字體:小 中 大
字體:小 中 大 |
|
|
|
| 2019/06/14 09:02:58瀏覽1403|回應0|推薦11 | |
說到模糊車牌的辨識,其實我的軟體還是遠遠不如人眼的!前文提到一個剛好點中我的死穴,看起來還算清楚,一般人都可以輕易判斷的車牌,我的軟體卻無法辨識的案例。但是同樣的一段影片中,有些看起來差不多模糊,甚至更模糊的車牌,我的軟體卻能辨識成功,如下圖:
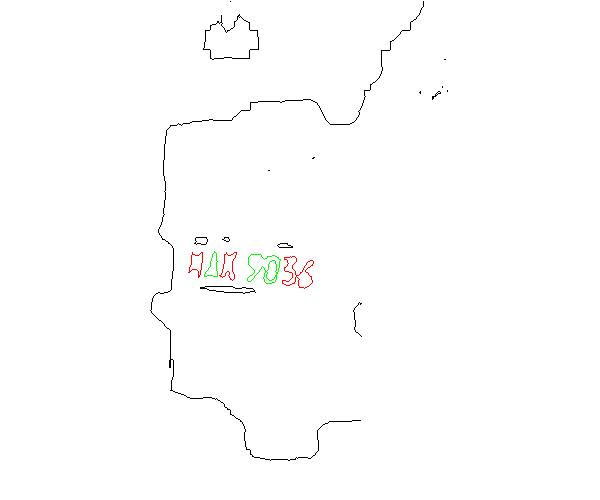
我刻意用不同的顏色顯示出其實七個字之中90與36是互相沾連的!但是我給了車牌字元搜尋組合時的容忍度,所以這五個其實包含了七個車牌字元的目標,還是可以被我的程式認定為一個車牌區域,不管原始大小如何,都投影成一個標準車牌該有的大小,就是所謂的正規化。再從這個子影像中設法一個字一個字的辨識出來,如下圖:
最左方的灰階車牌,表示我並不是從原圖的二值化影像中切割子影像的!而是切割且投影出原圖中車牌的灰階影像。就像我們的眼睛會先看全景找到車牌,鎖定車牌之後,會調整焦距「注視」這個車牌的小區域,更「用力」的去辨識個別的字元!其實就是取得一個新的,解析度與對比度可能都更高的影像。只是我們作影像辨識時只有一張影像,不能鎖定目標之後再Zoom In重拍,所以就只能局部放大繼續作影像處理囉! 我的更「用力」,就是用取得的正規化車牌灰階影像,再作一次更精準的二值化,這一次我考慮的條件就比較明確了!希望二值化之後會呈現大致固定寬度的幾個字元,我可以以此為目標調整二值化的門檻,譬如稍微降低門檻,試圖讓沾連的字分開,甚至因為我已經知道字元在此標準的車牌影像中應有的寬度了,就主動切開大約是兩個字寬的目標,看到二值化圖90中間的白線了嗎?就是我的程式切的! 當然畢竟這個車牌是比較模糊的,那個K沒被辨識成X我都覺得運氣很好,程式估計的符合(可靠)度只有78%,這種信賴度在停車場版本的軟體中是會直接被排除的!因為可信度太低了,勉強接受也可能有一兩字辨識錯誤,如果預期這個目標車牌一定有機會被拍得很清楚,這種爛資料就放生了吧!等車子靠近一點,車牌較清楚時再辨識一次。但是道路情境使用的軟體,不能預期這輛車子會有更好辨識的機會,就會加減用了!無魚蝦也好嘛! 把辨識過程寫得這麼清楚幹嘛?洩漏商業機密,不想繼續在這個業界混了嗎?確實有點風險,但是我忍不住想表達的理念是我思考解決影像辨識問題的方式,真的就是一路模仿與模擬人的思考過程!我很少看到別的專家學者以這種觀點提出對於影像辨識的討論,總是以數學方法掛帥,而非以物理現象為辨識方法的前提。 但是我堅持這種「傳統」的研究方式與方向好多年來,確實是相當順利,甚至可以說是勢如破竹!我完全沒用過「大家都在用」的OpenCV、機器學習、深度學習或邊緣運算等等時髦的技術,就可以作出很多高效率多樣化的影像辨識軟體,目前公司營運很順利。 我很希望大家知道影像辨識真的可以這麼作!只要搭配夠成熟的程式設計能力,誰都可以學我這樣作,這是一條確定走得通的道路!我自己也會繼續這樣走下去,直到我發現此路真的不通!或者那些主流派的觀點技術可以輕易地把我打趴,作出比我的軟體更聰明也更快速的軟體,讓我的東西真的賣不出去時為止! 就像生物多樣化的概念一樣,我不會想再去批評或比較我的方法與機器學習學派的差異優劣,重點是我的影像辨識理念「也是」可行的!如果有人剛好覺得想這樣作,或覺得應該這樣做,我希望我的例子可以鼓勵到一些人,學影像辨識與作影像辨識,並不是非從網路上說的那些技術或理念開始的!只要你懂得基本的物理、數學與程式技巧,以你自己的視覺智慧為師就可以開始了! |
|
| ( 心情隨筆|工作職場 ) |