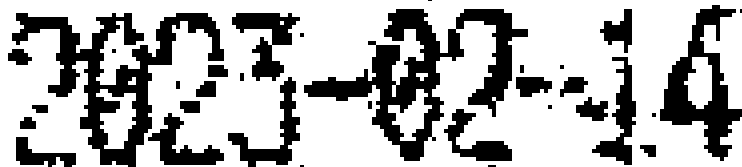字體:小 中 大
字體:小 中 大 |
|
|
|
| 2024/06/26 09:22:24瀏覽384|回應0|推薦4 | |
這種模糊程度其實就是考驗辨識軟體與人類智慧的差距最好的測試了!重點就是分辨出略為暗沉的字元前景,與略微亮白的背景了!差距很小但是人眼可以看得出來,如何用演算法來精準切割,複製人眼人腦的判斷就是大學問了!如果你用影像軟體分析這張影像的灰階分布柱狀圖大概是這樣的:
如果你手動決定字元前景與背景的門檻,就是用PhotoShop軟體的「臨界值」介面調整,最理想時可以做到下圖的程度:
雖然還是有點髒兮兮的,但是看來用CNN模式掃描應該不會辨識不出來了!可是要用程式計算自動做到這種程度的二值化是非常困難的!所謂差之毫釐失之千里!只要門檻值高幾個灰階就會黑成一坨,低幾個灰階就會破碎不堪到難以辨識了!而且整張發票的不同區域墨水也會濃淡不一,全圖統計的單一門檻值不會處處適用!我花在如何決定最佳門檻的研發時間是很長很關鍵的! 有趣的部分是:我們用眼睛看原圖時就會很快決定出一個很合理正確的黑白門檻值,對一般人來說這是很簡單的事情!加上我們的腦袋很聰明會自動將鄰近的點視為相連,即使這些數字是斷斷續續續的黑點我們也可以輕鬆視為連續筆畫認出字來!我們這些做AI軟體的人,最大的挑戰就是如何用已知的數學演算法做到跟一般人一樣的識字智慧! 連連看的部分就是使用CNN的特徵矩陣去掃描了!我們會假設一個字的概略大小,用標準字模去比對,如果某位置與某字符合度最高,周圍也沒有更高分的答案,就是辨識到了!但是CNN要掃描的底圖如何來呢?你當然可以直接用原圖的RGB或灰階圖,但運算量會太大!所以先簡化成黑白圖通常是必須的! 此時就回到要思考人眼人腦是如何決定黑白亮度門檻的智慧了!就是以前面的灰階分布資料為基礎,想出一個公式算出最理想的那個門檻值!如果不同的人眼都可以很一致的決定出一樣的門檻,那表示一定有共通的穩定邏輯,一定可以找到公式計算出那個大家都會直覺認定的門檻值的! 其實傳統的影像處理的書上都有很多可用的公式可以參考,但是現在大家都被機器學習的模糊思考哲學所迷惑中毒了!以為那些數學理論已經不重要了?但是那些學問當然很重要!很多事情即使真的可以讓機器摸索學會,但是如果你能充分掌握理論精華,就可以只用極少的時間與資料做到一樣或更精準的辨識! 所以最好的影像辨識是不分門派善用所有已知知識與資訊的整合性技術!絕對不要被現在的那些AI宣傳誤導了!重點一定不是機器學習、深度學習、類神經網路、Python或OpenCV之類的特定技術,而是必須深入理解科學、也願意相信你的常識甚至直覺!只要搞清楚發生的事情,自然可以想到解決的方法!老是迷信機器學習喜歡做盲人騎瞎馬呢?那你就慢慢走,我不等你了! |
|
| ( 心情隨筆|工作職場 ) |