字體:小 中 大
字體:小 中 大 |
|
|
|
| 2019/09/08 10:50:37瀏覽1369|回應0|推薦9 | |
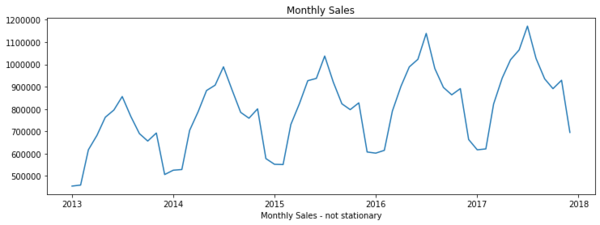
《Python練習 時間序列預測問題》 對時間序列資料的預測,是數據分析重要領域之一,大至國家明年經濟數據表現,小至公司下季營收、某張股票未來走勢,這類時間序列數據都是人們所關心的。過去在學校也有學些關於時間序列分析的東西,但早都還給老師了,最近因在摸些Python數據分析的東西,又再從腦袋瓜裏將這些遺失的記憶片段抓出來重新拼圖組合。 Barış Karaman在網路上的教學資料(連結網址:https://towardsdatascience.com/data-driven-growth-with-python-part-1-know-your-metrics-812781e66a5b),有個預測公司未來銷售營收的時間序列例子,使用的資料集雖是人工數據而非真實資料,但也藉此說明了一些在時間序列資料處理上的重要觀念。 (1)資料的穩定性(stationary) 時間序列分析的基礎,是從過去的歷史資料中,找出相關內部因素之間的關聯性,故如何從資料中剔除所謂「噪音」這類無關因素的干擾,以求得資料的「穩定性」,是個重要課題。資料是否具備「穩定性」,變異數是個重要衡量指標,若變異數不會隨著時間上下波動,而是穩定形態,則這個資料就是「穩定」的。
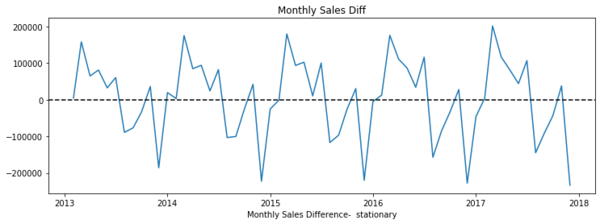
附圖一,為依據Barış Karaman資料集所畫出的每月營收線條圖,從圖中可明顯看出,整體營收趨勢是緩步向上的,因變異隨時間擴大,從資料結構來看,這個資料是「不穩定」的,在對資料進一步分析前,需對資料做「穩定化」處理。 「穩定化」處理,視資料趨勢形態的不同,而有不同的處理方式。Barış Karaman的這個例子,其「穩定化」處理是改為觀察每月營收的增減數字,而非實際營收數字,從附圖二可看出,這時資料趨勢已沒再隨時間改變,可見此時資料已具備「穩定性」,這時我們已完成「穩定化」處理作業。
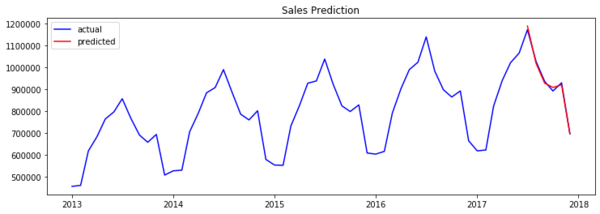
(2)影響變數(特徵)的「尺規化」(scaling)。 各個資料特徵,因其衡量單位的差異,在絕對數值上可能有極大的變化,如某些特徵以百萬為單位,而有些特徵卻以小數點為單位,如此天壤之別的落差,不僅增加計算各特徵之間關聯性的困難度,而各特徵的影響度,也極易受到單位尺度不同的扭曲而錯誤判讀。 解決之道也蠻簡單的,即將各特徵的數值範圍予以標準尺規化,例如無論特徵原始數值之間差異大小,一律將其轉換為(-1 ~ 1)的尺規區間數值內,以統一的尺規尺度衡量各特徵的影響力。 時間序列資料經相關程序處理後,始可就調整後的資料進行分析學習。作者Barış Karaman採用的是深度學習(deep learning)其中一支遞歸神經網路(Recurrent Neural Network, RNN)的長短期記憶(Long Short Term Memory, LSTM )模型,這些東西對我而言有如有字天書,我粗淺的了解,是模型每一次(層,layer)學習,會將前面學習到的經驗,以不同的權重(weight)加入下一層,也就是說,此次學習的結果,不只受上一次學習結果影響,也會受再上一次學習結果影響。Barış Karaman範例的模型學習結果成效不錯,第三張附圖右端的紅線部份,為模型學習後的預測值,幾乎與實際數值的藍線重疊。
|
|
| ( 知識學習|其他 ) |