字體:小 中 大
字體:小 中 大 |
|
|
|
| 2020/03/14 10:33:34瀏覽978|回應0|推薦7 | |
Python機器學習筆記(四):不要拿英文課本在練習國文 - 搞懂學習對象,才能選對模型 沒想到練習Python,也能遇見台灣之光。在筆記(二)中提及的分類(classification)類型模型,其中有一種支援向量機(support vector machine,SVM),是一個被廣泛使用的機器學習演算法,而scikit-learn實作的SVM實例,其底層是由台灣大學團隊所開發的C/C++程式碼函式庫,台灣人好棒棒。在此我們先借用SVM模型來看一個最基本的問題:選模型前,先搞懂你要學什麼!
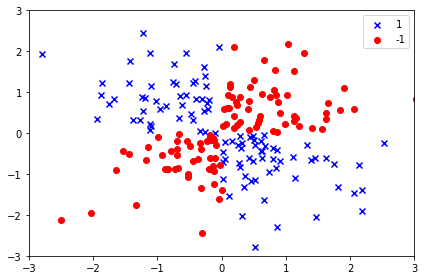
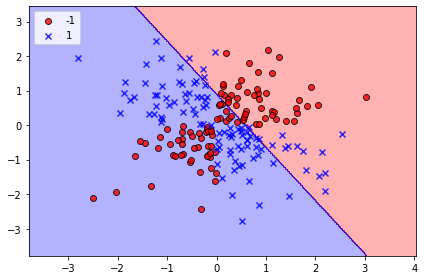
想像我們拿到一組如第一個圖的數據,圖中的O及X代表我們關心的二個類別標籤(如:買/不買),而O與X標籤結果受橫軸及縱軸這二個特徵值影響所決定(如:年齡/月收入),我們的目標,是希望利用現有資料訓練演算法模型後,當再餵給模型新資料(如一位新客戶),模型即能依據新資料的特徵值(年齡及月收入),正確判斷該筆資料類別標籤是屬於O或是X(會買還是不會買)。 假設我們從某個地方得知,SVM是個功能強大的分類演算法模型,並學到它的建模語法如下: SVC(kernel='linear') 接著我們就興致勃勃的將資料丟進SVM模型練習,最後我們得到的練習結果如第二個圖。
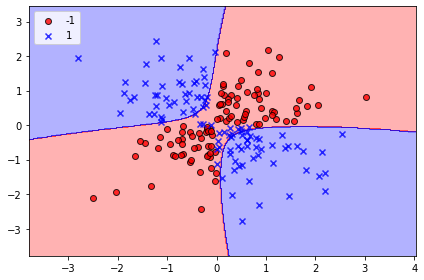
圖中藍色部份,是模型認為若資料落在這個區塊,其類別標籤應為X,但若是落在紅色區塊,類別標籤則為O。但將圖上紅色、藍色區塊與實際的O、X資料點比對,我們發現有許多X、O點是落在錯誤的區塊裏。由於模型對資料的分類結果錯的離譜,所以我們就得出SVM模型效能不佳的結論。 錯!錯!大錯特錯! 錯的不是SVM模型,而是我們不清楚我們在學什麼!我們不清楚要處理數據集的長相,更不清楚SVM是如何處理數據。我們再回頭看先前的SVM建模語法 SVC(kernel='linear') 其中參數kernel='linear'指的是,SVM在學習過程中會嘗試找出一條最適合的直線,將O、X資料點分隔開來。若我們回過頭看第一個圖,會發現O類資料點呈西南-東北趨勢分佈,X點則是西北-東南走向,雙方在中間地帶交錯。目測結果,不可能找到一條直線將O、X資料點分隔開來,此種類型資料,稱之為「非線性分離」數據,我們命令SVM針對「非線性分離」數據去找出一條直線來分割數據,結果當然是失敗的。但在發現這個原因後,我們就下個結論:SVM無法處理「非線性分離」數據。 錯!錯!大錯特錯! 事實上,SVM有其他模式來處理「非線性分離」數據,其中有種叫「徑向基底函數核」(Radial Basis Function kernel,RBF kernel),其建模語法如下: SVC(kernel='rbf')
第三個圖為此時模型學習後的成果,雖仍有小部份的X點落在錯誤的紅色區塊內,整體而言模型學習效能改善許多。 沒有一個演算法模型可以面對所有情境的問題,唯有真正了解手中要處理數據的長相,並知道不同演算法的各自特長及其限制,才有辦法選對模型。要練習國文時,要拿國文課本出來唸,而不是隨手拿本英文課本亂唸一通。 |
|
| ( 知識學習|其他 ) |