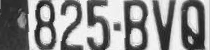字體:小 中 大
字體:小 中 大 |
|
|
|
| 2024/03/28 07:38:42瀏覽641|回應0|推薦6 | |
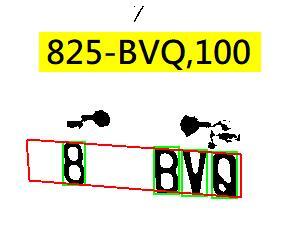
這個看似平凡的車牌辨識案例,在我的車牌辨識軟體中,其實是一個相當困難的推理過程!但實際需要的運算量卻很低,所以辨識時間只需要不可思議的31毫秒!就是0.031秒的意思!這就是我追求的人工「智慧」了!我要盡量用最「聰明」的演算過程達到我的辨識目的!答案正確只是基本要求,用最精簡的運算,做出速度最快又不會燃燒電腦的環保產品才是我的終極目標! 同樣的案例我估計使用流行的AI技術,就是機器學習(ML)、深度學習(DL),與類神經網路(CNN)的團隊應該也可以辨識成功!按照CNN學派的想法與做法,只要字元存在,也沒有嚴重變形,就一定可以用Convolution的方式做地毯式掃描找出每一個字。這在理論上絕對沒錯!但是實踐的成本實在太高了! 好像警察辦案,如果證據顯示被謀殺的死者被埋在某座大公園時,你如果有無限的資源,為了破案能無所不用其極的話,就可以把整個公園都挖開翻過來,屍體一定會找到的!但是實務上當然沒有任何警方會這麼作,找屍體不值得浪費那麼多資源,而且一定還有很多可以多動腦筋、少用資源、也不會嚴重破壞環境的方法可以達到一樣的目的! 這就是我至今還是繼續使用OCR的影像辨識架構做車牌辨識的原因了!CNN總是宣稱你可以找到任何目標,但是沒有告訴你訓練與搜尋都要付出的極高運算成本,就是辨識時間或設備要求啦!這是一個演算法效率產生的根本問題,輝達的高運算晶片可以提高運算效率,但無法減少運算量,算是減災但不是根治!只有徹底精進演算法的效率才是釜底抽薪的進步之道! 相對於需要高運算量的CNN,使用OCR的傳統影像辨識方法,先做灰階→二值化切割出如下的獨立目標,則是不需要做類似CNN的矩陣掃描,非常快速就可以做到的事情,運算量不及CNN前處理Convolution程序的十分之一!簡單說,就是取得基礎辨識資訊的成本很低,速度又快又便宜啦!
但是這個案例就正好暴露出OCR的缺點!那張黑色的長條貼紙與25BV幾個字元距離實在太接近了!從物理上就幾乎看不出他們之間的分界線,即使我們用了很聰明的影像處理技巧,也只能勉強切割出獨立的B與V字元,所以我們初步得到的只是殘缺不全的車牌內容。 但是我們如果已經有足夠資訊確定這個字組「是個車牌」,就可以用很多推理技巧去嘗試拼湊答案了!譬如已知兩字元之間的空隙過大,就表示OCR的前處理可能在此處漏字了!那就回到原圖的相關位置,放棄OCR的目標切割過程,改用CNN的地毯式Convolution搜尋方式,把埋在地下的屍體直接挖出來吧!挖出來的車牌就像下圖了,原本因為與黑色標籤沾黏而被OCR忽略的2與5就清晰呈現出來了!
當然因為不太準確的猜測,車牌的字數不夠嘛!我們會假設前面也可能少字?所以多挖了一塊沒有屍體的空地!但是只要稍作檢驗推理,當然可以很容易排除那個實心的方塊不是一個字,根據這些資訊用程式加以邏輯組織判斷,答案就絕對是正確的825-BVD了!這些根據不完美的資料,依舊可以持續推理辦案,最終得到正確結果的過程,就是我認為合理的「AI」影像辨識了! 從這個具體而微的例子,我希望大家可以體會到:重點不只是任何商業化影像辨識產品都必須達到我們的需求!在可以達到辨識需要的前提下,成本也是非常重要的因素!完成整個辨識程序需要的運算量越大,就代表越浪費時間,或是你需要買更多昂貴的額外運算硬體,就是成本越高了! 所以先天上就需要過多運算量的ML、DL與CNN等技術,是不可能完全佔據AI影像辨識技術市場,甚至淘汰OCR等以精確物理科學為基礎的傳統技術的!除非我們的科技環境退化到再也沒人會使用基礎的科學技術去解決影像辨識的物理問題! 我想很快的,大家就會發現,即使那些所謂的AI團隊真的可以用CNN的方案解決很多影像辨識問題,但也一定會有類似我的這種公司團隊推出成本低很多,而且表現更精準更優秀的影像辨識軟體!讓這些狹義的AI產品很像沒有太必要擁有的千萬超跑,有錢人可以去買來玩,買來炫富,但是一般人還是可以只買平價的汽車、機車或腳踏車代步!一樣可以充分達到買車的用途! 換言之,他們說的AI技術對於影像辨識來說,其實根本不是唯一的選項!甚至不是最好的一種選擇?到時候大家就會更尊重我,和尊重真正的科學與智慧了!科學與AI當然都是值得尊敬與期待的理念,但AI技術絕對不只是ML、DL與CNN而已!自我設限的結果一定會付出高昂的代價!不管是對研發者或消費者來說都是如此的! |
|
| ( 心情隨筆|工作職場 ) |