字體:小 中 大
字體:小 中 大 |
|
|
|
| 2014/02/17 10:15:05瀏覽2437|回應0|推薦13 | |
|
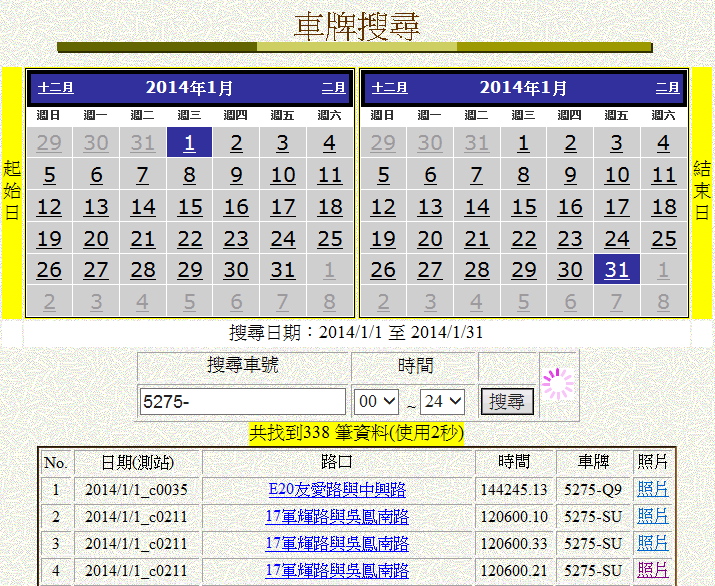
最近幾天一直忙著思考與測試各種可以讓車牌資料搜尋更快的技術。但是即使用到了上篇文章提到的平行運算,搜尋速度仍然沒有如預期一般大幅的提升!最終必須承認:究竟一台電腦上磁碟控制器與網路都只有一個,任何工作如果必須用到網路或磁碟時,即使程式軟體有分出很多個別的執行緒,但是它們碰到網路或磁碟動作時還是只能排隊!這樣是永遠快不起來的! 譬如原本我認為資料庫太大,切成小一點的資料庫,希望用多執行緒「分頭」同步搜尋應該會快很多。但是實際上速度只是略快個一成左右而已,並不是呈倍數變快的。此時忽然想到如果將資料先載入記憶體,搜尋時根本不必動磁碟(資料庫),而是在記憶體的資料陣列中找,那不是就可以充分的實現平行運算,每個執行緒都可以自己佔據一個CPU以及一塊記憶體,不必互相等著用磁碟機,不就可以很快了嗎? 昨晚開始逐步實現這個機制,先是將資料庫的資料簡化輸出為一般文字檔,方便程式把它們當作一般字串而非資料庫資料來處理。事實上兩個月的約兩千多萬筆資料,可以簡化成僅約500M的文字資料,伺服器電腦只需七秒鐘就可以將兩個月的資料讀進程式,因為記憶體高達8G,裝進這些資料非常輕鬆寫意。然後繼續套用多執行緒的搜尋架構,只是目標不再是磁碟機裡面的資料庫,而是記憶體裡面的文字陣列了! 結果就是這樣:搜尋一個月的資料(約一千萬筆)只需要兩秒鐘!兩個月就是五秒,還可以多人同時搜尋,也不會互相衝突,當然伺服器畢竟只有24核心,太多人同時搜還是會慢下來,但都只是幾個秒數的差別,和之前已經是數十倍的速差了!
非常有趣的結果是:人人都說資料庫的搜尋效率高,大量資料處理時非用資料庫不可!我現在卻因為無法跳脫資料庫必須放在磁碟的限制而受困,丟掉資料庫之後我反而海闊天空!問題通通解決了!這是極為詭異且巧妙的逆向思考,拋棄資料庫的功能,回歸到最基本的文數字處理,卻得到驚人的效果!如果想刻意耍帥,我真的可以使資料庫完全在這個系統中消失!而且運作得還更快更好! 其實這並不是靠著靈感或運氣成功的!事實上我前面這些年一直在處理非常龐大的聲納資料檔案,一個探勘航次的資料動輒數十G!那些檔案完全不依照一般資料庫的格式,又必須在合理時間之內讀取並處理,一個航次的資料如果要半小時來開啟檢視總是難以讓人忍受的!所以我花了很長的時間研究,對此類問題有豐富的經驗,也想出過非常多的撇步,極盡所能地讓大量資料能快速地被讀取與處理,而且還不能用一般的資料庫技法咧!中大的研究夥伴也常說:我的程式比多數國外聲納軟體的讀寫處理速度都更快!好神!其實方法是人想出來的,當你對電腦夠了解時,很多技法就會自動浮現了! 誰說離開學界到業界就不需要做研究了?我這裡是立誠電腦資訊公司「研發」部,不只要研究還要發明咧!哈哈!真的太太太太太太太太好玩了! |
|
| ( 心情隨筆|工作職場 ) |