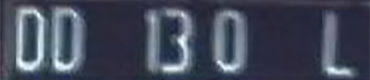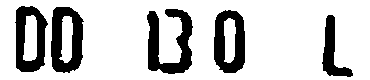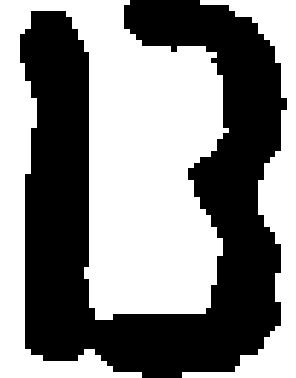字體:小 中 大
字體:小 中 大 |
|
|
|
| 2024/02/21 05:46:29瀏覽657|回應0|推薦6 | |
我的車牌辨識是以OCR(光學字元辨是)技術為基礎的,我也幾乎天天批評ML與CNN等技術在影像辨識領域被過度高估了!但絕對不是說它們完全沒用,或是說OCR永遠可以比CNN聰明?任何技術方法會出現並存在一定是各有所長的!務實的科學家或RD都應該善用所有的技術讓自己的研究更好!我也是一直這麼在努力的! 所以自從深入研究ML與CNN等新技術之後,我無時無刻不在思考如何使用它們到我的產品上,讓我的車牌辨識更聰明,也就是更AI更加值!基本上,在影像清晰的狀況下,用OCR方法就可以又快又準了,堅持一定要用CNN做主角是愚不可及的選擇!因為它們的卷積運算(Convolution)模式實在太耗時太低效率了!最終的辨識率還不如OCR的產品精準! 但面對較模糊的影像時,使用OCR要辨識正確必須先有切割正確的目標,如果多個字元因為影像模糊而沾連時,辨識結果當然就不對了!用目標的長寬比為依據強行分割目標,如太寬的就對半切割呢?那就好像連體嬰分割手術,連體嬰不保證兩個嬰兒都一樣大的!如果切錯位置嬰兒就都不能活了!如果只是稍微藕斷絲連的目標瑕疵就會導致辨識錯誤,那就難怪人家說OCR不AI了! 相對的,CNN的概念則好像是作事前的各種嘗試錯誤數值模擬,各種可能的切割方式都先掃描試算一次,然後用機率統計的概念找出整體特徵符合度最佳的方案,這樣做當然比較耗時沒錯,但就可以解決OCR在影像模糊時很難做出正確決策的問題。為了保持健康,我們當然不必天天到醫院作健康檢查,但已經察覺有身體異狀時,自己亂服成藥就絕對不如去醫院做徹底的檢查比較好!
如上的一個特殊案例,其實是車牌製作時不太守規矩,1與3兩個字印製得太靠近了,加上影像略為模糊時就沾在一起了!即使用聰明的人眼遠遠看都會像是一個英文字B了!用標準的OCR辨識程序答案就是DD_B0_L了!因為中間段落有個非數字的B,違反了印尼車牌的規定,我們知道這個答案一定是錯的,但要如何更正呢? 此時就可以請ML與CNN出場幫忙了!我們可以運用ML的統計概念先自我評估檢查一下!因為OCR已經辨識出大部分的字元,即使其中有一兩個是錯字,還是可以用統計學的概念估計出這個車牌中的字元應有的合理寬度與高度!所以會發現那個「B」顯然胖得很可疑?應該就是病灶了!如果拆解B之後變成兩個數字,答案就合理了! 這個估計字高與字寬的統計方法我以前就一直在用了!但是學過ML(機器學習)之後才發現這就是合乎機器學習中利用各種機率統計方法找出最合理答案的概念!我不知不覺早就一直在使用ML了!所以我認為科技始終來自人性這句話沒錯!相信自己的直覺與常識就不可能跟精準的科學或各種實用技術相差太遠的!
知道B字有問題之後就可以請CNN上台表演了!就是用如上的各個字元的特徵矩陣,也就是標準字模,將高度縮放到與合理的字高相等,再徹底掃描評估這個太大的B可能是哪兩個數字的組合?結果當然是符合度極高的1與3兩個數字了!所以正確答案是:DD_130_L,不會錯的!這個過程一路都是非常合理無需太多猜測的! 很多看似很「AI」的神奇判斷其實只是你不知道過程罷了!在複雜狀況的下要有聰明合理的答案,繁複的計算與多方面的條件考慮是少不了的!但是你不需要在無關緊要的地方動用所有完整複雜的運算,所以我即使真的引用了ML與CNN的概念技術,整體運算時間還是很快很節省資源的! 就像你有病時才去看醫生不會讓你破產,多數人應該不會天天生病嘛!如果大家都沒事就天天去醫院看病,整個健保就會被徹底拖垮了!這才是我大力批評那些狹隘AI觀念的原因!如果大家都認定所有的影像辨識都必須以CNN為基礎,地球暖化就無法避免了!只有輝達公司會先賺到很多錢!直到地球崩壞為止。 所以現在不管你是不是很狹隘的認定:只有使用ML與CNN的影像辨識才能稱為AI?我的影像辨識都是無可置疑的AI影像辨識了!而且還是比ML+DL+CNN更完整合理的升級版AI!因為我讓OCR與ML+CNN變成密切合作的團隊了!AI技術討論的重點並不是哪一種方法最好?而是如何讓各種方法充分結合產生最好的辨識能力!你同意嗎?
|
|
| ( 心情隨筆|工作職場 ) |