字體:小 中 大
字體:小 中 大 |
|
|
|
| 2020/04/19 16:59:37瀏覽3151|回應0|推薦7 | |
Python機器學習筆記(九):準備平時考 - 將數據集區分為訓練用與測試用,以便對模型訓練成效做驗證 建構演算法模型的目的,是希望經由對現有資料的分析了解,能對未來「還沒看過」的資料進行精準的預測。但當我們對現有資料學習分析老半天後,我們要如何知道當前的學習成效好不好?想像對「還沒看過」的資料進行預測分析,就像一場期末大考,為求能高分通過期末考試,在大考前,我們需安排些平時考來驗收學習成效,將數據集區分為訓練用與測試用,是對演算法進行平時考的方法之一。 將數據集區分為訓練用與測試用,其背後想法很簡單,先將數據集分為二組資料,演算法模型只能「看到」訓練用資料,並藉此得到學習結果,最後再將先前「還沒看過」的測試資料的「特徵項目」餵給學習後的演算法模型看,藉此推導出「預測類別標籤」,再將「預測類別標籤」與測試用資料的「實際類別標籤」作比較,若「預測類別標籤」猜中「實際類別標籤」的比例愈高,就表示演算法模型的學習成效愈好,好比平時考得到比較好的成績。 為方便以下說明,假設X為我們要拿來分析的數據集的「特徵項目」矩陣(如「性別」、「年齡」「上月消費金額」等資訊),y為「類別標籤」向量(如是否會購買促銷商品),假設資料集僅有A、B二種類別標籤,A與B之間的數量比例為4:6。 一、僅考一次平時考:使用train_test_split類別,以及演算法模型評估器的score方法 scikit-learn中model_selection子模組的train_test_split類別函數,可以很方便地將數據集隨機劃分為訓練數據集與測試數據集。訓練數據集的「特徵項目」,我們設為X_train,「類別標籤」為y_train。相對地,X_test及y_test,則分別是測試數據集的「特徵項目」及「類別標籤」。 scikit-learn實作的演算法評估器,在叫用fit方法,利用訓練數據集的「特徵項目」X_train及「類別標籤」y_train資料訓練完後,可利用scoret方法,餵給它測試數據集的「特徵項目」X_test,以此產生預測的「類別標籤」資料y_pred,而預測出的y_pred再與測試數據集的實際「類別標籤」y_test做比對,計算出演算法模型預測正確的比率。 1.匯入train_test_split類別 from sklearn.model_selection import train_test_split 2.將資料集劃分為訓練數據集(X_train、y_train)及測試數據集(X_test、y_test) X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, stratify=y ) (1) test_size參數是設定要從數據集裏隨機抽取多少比例的資料作為測試數據集。設test_size=0.2,表示抽取20%的數據集資料作為測試數據集。 (2)參數stratify=y,可讓測試數據集的「類別標籤」A與B二者的比例,與整體數據集一致皆為4:6。 3.初始化一個訓練前的演算法模型 4.叫用fit方法,利用訓練數據集訓練演算法模型 訓練後演算法模型 = 訓練前演算法模型.fit( X_train, y_train ) 5.叫用score方法,利用測試數據集驗證演算法模型的預測成效 驗證分數 = 訓練後演算法模型.score( X_test, y_test ) 二、全面複習,並準備多次平時考:cross_val_score類別 第一種驗證模型方法有個缺點,即在模型訓練時少了一部份數據,以上面例子為例,因有20%的數據挪作為測試數據集,這些數據在訓練模型時沒有做出任何貢獻。為解決這個問題,可採用cross-validation方式,即執行一系列的數據分組訓練,數據集中的每個部份,都必須被當作訓練用及測試用數據集使用過。
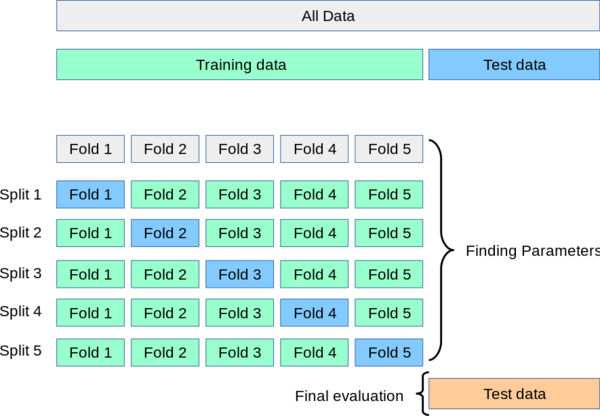
我們以圖一為例說明cross-validation,我們將數據集區分為fold1、fold2等至fold5這五組資料,而每一組資料的「類別標籤」的A與B的比例,與整體數據集都一樣是4:6。第一輪時,將事先分組好的fold1當作測試數據集,其餘四組則作為訓練數據集,利用與第一種方式相同的程序,可得出第一輪的驗證分數。第二輪時,則改以fold2為測試數據集,其他四組則是訓練用數據集,同樣可得出第二輪的驗證分數。依同樣方式處理,可依序得出第三、第四及第五輪的驗證分數,這樣我們就有個整體性的輪廓來評估演算法模型的訓練成效。 1.匯入cross_val_score類別 from sklearn.model_selection import cross_val_score 2.數據集分組、訓練演算法模型及評估訓練結果,一氣呵成 5輪驗證分數 = cross_val_score( 訓練前演算法模型, X, y, cv=5 ) (1)cv=5的參數設定,是指定將數據集分為5組,並進行5輪的模型成效驗證。 |
|
| ( 知識學習|其他 ) |