字體:小 中 大
字體:小 中 大 |
|
|
|
| 2019/10/06 23:08:00瀏覽1178|回應0|推薦6 | |
<>台鐵車站分類>>
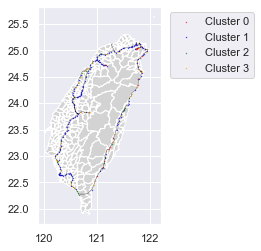
*練習緣由 以圖一地圖視覺化形式,按台鐵各車站營運情形,進行分類概況分析
*練習過程 #資料蒐集 #車站營運分類指標 #資料整理 #分類模型及資料學習 #分析結果視覺化
#資料蒐集 >資料來源為政府Open Data平台上的台鐵”每日各站進出站人數”JSON格式檔案,下載當時的資料期間為今年的4/23~8/31. >資料內容有 . 進站人數(gateInComingCnt) . 出站人數(gateOutGoingCnt) . 車站代碼(staCode) . 日期(trnOpDate)
#車站營運分類指標 嘗試以各站進出人數為基準,按以下二個面向,作為車站的分類指標 >車站各月進出站人數的波動程度 >最近進出站人數趨勢 人數是增加還是減少?其增減幅度是高或低?
#資料整理 >利用pandas套件的read_json()函式讀入資料檔案並轉為DataFrame物件 >利用DataFrame.groupby()函式,求出今年5~8月,各車站各月的總進出站人數之和 >計算車站各月進出站人數的波動程度 . 利用DataFrame.mean()函式計算出5~8月各站每月進出站人數的”平均數” . 利用DataFrame.std()函式計算出5~8月各站每月進出站人數的”標準差” . 車站進出站人數波動程度 = (標準值 / 平均數) >最近進出站人數趨勢 各站今年8月進出站人數,與其5~8月”平均數”的差異幅度
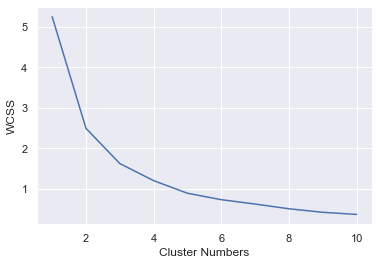
#分類模型及資料學習 >本次練習以k-平均集群法(k-means clustering)為分類模型 >分類群組數目問題 . 既然是對車站進行分類,那麼要對分析對象分成幾類群組,是進行此類分析時的最基本問題.但k-平均集群法,分類群組是個事先設定的外生變數,它沒辦法從資料中自身內生求出最佳群組數目. . 我們可利用所謂的手肘法則(elbow method)來決定分類群組數目.因k-平均集群法的原理是最小化各群組內的變異加總(total within-cluster sum of squqre,wcss).我們可將群組數目由2依序遞增至10,分別算出不同群組數目下的群內wcss,其結果我們可畫出如圖二類似手肘的曲線圖,橫軸為群組數目,縱軸為wcss.隨著群組數目增加,wcss一路遞減,但群組數目並不是愈多愈好,因分類群組太多,會有資料模型過度擬合(overfitting)問題,我們將以圖二曲線彎曲處所對應的群組數目,即各群內wcss值趨於收斂的轉折點,作為最佳的分群數目,此例我們選擇分類群組數目為4.
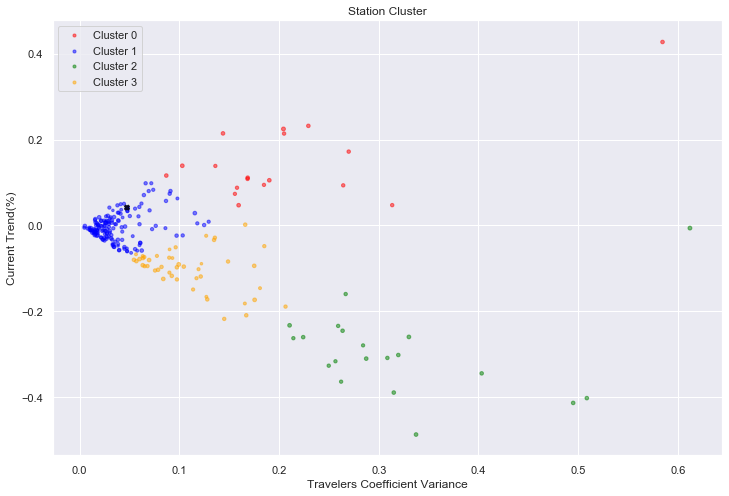
>群組數目為4情形下的k-平均集群法的分類結果如圖三,橫軸代表各車站進出站人數的波動大小,縱軸代表最近人數增減幅度,分組結果以不同顏色代表: . 紅色點為cluster 0 ,其人數波動幅度偏高,且近期人數在增加中 . 藍色點為cluster 1,其人數波動幅度不大,且近期人數增減幅度小.大多數的車站都被歸類為cluser1,台北車站(圖三中的x點)也是屬cluster1 . 綠色點為cluster2,其人數波動幅度及近期人數減幅,二者皆大 . 橘色點為clustter3,其近期人數雖同cluster2一樣呈減少之勢,但其波動及減幅比cluster2低.
>從分類結果來看,我們對cluster0(進出站人數明顯變多)及cluster2(進出站人數明顯變少)比較感興趣 . cluster0中,近期人數增幅的前五名車站: 海科館(深澳線),合興(內灣線),新馬(北廻線),富里(花東線),太麻里(南廻線) . cluster2中,近期人數減幅的前五名車站:加祿(南廻線),長榮大學(沙崙線),八斗子(深澳線),崁頂(屏東線),平和(花東線) . 我們發現cluster0及cluster2, 近期人數增幅或減幅前五名的車站,都不在西部主幹線路線上
#分析結果視覺化 我們按下列順序,依序堆疊畫出地理資訊視覺效果,結果如圖一 >台灣地圖 . 從政府Open Data平台下載台灣地圖shp檔, 並利用geopanda套件的read_file()函式讀入shp檔並轉為GeoDataFrame物件 . 原台灣地圖的經緯度範圍,包含金門,馬祖,太平島,釣魚台等離島,利用GeoDataFrame.drop()函式將這些離島經緯度範圍刪除 . 利用matplotlib.pyplot模組畫出台灣地圖 >台鐵路網圖 . 從政府Open Data平台下載台鐵路網圖shp檔, 並利用geopanda套件的read_file()函式讀入shp檔並轉為GeoDataFrame物件 . 利用matplotlib.pyplot模組,將台鐵路網圖套在台灣地圖上 >車站分類視覺效果 . 從政府Open Data平台下載台鐵的”車站基本資料集”JSON格式檔案 . 利用pandas套件的read_json()函式讀入車站資料檔案並轉為DataFrame物件 . 利用geopandas.GeoDataFrame()函式,將車站的DataFrame物件轉為GeoDataFrame物件 . 利用matplotlib.pyplot模組,將分類後的車站結果畫在台鐵路網圖上 - 紅色點代表分類為cluster0車站 - 藍色點代表分類為cluste1車站 - 綠色點代表分類為cluster2車站 - 橘色點代表分類為cluster3車站
|
|
| ( 知識學習|其他 ) |