎CNN高手來PK! 目前影像辨識技術發展上有兩個大迷思!一個是誤以為提升硬體的「算力」就可以達到高辨識率?一個是誤以為大量資料的「訓練」就可以達到高辨識率?其實這些都不是直接可以提升辨識率的關鍵,重點與前提還是可以「合理」,也就是可以合乎科學與事實設計出能正確辨識目標的演算法!如何正確合理的找到目標資訊才是影像辨識技術的核心!
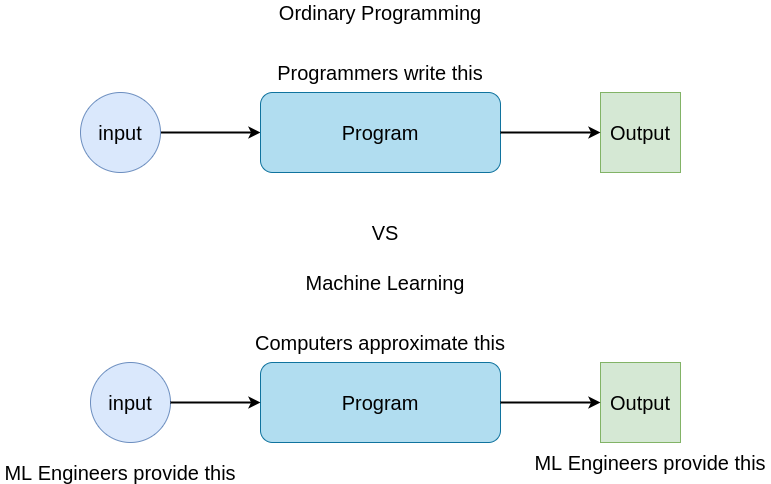
如上圖所示:所謂的Ordinary Programming就是依據輸入影像,外加很多科學原理與參考規則寫出可以明確辨識目標的程式,也就是所謂的演算法模式!依據各種題目一一對症下藥精準解題的模式!至於Machine Learning的模式則是:Input 與Output都由工程師提供,Input就是原圖,Output則是用人腦人眼辨識的「正確」答案!就是用統計逆推的方式幫工程師「寫程式」!類似使用大量題庫與標準答案用統計技術找出「猜題」(而非解題)正確率最高的模式! 現在這些以機器學習技術為基底的AI技術的宣傳,已經讓多數人都相信上述統計逆推出來的「程式」會比正向依據明確資訊開發出來的演算法更好更快?果真如此,大家都不必讀很多書學習各種科學專業了!因為用資料逆推歸納出來的程式,就比你讀很多書還焚膏繼晷傷腦筋寫出來的演算法程式更好了!那還讀甚麼書?學甚麼專業呢?你只要會收集資料餵給電腦不就AI了嗎? 這就是基於機器學習的狹義AI建構出來的海市蜃樓!其他領域是否可行?我不太懂不予置評!但這種模式在影像辨識領域幾乎是完全不可行的!首先是影像辨識應用需要的辨識率都很高,95%算是低標,如停車場的車牌辨識就至少要98%,但是以統計學為基礎的AI是尋求一個妥協的「最佳解」!也就是可「答對」最多題的程式流程與參數組合! 因為他們只是尋求一個萬靈丹,而非合理解析每一個案例給予最合理的辨識,所以對於與正常影像偏差度較大的影像辨識就很難通通正確!整體辨識率總是有個難以突破的天花板,那個天花板距離95%都還很遠!所以截至目前市場上的這些廣泛使用的辨識軟體都還「不是」用這些機器學習概念作的!因為95%以上的高辨識率他們始終難以接近! 機器學習模式除了正確率在理論上就有先天障礙,難以達到商業化產品的標準之外,計算量也大得不合理!需要非常多資料來學習訓練模型,取得資料與標記資料的人力成本就遠超過傳統的演算法開發模式了!所以機器學習絕對不是一種可以節省人力成本的AI開發模式!反而是非常燒錢浪費資源的不合理之路!成功率不高,需要投入的資本卻最多! 而且機器學習完全不像精準的演算法那麼有效率,只會做必要的計算,機器學習的辨識模式基本上只是用很多經驗值猜答案,也就是先要用CNN地毯式搜索很多含糊資訊,再以這些資訊為猜答案時的量化基礎,總之就是需要高於傳統精準演算法很多很多倍的計算量!最終還是用猜的! 正因為這些嘗試錯誤為基礎的AI,從研發到執行的計算量都大到不合理,正常的CPU總是不堪負荷,才會需要很多GPU或NPU的額外計算設備幫忙的!所以對於影像辨識領域來說,並不是因為AI好才需要用GPU,反而是因為AI核心技術的缺陷才那麼需要GPU的!相對的,使用傳統演算法模式開發的影像辨識軟體都不需要GPU幫忙的! 我不會胡說八道吹牛的!如果CNN專家或玩家不服氣,可以拿我前面的貨櫃碼影像PK一下!希望他們敢跟我一樣公布正確辨識的速度與使用的設備!沒有特殊規格的電腦相助,CNN等AI技術幾乎是根本無法在一般規格的電腦上做影像辨識的!即使砸錢買設備讓速度跟上了,辨識率也永遠跟不上傳統演算法的!
|
|
| ( 心情隨筆|工作職場 ) |