字體:小 中 大
字體:小 中 大 |
|
|
|
| 2018/04/12 05:47:18瀏覽2079|回應0|推薦8 | |
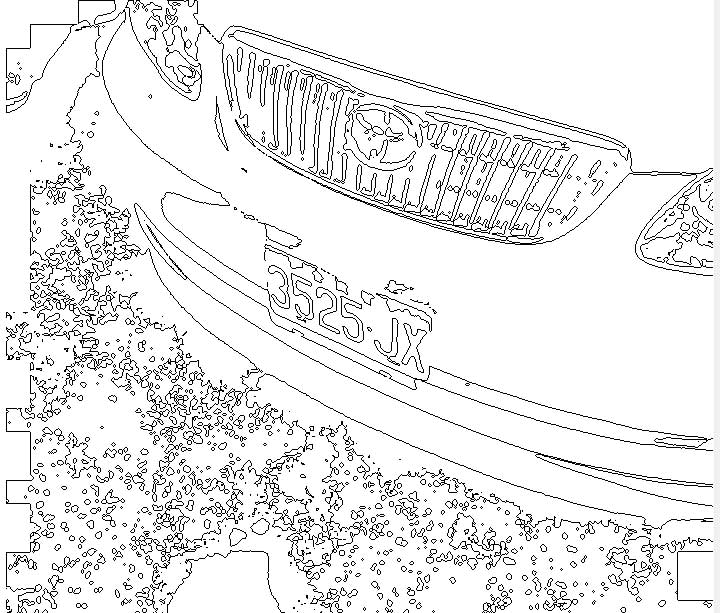
如我近來一再強調的,車牌辨識的技術已經進入:全景(實景)、多車、高畫素、動態的辨識競爭!以前要求車子一定要進到我的辨識框架與情境的時代過去了!車牌辨識的技術應該是去追逐實際的情境中任意方式經過攝影畫面的車子,希望用軟體適應車牌影像的「異常」,盡量增加辨識的容忍度與速度。總之,千萬別信「車牌辨識已經是很成熟的技術」這種鬼話!因為高畫素影像的普及,我們才剛剛開始研究人眼是如何在複雜環境中迅速辨識出車牌的智慧。 在這場全球性的軟體競賽中,我逐漸確認我的辨識技術主要優勢在於我的「不挑食」!對於拍攝角度歪斜的車牌影像我可以辨識的範圍很大,影像品質良好的前提下,左右或上(下)方偏離中軸線50度以內都確定可辨識,車牌水平線傾斜25度以內也都確定可以辨識!如果工程標案以此規格招標,應該會屍橫遍野的! 這是因為我「發明」了甚麼神奇的演算法嗎?其實不是的!我研究的路徑並不是跳脫傳統的框架,反而是堅持最基本的影像辨識邏輯,有點像愚公移山!多數人認為很難走得通的道路,譬如遇到高山,都是決定繞道而行,我只是嘗試看看能否真的穿山而過!如果可以克服山脈,鑽出一個隧道或找到尚可行走的山路,我就會比多數人更快到達目的地了! 傳統上影像辨識要找到特定的目標,就是彩色→灰階→二值化→取輪廓→定義目標→比對目標。在車牌辨識來說,「目標」當然應該是車牌上清晰的字元,所以在全景像中一一分析個別目標,找到像英數字的目標,然後看看是不是有像車牌一樣的排列特徵?這樣就可以找到車牌的字組進行字模比對辨識了! 但是這條路即使是四年前,我實作第一版商用車牌辨識核心時,也是走不通的!要這麼作,基本的方法論與演算法是可以建立的,我2009年就做到了!我也看到有過論文發表「以字元辨識為基礎的車牌辨識」,但是絕大多數的論文發表,或我由側面理解的商用車牌辨識核心都不是這麼做的!原因是實作這些程序(全景目標分析)的計算速度實在太慢了! 我真正的研發成就其實是讓這些理論上會比較好的「正常」影像辨識程序,以符合商用需求的速度實現!先說「不」這麼作的變通方式是甚麼?不直接找字元目標,那就是跳過個別目標直接找車牌「可能出現」的區塊了!俗話說就是「鎖定車牌」。這當然也不容易,但即使成功也只是切出一塊包含車牌的小影像,如果車牌本身是歪斜的,你又沒有字元的原始目標資訊的話,還是要處理半天的! 下面這張幾圖就可以看出在全景影像中「找字元」與「找車牌」的差異。
如果我是按照車牌的整體特性去搜尋車牌概略的位置,如多數已發表的車牌辨識演算法,那我應該會找到綠色框框範圍的子影像,面對歪斜車牌,我必須在子影像內再作完整的目標辨識,才能一一正確的辨識字元是甚麼?但是困難點不在這裡,而是當我在全圖「搜尋車牌可能位置」時,我如何知道框框應該放多大?框框的寬高比是多少?如果是正面拍攝的影像,車牌的寬高比是可以預期的矩形,但如上的狀況,程式如果沒有先作完整的全圖目標分析,如何事先知道車牌區域會變成「方形」呢? 我可以誠實告訴所有人,我是真的按照課本說的:先以輪廓特徵辨識出全圖所有可切割的獨立目標,排除極端大小形狀的目標後,再一一檢視是否有成排的字組特徵!車牌就是平行排列的一組字元嘛!其實這不是我的「發明」,根本就是一般人的腦袋本來就會這麼作的事情!我只是將這個思考程序程式化而已! 因為我是將已經很明確找到的目標加以排列,所以我可以精確地知道字組的邊緣(圖中紅色邊框所示),他們是矩形?梯形?菱形?或任意四邊形?對我來說並無差異,我都可以正確的投影成標準字模的「形狀」與大小!所以我的辨識極限是字元清楚與否?字元因為拍攝角度而變形,對我來說影響不大! 那我的商業機密是甚麼呢?就是實現這些模擬人為思考程序的數學與程式設計的技巧了!我認為有心人如果肯專心研究不會無法達到,說穿了也不過就是一些高中程度的幾何學,最多加上微積分的觀念罷了!我想分享表達的理念是:尊重真實世界的物理現象、堅持簡單直覺的想法,讓數學與程式為你的直覺與常識認知服務,不要讓人為「發明」的方法論演算法拉著走!你一定可以在影像辨識,甚至人工智慧的領域走得更遠! |
|
| ( 心情隨筆|工作職場 ) |