字體:小 中 大
字體:小 中 大 |
|
|
|
| 2020/06/14 21:46:40瀏覽3658|回應0|推薦14 | |
Python機器學習筆記(十一):「維度降低」(dimensionality reduction)練習 - 有看沒懂的有字天書 一、「維度降低」的概念 「維度降低」是個數學代數上的一個抽象概念,簡略地說,一個多維度空間裏的函數(例如4個維度),我們可經由對該函數結構推理,將該高維度的函數壓縮映射投影至一個較低維度的空間裏(例如2個維度),在這個較低維度的子空間裏,仍依然保有原高維度函數的大多數結構資訊,我們即可利用這個低維度的替身,來探索較複雜的高維度本尊的結構特性。 二、「維度降低」在機器學習領域上的運用優點 1.提高模型運算效能 機器學習模型運算是需要資源的,當我們將高維度的數據集壓縮到一個較小的維度裏時,這意味著我們需要計算的東西變少了,相對應的資源耗費當然也變少了,可提高模型的運算效能。 2.「維度降低」利於數據集的視覺化呈現 由於我們至多只能在3維的空間裏展現視覺圖形,4個維度以上的數據集,很難以一目瞭然的方式將其視覺化。但我們若能將高維度的數據集壓縮至3個維度以內的子空間內,我們即可在這個低維度的子空間內視覺化數據集的結構特點。 三、利用鳶尾花數據集練習「維度降低」 1.鳶尾花數據集 鳶尾花數據集是機器學習領域裏很有名的初階練習數據集。該數據集的來源是Ronald Fisher於1936年時分析蒐集的150朵鳶尾花資料,其紀錄了每朵花的的花萼長(sepal length)、花萼寬(sepal width)、花瓣長(petal length)與花瓣寬(petal width)4種資訊,而這150朵鳶尾則分屬setosa、versicolor與Virginica這三種品種。Python的Scikit Learn套件已內建鳶尾花數據集,其具有sepal length、sepal width、petal length與petal width這4種特徵(feature),即數據集有4個維度,而花的品種則是數據集的目標(target)類別。機器學習模型的目的,是當我們拿到一朵新的未見過的鳶尾花的sepal length、sepal width、petal length與petal width這4個資料時,我們即能正確判定這朵花所屬品種。 2.視覺化鳶尾花的特徵與目標類別(品種)間的關係
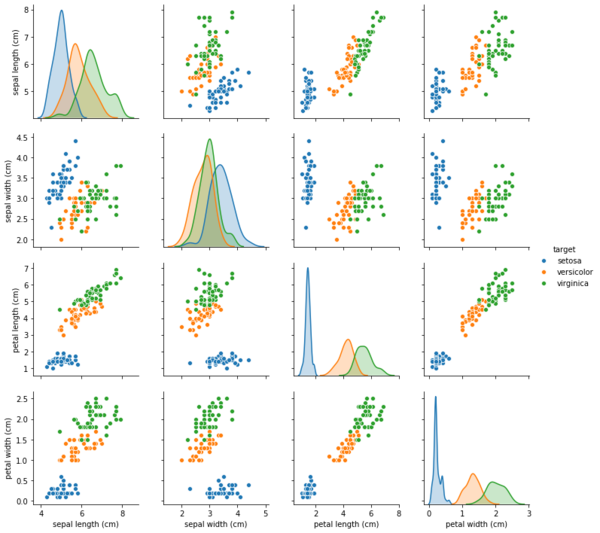
我們很難視覺化一個有4個維度的資料,在此我運用Python的Seaborn套件裏的成對圖表(pair plots)方法,以特徵二二成對方式,來分析呈現資料特性。在第一張圖中,橫軸由左至右及縱軸從上到下,依序放上sepal length、sepal width、petal length與petal width這4個特徵項目,二二成對,可產生4x4總共16個子圖。最左上角的子圖,橫軸與縱軸的分析特徵皆為sepal length,此時子圖呈現的是setosa(藍色線)、versicolor(橘色線)與virginica(綠色線)這三個品種與sepal length這個單一特徵的數量分佈圖,子圖橫軸為sepal length數值,縱軸為各品種在sepal length各數值下的對應樣本數量。接著由左上角子圖,垂直往下到下一個子圖,這時橫軸的分析特徵仍是sepal length,縱軸的分析特徵則變為sepal width,圖上的藍色、橘色、綠色點,各代表每個setosa、versicolor、virginica品種樣本所對應的sepal length與sepal width的觀察紀錄數值。以此類推,我們可了解其餘子圖所傳達的意思,從左上角往右下角的4個子圖,呈現各品種在單一特徵下的數量分佈圖,其餘子圖則是各品種在二二特徵組合下的關係分佈圖。從二二特徵關係子圖中,可看出,setosa與其它二種品種versicolor、virginica可明顯區隔開來,versicolor與virginica彼此間雖也可分為二個區塊,但在相鄰處,有少數的versicolor與virginica的樣本混雜在一起。 3.利用「線性判別分析」(linear discriminant analysis, LDA)技術降維 雖然前面利用成對圖表的技巧來探究鳶尾花資料集的特性,但畢竟要匯聚16個子圖的內容來歸納結果,並非簡潔易懂,這時就可借助「維度降低」了。在此利用「維度降低」其中一種技巧 -「線性判別分析」,LDA。LDA演算法模型會參考資料中的目標類別(即setosa、versicolor與virginica三種鳶尾花品種)資訊,來最大化一個「線性特徵(feature)空間」的「目標類別分離性」,而將資料樣本「投影」(project)到新「特徵子空間」中。在看過前面這段我從書上抄來有看沒懂的有字天書後,接著練習如何運作scikit learn已實作的LDA轉換器。為便於後續說明,假設X為鳶尾花數據集的特徵矩陣(feature matrix),即每筆樣本的sepal length、sepal width、petal length與petal width這4個特徵項目的數值,y為目標類別向量(target vector),是記載每筆樣本是屬setosa、versicolor或virginica何種品種。 (1)匯入LDA類別 from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA (2)初始化LDA轉換器 lda = LDA(n_components=2) n_components這個超參數是在設定要產生多少個新的「特徵子空間」,這個正整數值要不大於原數據集的特徵數,這樣才有降維的效果。此處是將原有的4維特徵空間降至2個「特徵子空間」維度。 (3)拿鳶尾花資料集來訓練LDA轉換器 lda.fit(X, y) (4)將鳶尾花數據集資料「投影」到「新的2維特徵子空間」 X_lda = lda.transform(X) X_lda是投影後的2維特徵子空間資料。 (5)畫出降維後特徵子空間上的資料
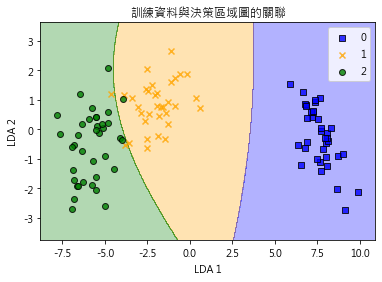
這時我們就可將投影後的資料畫在一個2維的平面圖上,如第二張圖,圖中藍色方塊為setosa品種,橘色叉叉為versicolor,綠色圓圈為Virginia,結果如同先前用16個子圖的成對圖表方法所展示的,setosa與其它二種品種versicolor、virginica有明顯區隔開來,versicolor與virginica彼此間雖也可分為二個區塊,但在相鄰處,有少數的versicolor與virginica的樣本混雜在一起,結果相同,但降維後的視覺化比起先前所用的成對圖表,一目瞭然多了。 (6)降維化的資料作為演算法模型訓練數據 降維後的資料可直接拿來訓練演算法模型。例如我們用降維後的資料訓練一個Gaussian Naive Bayes演算法模型 from sklearn.naive_bayes import GaussianNB #匯入演算法類別 model = GaussianNB() #初始化模型 model.fit(X_lda, y) #用降維化資料訓練模型 (7)使用訓練後的資料預測目標類別 我們可將降維後的2維特徵子空間上的每一個網當作新數據,匯入訓練後的模型,即可得出第二張圖的藍色、橘色、綠色區塊,分別代表針對不同網格點預測其為setosa、versicolor或virginica何種品種,與藍色方塊、橘色叉叉、綠色圓圈這些實際資料比較,僅有少數的versicolor(橘色叉叉)或virginica(綠色圓圈)品種會被預測錯誤,模型預測成效還不錯。 |
|
| ( 知識學習|其他 ) |