字體:小 中 大
字體:小 中 大 |
|
|
|
| 2016/04/07 06:22:26瀏覽2120|回應1|推薦13 | |
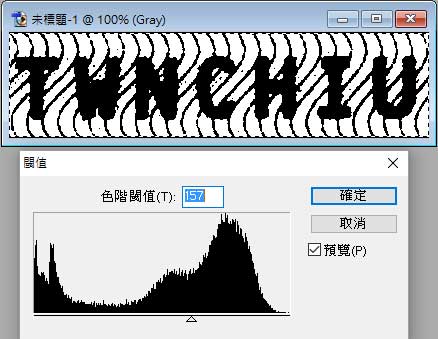
影像辨識的流程很複雜,一般業界公司只希望大家都相信他們擁有不必質疑的「九陰真經」或「九陽神功」,很少願意談他們的研發內容。但我相信即使是全世界最先進的影像辨識公司,他們內部一定還是不斷的在研究精進的!完美的終極武功應該永遠不會真的出現!我的日常生活就是不斷的在研究這些東西,我也不願意搞神祕,就原則性的聊聊這些「常識」吧!我可不是影像辨識的「代理」商,手上只有國外弄來的神秘藥方,那種公司除了強調辨識率之外就沒話可聊了!就別難為他們囉! 影像辨識流程的前半段大致上是:全彩影像→灰階化(變成0-255階的亮度值)→黑白(變成0與1的值)。所謂的二值化就是依據灰階圖的亮度分布,找一個最洽當的亮度門檻值,在此以上的定義為白色,以下的為黑色,這樣我們想要辨識的字元就會黑白分明的呈現出來了!但是有多麼「黑白分明」學問就大了!
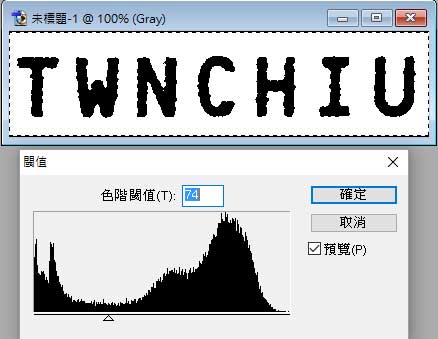
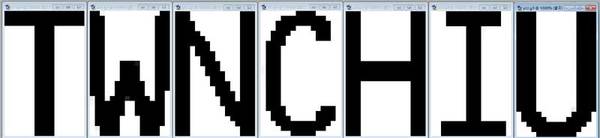
如上圖,如果是在單一圖片用影像軟體處理時,我們一定可以調整到那幾個字元變得非常清晰!但是如果這些動作都要程式化,讓每一張狀況都不同的照片經過我的程式都有一樣的結果,字元都變得很清晰,筆畫的胖瘦還都要差不多!這就很難了!我至今都還常常在實驗調整,希望有更好更適合我的各種辨識影像的二值化演算法。 有了清楚的黑白影像,下一步就是讓它們縮放到我們設計好的字模大小,然後比對符合度,譬如針對上述影像我設計的幾個字元模型是這樣的:
可以看出來理想與現實是有落差的!要讓每個字元黑白色的比對百分百正確不太可能,所以就是比較誰的符合度較高啦!但是如果碰到”B”與”8”,或”0”與”D”,甚至數字”0”與字母”O”!等等…。可以預期符合度相差會很少,此時只要黑白二值化的步驟做得不是很精準,辨識結果就會很不穩定了!B會看成8或D會看成0等等! 上面的例子還算是清楚的,二值化作成這樣是常有的事:
如果完全要靠比對符合度來判斷,錯誤率真的很高!所以這時通常需要「吃藥」!就是使用一些字元的特徵來輔助辨識,譬如”K”的上方是有”洞”的!類似的字元”R”就沒有!大家可以想一想”N”和”H”也很像,我們該看甚麼特徵來分辨這兩個字呢?想出了特徵之後,就是設法推導出對應的數學公式,然後寫成程式,譬如發現字元上方有洞,就讓”K”字得到多一點點加權分數,”R”就要扣分了!等等… 這些輔助辨識機制看起來很聰明,但是就像人吃藥一樣,副作用其實是很難控制的!不需要吃藥的字元吃了藥反而會「走鐘」,變成異常的辨識失敗!所以我通常叫它們是「違章建築」!需要時可以立即頂樓加蓋就多出一間房間,但是潛在的安全危機可能在下次地震或颱風時爆發出來,能夠不用就不用!即使要用,加權分數也不能下得太猛,很像醫界會慎用抗生素吧? 為了能在限時之內完成辨識核心程式,我當然是能用的招數都會用上,也多半可以在「外觀」上作出辨識率很高的產品。但是只要行有餘力,我會不斷地回頭重新研究每一個變識流程!方向就是將二值化做得更精準,將字模調整得更接近二值化的結果,希望能不用「吃藥」,也就是少用額外的加權分數機制,直接以清晰的影像及正確的字模比對,就得到穩定而且正確的結果。 所以更精準聰明的二值化演算法,加上目標位置的正確鎖定,我稱之為「培元固本」「強身健體」,使用特徵加權辨識就是吃藥打針了!辨識流程一如人體,外觀的健康是一回事,那些職業選手是不是靠吃禁藥變強壯的?我們真的不知道!我們自己要養生當然是多運動少吃藥比較好! |
|
| ( 心情隨筆|工作職場 ) |