字體:小 中 大
字體:小 中 大 |
|
|
|
| 2016/04/15 03:02:47瀏覽1016|回應0|推薦5 | |
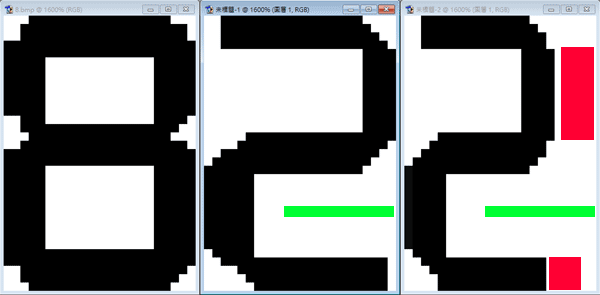
影像辨識錯誤只是一個結果,但辨識的流程有很多步驟,出錯的原因有很多種,讓辨識的「結果」變正確的方式也有很多種!如果沒有細心追查真正錯誤的原因加以修復,只是治標不治本,看起來問題是快速解決了,但無形中程式就變複雜了!多出來的「治標程式」對於發病的個案有幫助,卻可能對其他案例產生負面作用,所以如何正確的分析診斷每一個錯誤個案,找到出錯的真正原因對症下藥就非常重要了! 下面是昨天碰到的一個案例:
如上圖中間的「2」字居然經過我的程式比對會被誤認為「8」!雖然覺得有點奇怪,但是第一時間我想到的解法是在較模糊的車牌影像辨識時常用的特徵辨識法,如圖中的綠線段,2字的右下方是可以穿透的!8字就不行!所以加一個小小的診斷程式,看看右下部位是不是可以穿透?如果可以!就排除8的可能性,自然就不會出現離譜的結果8了! 我用這種治標的方式先完成了一個「不會錯」的程式,但是因為其實不知道為何如此清晰的影像也會出現離譜的錯誤,心有不甘就回頭仔細分析檢視整個2字的辨識流程,終於發現是我交代某員工製作的字模2做得太「瘦」了! 這也不能怪他,在這個案子,我們希望同時能辨識多種字型,其中兩種形狀相似但寬窄略有不同,我們不想多做一種字模,他只是選擇了其中較瘦的一種字型來製作字模,碰到較胖的2時就剛好右上方的紅色區域筆畫對不上了!如上圖右方所示。同時間另一款字模中的8字是寬度足夠的!如上圖左,他和中間胖胖的2筆畫符合度就會高於右邊瘦瘦的2了! 總之,這是因為字模建立得不夠精準,或者說代表性不夠。就像我們以紙片人模特兒的身材大量製作成衣,到市場上就不好賣了!因為多數人沒這麼瘦。相對的,如果以一個體型適中的人為範本製作的衣服,略微胖瘦的人加減都還穿得下。較為中庸的字模即使與實際的影像有落差也不會太大,還是可以得到辨識正確的結果,就是「雖不中亦不遠矣」的意思啦! 知道這個原因之後我就將右圖的2字字模稍微變寬一點點,這樣不論胖瘦的2字都可以通吃,不會再看錯成8了!最大的好處是程式碼立即減少數十行,辨識流程變得更簡單而穩定,大家後續的工作量也變少了! 這讓我想到自己治好膝傷的經驗,如同很多運動咖,到了三四十歲膝蓋都會有點傷,運動時會痠痛就綁上護膝,甚至吃止痛藥還讓西醫打過據說是類固醇的針劑!這些治標的方式讓我的運動裝備變多,多花錢多麻煩其實也沒有真正解決問題。後來我經過練氣功靜坐加上一些傳統的推拿拔罐治療,膝蓋的傷真的好了!就不用再吃藥打針,也不必用護具繼續打籃球到現在,雖然跑跳的高度速度不能回春,但是真的完全不痛了! 有趣吧?這也讓我想到教育的問題,表面上不乖不合作的學生只是一個結果,立即的處罰「矯正」好像有效,其實沒有真正解決問題。又如考試,好像讓學生在短時間之內達到一定的規格,其實超出題庫的範圍那些學到的解題技巧就沒用處了!問題其實一直擺在那邊,也可以解決,就看你是不是真的願意認真的面對它!還是只求立即止痛,短線操作? 我願意不厭其煩的研究影像辨識的每一個細節,不滿足於使用既有的工具程式模組,每一行程式都堅持一定要自己寫,原因就是希望可以完全掌握問題,也可以找到最佳化最適切的問題解決方式,這才叫做研發嘛!不是嗎? |
|
| ( 心情隨筆|工作職場 ) |