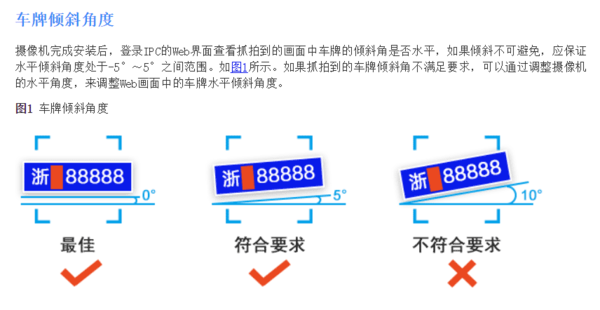
字體:小 中 大
字體:小 中 大 |
|
|
|
| 2019/02/11 09:17:47瀏覽3593|回應0|推薦7 | |
|
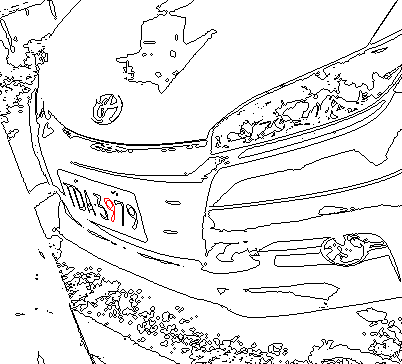
車牌辨識廠商都喜歡拿辨識率作廣告,我卻很不願意強調自己的辨識率?原因是我知道那種數據其實沒有太大意義。在一般廠商強調的「正常狀態」下,就是影像清晰、車牌傾斜極小,拍攝角度正面、車牌也沒有汙損時,我想大家的辨識率應該都是百分之百!如果這樣都還是有錯,那就是演算法有明顯漏洞或錯誤了,小修一下之後一定也是滿分的!一個大家都能考滿分的考試有意義嗎?頂多只是認證他們的基本能力而已。 真實世界需要的其實是「辨識能力」好的車牌辨識軟體,以目前市售的各家車牌辨識系統來看,「辨識能力」的最大需求是好軟體必須像我們的眼睛一樣,不必跑到車牌正前方就能辨識出車牌號碼!如上圖的狀況其實任何視力正常的人都能正確辨識車牌,但是如果拿來考各家車牌辨識產品,你猜有幾家能夠過關?沒用過相關產品的人可能不太確定,用過的都會說這種角度是:Impossible!譬如大陸知名的華為公司的車牌辨識系統就這麼跟客戶說:
但是我的標準版車牌辨識核心就是能不經任何設定調整,以正常的辨識流程與速度成功辨識這種歪斜程度的車牌!如上圖的例子是480X640,就是約30萬畫素的影像,使用i7電腦約50毫秒,也就是1/20秒就可以正確完成辨識!重點是:我不是用很多外加的處理程序,硬把這種困難車牌辨識出來的!否則就不可能這麼快! 如果沒有時間壓力,像是用錄影帶辨識搶案的車牌,用嘗試錯誤的演算法,假設車牌可能是各種變形狀態,算很久之後才把變形嚴重的車牌辨識出來,那是沒關係的!但一般需要及時反映的車牌辨識系統當然不能這麼作!我的辨識核心是先天就可以直接辨識變形車牌的,辨識速度和正面直視的車牌完全一樣! 這很稀奇嗎?真的很稀奇!如果任何廠商有類似的能力,絕對會拿出來大作廣告的!光是「別家廠商作不到」這個事實,就足以大幅提升公司的技術卓越形象了!但是我搜遍全球車牌辨識產品網頁,都還沒看過類似的展示,我的這種技術即使不是獨步全球,也一定是稀有動物了! 很多人會問:車牌辨識能力有必要做到這樣嗎?答案是:非常有必要!一個關鍵的環境因素是百萬畫素影像時代的來臨!以前的車牌辨識受限於攝影機畫素少,又必須看清楚車牌,所以車牌辨識都是在「特寫」的情況下作的!用於車牌辨識的影像都是近距離拍攝,車牌寬度可能就是整個影像的四或五分之一。像這樣:
這種情況下,主角就是車牌,當然不會刻意讓車牌拍得歪歪斜斜,在此辨識難度之下,人眼與軟體的辨識能力是差不多的!但是百萬畫素時代來臨後,一個蠻大的全景畫面中出現於畫面中任何位置的車牌,人眼都看得清楚,但是它們的視角就未必都很正面了!此時軟體辨識歪斜車牌的能力就會被拿來與人眼比較了!
像上圖這麼「簡單」的車牌辨識,如果你買的軟體無法辨識,多數人就會無法接受了!但實際上多數車牌辨識系統確實會無法辨識,廠商會說車牌角度「太斜」了!但在現實情境中,這是非常普通的視角,對於車牌辨識系統較「外行」的一般客戶來說,應該很難接受這種說詞的!這就是所有道路版車牌辨識廠商心中的痛點!除了我之外! 一般來說,我的標準版車牌辨識核心就能辨識到水平傾斜45度,上下左右斜視60度!所以我的車載車牌辨識軟體才能辨識率高達八九成,因為我的軟體「不挑食」!如果要等拍攝角度良好時才能辨識,整體辨識率就會少三成了!因為快速掃描路邊車牌的過程中,可能有一半以上的車牌,始終都沒有「理想」的辨識角度與距離。角度不好就放棄,成功率當然就低了! 為什麼我可以辨識這麼歪斜的車牌,別人卻很難呢?我不認為這是個商業機密,而是個學術上其實很簡單的辨識流程差異!截至目前,多數車牌辨識核心的設計中,為了節省運算時間,都是預設一個合理車牌大小的矩形遮罩,就是忽視車牌可能會傾斜或斜視的事實,去整個影像中找到車牌的!如下圖:
但是大家可以想像,如果車牌實際上就不是水平方向的矩形,怎麼可能正確鎖定真實車牌的邊界呢?如果連車牌位置都找不正確,辨識結果當然是錯的!甚至根本找不到「像是車牌的矩形區域」,第一關體檢就不合格,直接就放棄不辨識了!大多數的現有系統是放寬車牌搜尋條件,將稍微傾斜的車牌找到再想辦法微調的,請參考以下連結,但能處理的角度頂多十幾度。 https://blog.csdn.net/lcy597692327/article/details/79544628 https://wenku.baidu.com/view/36a9c1eb172ded630b1cb66a.html 那我是作了甚麼神奇的事情嗎?其實正好相反!我只是比較老實,按照OCR,也就是標準的光學字元辨識流程,將影像中的車牌「字元」一一找出,再將字元組成車牌,過程中我就可以發現字元排列是斜的,那就加以幾何校正嘛!就是旋轉,平移、縮放或投影之類的動作,看看下面兩張處理過程圖就懂了!
簡單說,我沒有真的發明了甚麼神奇的演算法?只是按照OCR的基本程序,先找字元再設法拼湊出字組,來定義精確的車牌區域!有了精確但不一定是水平向矩形的車牌區域,我只要作好幾何校正的演算法,即使因為視角偏斜的車牌就都能辨識了!上圖中位於下方的小車牌影像就是經過校正的,在此影像中切出來的字元影像就與標準字模非常接近了! 這些辨識流程我從來沒將它們當作商業機密,事實上我想其他真正深入研究車牌辨識核心的團隊也都知道!也都想按照這個流程(或其他更好的流程),製作出更為聰明的車牌辨識核心。他們都知道能辨識偏斜車牌的重要性,只是因為自己的技術還作不到,不願意提醒客戶它們產品的弱點而已! 我甚至預期上述流程終究會變成所有車辨核心都必須遵循模仿的標準流程!因為多數其他研究團隊嘗試過的辨識流程,我多半也都試過研究過,至少以矩形遮罩搜尋車牌的邏輯一定是個死胡同!永遠不可能正確鎖定任意偏斜車牌的位置,即使可以,演算時間的代價也會太大,就是「辨識很慢」的意思!我其實可以寫很多篇SCI論文闡述為何必須如此辨識的原因,只是我已經不是教授學者,無此必要而已! 我真正的商業機密其實只是如何完成上述OCR標準流程的一些速算技巧,以及過程中很多的例外補救處理。我不覺得講出這些處理流程會傷害到我的商業利益,因為我很清楚,遲早我的競爭對手都會發現我已經知道的這些事實!他們會掙扎的不是我的說法對不對?因為我已經用我的產品證明我是對的了!無庸置疑,我的產品就是鐵證! 他們感到壓力的應該是:難以放棄他們原來以「鎖定車牌」為起點的辨識核心技術與累積的經驗。要從頭開發以「字元辨識」為基礎的車牌辨識技術,至少需要好幾年!即使他們到終究必須走這條路,研發期間還是必須繼續銷售舊款辨識核心,舊的不是不能用!但是只能限定於較單純的情境,像是停車場等場所。如果是道路或手拍的使用情境,傳統核心真的會非常沒有競爭力! 所以聰明的車牌辨識客戶們!你們必須知道:車牌辨識的技術正面臨極大的升級轉型!新舊產品技術內涵的差距,有如傳統的按鍵手機與智慧型手機這麼大!用新的技術,辨識能力會與人眼判讀相差無幾。買到舊的產品呢?就是感覺它笨笨的,一定要在很多嚴格限制條件下才能正常辨識,你一定不會喜歡的!網路上對車牌辨識系統的怨聲載道,你聽到了嗎?還是問清楚看清楚之後再買吧! |
|
| ( 心情隨筆|工作職場 ) |