

我的車牌辨識是以找到全景中的字元為主軸的,先找到一顆一顆的字元目標,再像打麻將一樣看看是不是像車牌字元一樣排成一排?這種邏輯程序已經很成功地成為我的車牌辨識產品核心。但這並不是車牌辨識演算法的主流,我認為我的方法很好,比主流派的更好!
但我也知道他山之石可以攻錯,主流派的演算法還是有些特性比我的方法更優秀,可以截長補短,所以最近有點時間就開始深入研究「傳統」的車牌辨識演算法了!所謂的主流派跟我的方法最大差異就是他們不是先找字元,而是先找「車牌」的!我在2013年就模仿實作過這個流程,我也看過很多相關論文,所以對這些程序並不陌生。
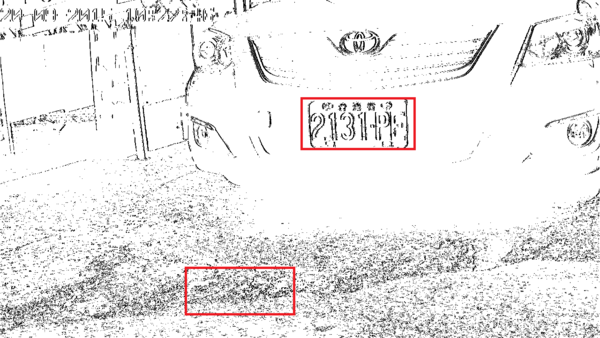
他們的辨識起點多半是某種高通濾波,先掃描篩選出圖上亮度對比較明顯的特徵點,通常是用所謂的Sobel Filter,如上圖。因為車牌原本就是設計成讓眼睛好辨識的,當然會亮度對比強烈,這樣一掃描車牌的字元一定會出現在特徵點中,但通常不會很完整得粒粒分明,所以他們接下來會用矩形的區塊遮罩掃描看看,有沒有一些形狀類似車牌的區域有很多特徵點集中。
其實要辨識車牌的重點,不是分析車牌有甚麼特徵?這件事太簡單了!重點應該是:車牌和環境中其他目標有何明確的差異?譬如用Sobel Filter分析後,如上圖的粗糙地面加上正午陽光,地面就是會出現很多高頻的雜訊,如何判斷圖上的兩個紅框,誰「比較像」是車牌呢?人眼當然不會看錯,但是你應該如何用數學描述:為什麼上面那個「比較像」車牌,下面的「比較不像」呢?都有很多特徵點啊?但是分布模式不一樣,請數學公式定量化這個分布型態的差異。
這就是我剛剛交代給RD的一項「工作」,之前研究時好幾次想到要建立這個判斷式,但這不是我的主要演算法所必須,所以沒認真做出來。我很確定一定有現成的數學方法模式可以套用,自己用常識去兜,或查書都可以找到並實作出這種演算法的!所以我會說這只是日常「工作」,而非甚麼了不起的「研究」!作出整個香港車牌辨識核心這種規模與難度,我才會稱之為「研究」!大部分頂大研究所所謂的「研究」,在我這裡都是例行工作而已。
這就是我對於「讀書研究影像辨識」的輕率(輕蔑)態度!如果你的腦袋裡滿腦子都是別人做過的方法論,反而很難保持清晰的常識與直覺,只會一個方法一個方法的套公式,耗時又不能確實掌握識真實狀況,一開始套公式你的理解程度就開始「跳步」了!好像用了一個黑盒子去解決問題,你就開始有一部份程序不知道自己在幹甚麼了!先清楚掌握物理現象與實際需求,再開始去想或找數學方法來準確的解決問題,這才是紮實的科學研究!
所以我常說:要作影像辨識,去讀研究所,學很多影像辨識法,真的不是一個好辦法!除非你的老師本身就是實務經驗很豐富,還很有問題解析能力的高手!不然只會越學越亂,還不如自己在家摸索學得更為踏實。這是真心話!我的公司曾經有位專攻影像辨識的台大電機碩士來上班,他知道的影像辨識方法比我還多,但即使我已經盡力協助,一年之後他還是無法獨立完成任何專案,最終我只能請他離開,可見知識多寡與解決問題的能力真的是完全的兩回事!




 字體:小 中 大
字體:小 中 大






