字體:小 中 大
字體:小 中 大 |
|
|
|
| 2024/01/12 05:56:57瀏覽450|回應0|推薦7 | |
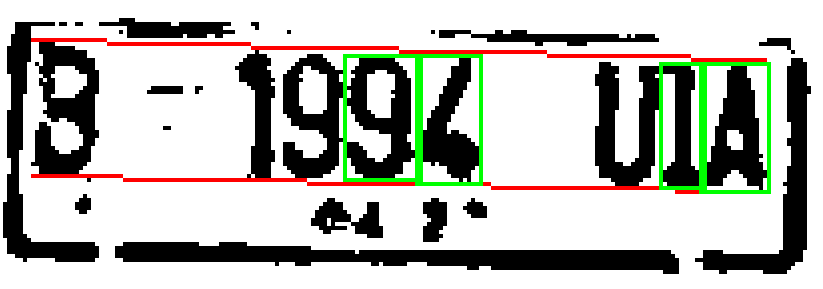
圖一 車牌字元沾連的二值化放大圖 這是一個很有趣的案例,說明了OCR(光學字元辨識)與CNN(類神經網路)這兩種影像辨識技術可以如何密切合作,非常有效率的解決了一個車牌辨識的難題!這個案例的辨識如果不能解決,對於我這種敢自稱AI影像辨識的專家,是難以承受之重!因為原圖如下,看來還算OK,一般人不會認為無法辨識的,如果我的軟體這樣就被擊敗的話就很糗了!
圖二 略模糊之車牌放大影像 如前文所述,用過或看過CNN展示的人都會覺得這個辨識並不「困難」,如果貓、狗或人形那些更模糊的目標都能鎖定,這些印刷字目標當然不可能辨識不到!但如果是要從下面的街景影像中找到這些字元呢?需要多大的運算量呢?不要被YouTubeT上的CNN展示迷惑了!人家是住豪宅開超跑的,你我根本花不起那個錢的!
圖三 街景情境之車牌辨識影像 簡單說,CNN就是一個現代版的「何不食肉糜?」的AI故事!能吃肉當然會飽,還能很健康強壯,但窮人是沒辦法天天吃大魚大肉的!沒有超規格的好電腦與額外的周邊軟硬體輔助,CNN技術根本是無法商品化普及化的!所以才會帶動那麼多AI晶片的產業蓬勃發展!但也暗示了CNN計算量大到不合理的缺點,如果你就是買不起更昂貴的AI電腦設備呢?就只能放棄研發或使用影像辨識嗎? 多數人不知道或沒注意到的重點是:對於影像辨識產業來說,在CNN根本還沒介入之前,車牌、指紋與人臉辨識等商業化產品早已行銷應用幾十年了!近幾年影像辨識應用的大爆發,主因是數位影像品質的提升與普及(降價),至今為止都是跟CNN還毫無關係的!即使CNN確實可以提升影像辨識能力的上限,但就像古時候的平民吃不起昂貴的肉,可是只要有米飯蔬菜吃也可以活下去的!只有那些愛慕虛榮傾家蕩產也要買肉吃的笨蛋才會餓死! 換言之,即使沒有CNN,影像辨識產業也不會就此停擺的!大家到底在急甚麼?為什麼必須急於拋棄傳統技術全面擁抱CNN?應該是研究如何將CNN的技術優點與傳統技術相結合吧?CNN即將帶來的成本暴增與環保危機有人看到嗎?不要只看到CNN的高運算量「缺點」帶來的硬體商機吧!硬體更多用電更多只會是環保的浩劫!你還嫌地球不夠熱,電子垃圾不夠多嗎? CNN技術在影像辨識中具體來說就是用特徵矩陣掃描搜尋目標的技術!目標特徵與位置大小越不確定,需要的掃描矩陣的複雜度與次數就越多!運算量當然也隨之暴增了!但是如果有其他方式可以降低CNN需要設計的特徵矩陣難度、減少掃描範圍與次數呢?如果我們只在特殊困難的小範圍限量使用CNN?其他地方繼續使用低運算量且高效率的OCR等傳統技術呢?
以這個車牌辨識的例子來說,OCR已經可以非常快速的做出圖一的結果,第一個B與第二個1字也能順利辨識出來了!問題出在994與UIA之間因為影像略為模糊就「藕斷絲連」地沾在一起了!如果我要繼續使用OCR的模式硬幹,就是要找到一些邏輯做連體嬰的切割手術了!在我熟悉CNN概念之前確實就是這麼作的!大部分情況下也行得通,不然我的台灣車牌是根本無法拿到道路上使用的!馬路上拍的影像車牌有沾連字元的比例可以高達三成的! 但是印尼車牌是不保證字寬相等的!上例中沾連的994三字概略等寬,我估計沾連目標寬度約3個字就切成三等份還OK。但是非常窄的I夾在U與A之間,我用寬度估計就會誤以為只有兩個字,於是二分法切出來的分割目標就等於把I字元直接分屍了!當然拿這兩個被錯誤切割的目標去比對字模就甚麼字都不像,這個辨識就功敗垂成,宣告GG了! 如果我導入CNN概念呢?要在小到像994或UIA沾連目標內的極小範圍內做CNN特徵掃描確認994與UIA等幾個字元,當然計算量就絕對不會太大!以上例來說全影像是1920 X 1080 = 207萬畫素,其中的車牌只有約200 x 50 = 1000畫素,是全圖面積的約兩千分之一!搜尋目標的時間(運算量)也是使用全套CNN的兩千分之一!不需要為此買昂貴的AI電腦的!這有點像我買不起億萬豪宅,但偶爾想奢華享受一下時,花個幾萬元去五星級大飯店租個頂級套房過癮一下,還不致傾家蕩產的! 所以我就是這麼作了!也很輕鬆穩定準確的用CNN的模式辨識出完整正確的答案!1920X1080的街景影像辨識時間還不到0.2秒!當然也不需要一般使用CNN時強調需要的特殊周邊軟硬體設備,我只是用CNN的原理概念寫必要的程式加入我的軟體而已!任何買我軟體的人都能享受這種CNN的高辨識能力,卻不必花錢買AI晶片!很酷吧? |
|
| ( 心情隨筆|工作職場 ) |