字體:小 中 大
字體:小 中 大 |
|
|
|
| 2024/08/27 04:50:14瀏覽604|回應0|推薦7 | |
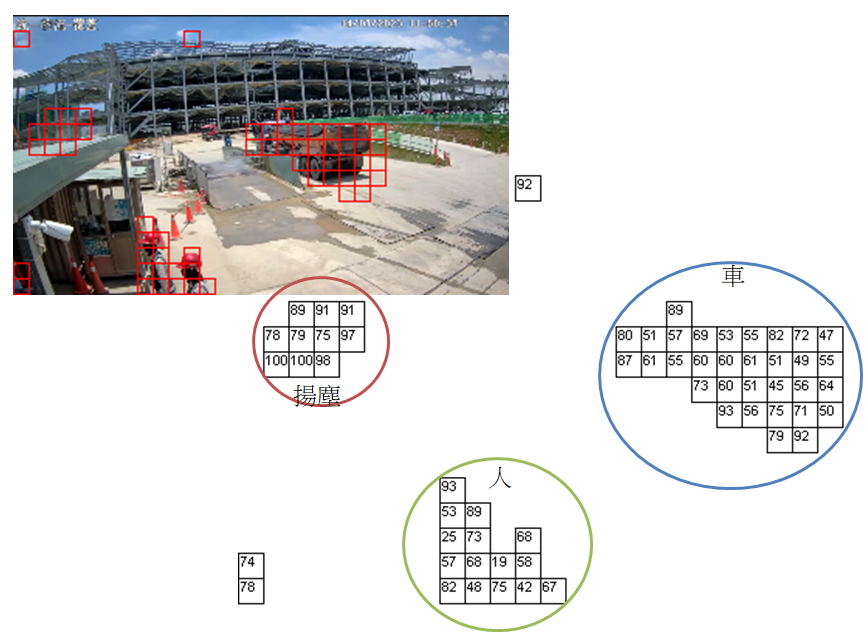
現在任何廣告或報導,一提到影像辨識就會充斥著含糊其辭的AI謬論,好像所有的影像辨識都必須經過大量資料的學習訓練才能完成?不只是一般民眾而已,我在業界接觸的專業人士也多半被洗腦成以為真的是這樣了?動不動就問我需要多少資料來「訓練」模型? 其實九成以上的影像辨識都不需如此做的!用大量資料學習訓練來取得影像辨識結果,是非常高成本低效率的做法。對我們公司來說,任何目標的影像辨識都是一個真實世界的物理事件,絕對有非常充分合理的影像特徵可以偵測分析,做出科學上無可置疑的辨識結果!完全不需要非常大量的資料,也不需要冗長的訓練過程,了解目標的物理成因與特性設計針對性的演算法,就可以做出比機器學習更準確穩定的辨識軟體了! 如上圖是我們想偵測工地揚塵的示意圖,物理事實就是:工地影像中影像有變動與不動的部分,不動的背景就是確定沒有揚塵的地方,直接就排除了!會動的部分呢?可能是揚塵,也可能是移動中的車輛、工人或其他機具。我們要做的就是進一步分析這些擾動區誰才是真的揚塵? 我們用的邏輯也很簡單!揚塵是有透明度的!即使有偵測到畫面擾動,但是深入該區分析影像,原本無塵時的背景特徵還是很明顯的!如上圖左的揚塵區還是可以看到背後的鷹架的!如果是實體的人車或機具移動造成的擾動呢?當然就是會完全遮住原本的背景,你在擾動區不會偵測到原本該處的背景物件特徵。 這些都是一定不會錯的物理現象,也不難從影像中偵測分析出我們需要的影像量化特徵!所以我們只需要三五個揚塵事件案例作為研究素材,就可以很快的研發製作出相當穩定準確的影像辨識軟體!反而是使用大量數據去訓練學習的系統會充滿不確定性,出現錯誤時也很難解釋原因調整優化的。 所以當你開始接受使用機器學習概念的技術時,你其實已經主動放棄了研究影像辨識時,最重要且絕對不會錯誤的科學定理!Data Driven的意思就是由資料決定辨識的原則定律,當然比資料更可靠的科學定理就被你忽略排除了!在機器學習的訓練調整過程中是以資料為主導,不會考慮是否違反物理定律的! 一般來說,影像資料與科學定理會「大致」符合,但是資料會受到不只物理環境事實的其他很多雜訊干擾!譬如攝影機的故障異常、電子訊號干擾、鏡頭髒污或焦距失準等等!所以用大量資料學習訓練,也就是數學上的回歸逆推運算出來的結果只是統計學上包含所有雜訊影響的「近似值」,不是完全合乎科學定律的正確演算結果! 那些與實際事件的物理現象無關的雜訊都會降低辨識的準確率,並不是資料越多就能保證結果會越好!除非你假設已知的物理科學定律毫無意義!換言之,即使好資料多於壞資料,訓練結果也絕對不會比嚴格依照物理定律研發出來的演算法辨識率更高的!頂多是機器學習使用的資料完美無瑕,那也只能追平正向研發科學演算法的成果而已!採用物理原則設計的演算法,常常是可以直接忽略那些與關鍵物理現象無關的雜訊的!譬如在此例中鏡頭的髒污是不會動的,所以在我們的處理方式中是被忽略的背景,不會影響我們的辨識結果! 所以理論上,如果要辨識的目標不是用既有的科學原理難以分析掌握的隨機事件(如股票漲跌),機器學習怎麼作都不會比使用科學定理為基礎的演算法表現更好的!根據科學定理做出來的影像辨識就是天花板,機器學習最厲害也只是勉強追上,不可能超越的!這是學術理論上就可以證明的事實! 不僅如此,使用機器學習還非常昂貴!一個較不準確的方法如果有成本低的優勢還是有價值的!譬如精準到毫克的電子秤可能貴到數千元,一般人秤體重的電子秤準度只到0.1公斤,就只需幾百元,還是很有市場價值的!如果較低精度的體重計,還要價更高?要賣幾萬元呢?你會買嗎? 這就是機器學習技術作影像辨識工作的尷尬現況了!它們在理論上就永遠不會比傳統演算法的研發結果準,但是需要的資料量大,資料訓練的演算量也很大,加起來就是研發成本必然會高於傳統演算法研究很多倍!當然是貴而不惠的奢侈研發方式!最終產品當然也會貴得要命!卻沒有比較準確?不就尷尬了!我說的都是顯而易見大家都可以理解,也可以隨時去研發現場檢驗的事實! 所以你還覺得那種只包含ML、DL與CNN的狹義AI無所不能嗎?還以為它們是影像辨識必然的主體與未來嗎?世人還要被這種荒謬的AI迷思迷惑耽誤多久呢? |
|
| ( 心情隨筆|工作職場 ) |