字體:小 中 大
字體:小 中 大 |
|
|
|
| 2024/08/24 05:04:07瀏覽403|回應0|推薦4 | |
上圖就是我可以辨識很歪斜車牌的技術機密!重點關鍵就是在右下圖中我必須很精準的找到車牌字元區的邊界!有了這四個精準的任意四邊形邊界,我才能準確將歪斜變形的車牌經過幾何投影的過程轉正為合理正面的車牌影像,之後才能訴諸標準字模的比對辨識它們是甚麼字!
沒有深入研究的人,可能會天真的以為可以用機器學習辨識手寫字的方式,用類似上圖顯示的眾多變形字體來「訓練」機器學習模型,認識自然拍攝影像中的歪斜車牌字元?AI影像辨識專家們也會暗示讀者他們可以這麼做到辨識歪斜字型?但事實上依照他們說的ML、DL與CNN演算法是根本做不到的! 首先是不可能蒐集到這麼多的變形資料,所以即使是現在號稱可以辨識手寫字的AI軟體,實測辨識率也絕對不是車牌辨識需要達到的至少90%以上的高標準!有七八成就很驚艷了!而且車牌因為各種角度歪斜產生的變形可能狀況是無限大的,資料再多都無法做出95%以上的訓練成果,更不用說必須消耗的成本根本大到難以想像,一般人想試試看都玩不起的! 所以用大量歪斜變形資料訓練AI直接辨識字元是不可能走的一條路!但是這些歪斜車牌影像的本尊實體都是一個用標準字型印製的矩形區塊,不像手寫字的隨興狀況連筆畫內部都有變數,所以只要能像我的方式找到「正確」也「準確」的車牌字元組的四個邊界,就可以轉正任何角度歪斜變形的車牌,這是理論上必須,也是唯一可以走的辨識之路!如有其他方式請告訴我!你應該可以得到AI學門的諾貝爾獎!
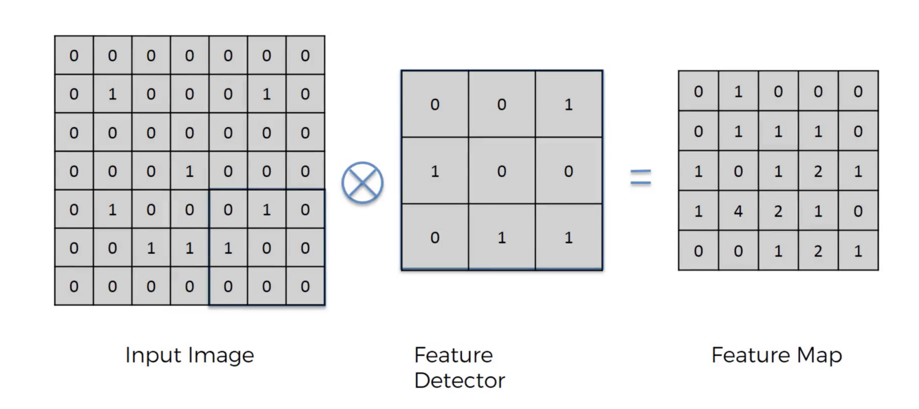
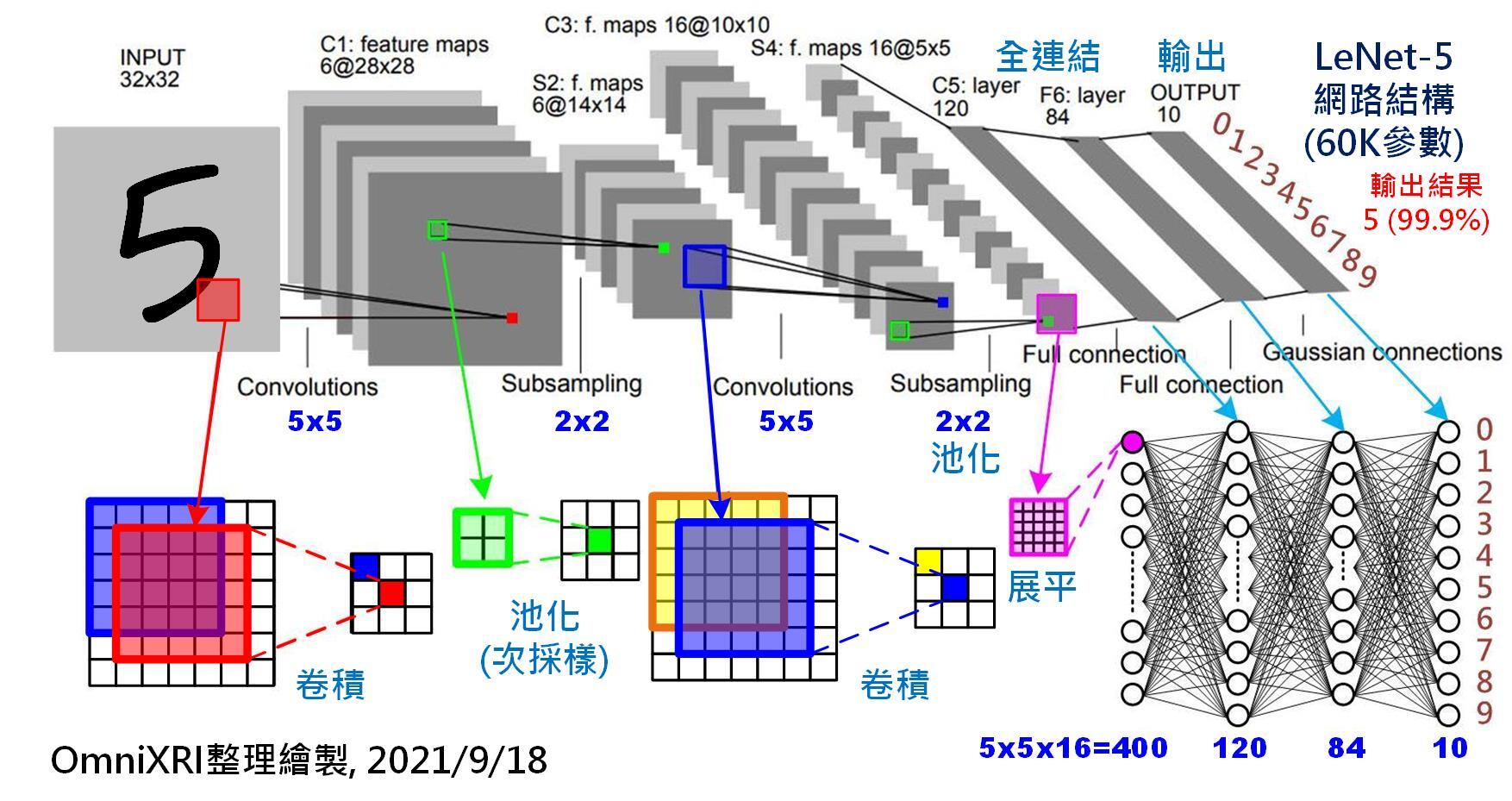
上面是CNN與DL影像辨識的資料處理的示意圖,經過多次卷積(Convollution)運算之後,必然會將資訊的空間解析度降低!後續的運算目的只是「找到」目標,而非「辨識」目標!所以即使是歪斜的車牌,理論上他們應該也是找得到的!這就他們最得意的成就:目標偵測!但不包含正確辨識出目標的內容!這樣算是影像「辨識」的完整技術嗎? 因為上述流程中已經失去原始資料的空間解析度,也就是目標位置與形狀的「精確度」已經喪失了!所以他們的程序絕對無法直接做到我的四邊切線與正確精準的幾何變形處理!這就是他們所謂的AI影像辨識只能「找」目標卻無法「辨識」目標的尷尬真相與原因了!真要完成辨識是不能喪失原影像的高解析度的!即使前段處理丟掉了,後段處理都得找回來! 他們如果要在既有架構中追上我的腳步完成歪斜車牌辨識,就必須在用CNN與DL找到目標之後,在目標區恢復原始解析度進行跟我類似的精準定位與幾何處理,沒有其他的選擇!那後半段就類似移植嫁接OCR了!我不知道他們會不會拉得下這個臉?OCR不是應該被CNN與DL淘汰了嗎?而且我的辨識流程甚至只用OCR技術,不必靠CNN或DL就可以找到歪斜車牌目標了!原始解析度始終沒有被簡化降低,找到目標的速度還更快!更凸顯使用DL+CNN多此一舉自找麻煩的荒謬了! 現在的AI影像辨識專家們最會的就是含糊其辭誤導視聽,最不會的就是把話說清楚!他們總是暗示ML+DL+CNN可以做到任何事?我只想知道按照他們的邏輯方法要怎麼完成辨識歪斜車牌的工作?不必講得太詳細洩漏商業機密,只要講到讓有常識的人認為可行就好了!我天天都在這麼做!而且劍及履及不但原理說得任何人都聽得懂,也做出實際產品在賣了!希望AI專家們也有這個膽識與氣度!說老實話就好,不要再騙了! |
|
| ( 心情隨筆|工作職場 ) |