字體:小 中 大
字體:小 中 大 |
|
|
|
| 2019/10/19 12:15:14瀏覽3014|回應0|推薦8 | |
<Python練習 時間序列資料清理>>
*練習資料集 資料集是個按小時,逐時紀錄某座義大利城市”溫度”等資料的"AirQualityUCI.csv"檔案(資料下載處:https://archive.ics.uci.edu/ml/datasets/air+quality).原始資料欄位及其前二筆資料明細如下: Date;Time;CO(GT);PT08.S1(CO);NMHC(GT);C6H6(GT);PT08.S2(NMHC);NOx(GT);PT08.S3(NOx);NO2(GT);PT08.S4(NO2);PT08.S5(O3);T;RH;AH;; 10/03/2004;18.00.00;2,6;1360;150;11,9;1046;166;1056;113;1692;1268;13,6;48,9;0,7578;; 10/03/2004;19.00.00;2;1292;112;9,4;955;103;1174;92;1559;972;13,3;47,7;0,7255;;
*匯入檔案 利用pandas套件的read_csv()函式,匯入檔案並轉為DataFrame物件,以下以df代表轉檔後的DataFrame物件
*審核資料內容 #利用DataFrame物件的info()函式,檢核資料筆數及各欄位的資料型態.此例的資料筆數共有9,471筆,每筆資料有17個欄位. #“Date”及”Time”這二個欄位,其資料型態為Object,所以”10/03/2004”及”18.00.00”等這類資料內容,外觀雖是日期或是時間形式,但卻會被電腦系統判讀為一般文字,而不是日期或是時間單位,所以無法將這些資料直接用來進行日期或是時間方面的操作及運算處理.
*資料清理 #新增一個資料型態為Timestamp的”DateTime”新欄位,並轉設定為整個資料集的索引鍵(index) =>“時間”,在時間序列分析上是個重要變數,沒有”時間”的存在,就無法進行時間序列分析.基於”時間”性質的重要性,pandas套件另針對”時間”資料,核配一個Timestamp資料型態.此外,因”時間”是個依序排列的連續概念,如將時間”設定為index,並以此依序排列資料集資料,則資料集就將是個”時間序列”資料集. =>處理方式: à首先利用Python原生字串(string)串接方法,將”Date”與”Time”欄位的內容串接成一個新字串,存入新增的”DateTime”欄位裏. >語法: df[‘DateTime’] = (df[‘Date’] + ‘ ‘ + df[‘Time’]) >如第一筆資料的”DateTime”欄位內容將成為: 2004-03-10 18:00:00 à其次,利用datetime.datetime.strptime()函式,將”DateTime”的內容資料型態,由字串(string)轉型為Timestamp >語法: df[DateTime] = df[DateTime].map(lambda x:datetime.datetime.strptime(x,%d/%m/%Y %H.%M.%S)) à最後,將’DateTime’的時間資料,設定為資料集的索引值(index) >語法: df.index = df[‘DateTime’]
#無內容資料(空值)之處理 =>有時分析的資料集並不完整,欄位內容殘缺不齊,這些不齊全的資料若不預做處理即直接拿來分析,將影響分析結果的正確性. à首先利用df.isnull().any()函式檢查,資料集中的各個欄位是否有空值情形存在. à如有空值存在,可利用索引值檢索方式,找出是那幾筆資料有空值. >語法:此例’Date’欄位有空值,用df[df[‘Date’].isnull()].index找出有空值的資料索引值.結果發現資料集的最後114筆資料為空值. à無內容資料之處理,主要有二種方式: >只要含有空值的資料,該筆資料整個刪除.但在做時間序列分析時,時間的連續性十分重要,需特別注意,在使用此種方法時,時間的連續性是否會被中斷 >填入指定數值替代空值.當刪除空值資料會影響到資料的時間連續性時,此法是較適當的處理方式.可選擇的替代指定數值有: >>平均數 >>前一時間點的有效值 >>後一時間點的有效值 >因本例是資料集中最後114筆資料為空值,將這些資料刪除,並不會影響到資料集的時間連續性,故當資料含有空值時,直接刪除 >>語法: df = df[df[‘Date’].notnull()]
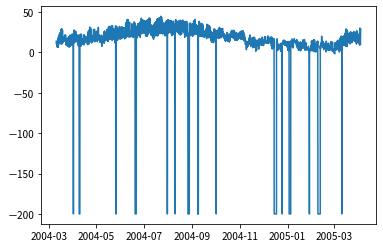
#不正常極端數值的處理 =>資料集是否有不正常的極端值存在,將資料視覺化是最簡單的初步檢驗方式.圖一為該座義大利城市的溫度曲線圖,我們發現一個不尋常現象:在某些時間點,溫度為零下200度!!這是在義大利,不是在火星表面!所以這應是儀器故障時所傳送的錯誤數據,應予矯正,才不會影響到後續分析結果.
=>矯正不正常極端數值,除了一個一個用眼睛看找出來之外,也可藉由數據一般正常情形下的分佈特性,使用數據處理技巧來找出這些不正常的數值.在此引入四分位級距法(interquartile range, IQR). 其處理步驟為: à第一步,找出原始資料集的25%位數(Q1)及75%位數(Q3) >語法: Q1 = numpy.percentile(df[‘T’],25), Q3 = numpy.percentile(df[‘T’],75) à第二步,計算出極端數值邊界區間(outlier step),為75%位數(Q3)與25%位數(Q1)二者間之差的1.5倍 >outlier step = (Q3 – Q1) * 1.5 à第三步,分別算出上極端臨界值,及下極端臨界值.數值落在上下極端臨界值之間,視為正常數值,若高於上極端臨界值,或低於下極端臨界值,則視為不正常數值. >上極端臨界值: upper = Q3 + outlier step >下極端臨界值: lower = Q1 – outlier step à第四步,找出落在上下極端臨界值之外的不正常資料 >利用df.query(‘T>upper數值 | T數值’).index語法,找出是那幾天的資料不正常 à第五步,矯正不正常資料 >因原始資料集是按每小時紀錄的,每小時間的數值變化不至過於劇烈,因此將這些不正常的數值替換成前一小時的正常值,與實際情形應不會相差太遠 >>第1步,先將找出來的不正常數值換成空值(NaN) >>第2步,再將空值換上前一小時正常數值 >>>語法: df.fillna(method=’ffill’)
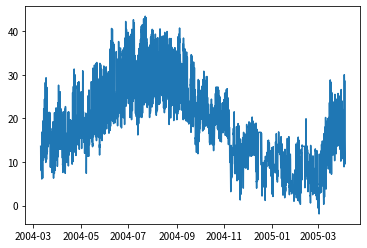
*繪製清理後的資料集如圖二,此時圖形看起來正常多了
|
|
| ( 知識學習|其他 ) |