字體:小 中 大
字體:小 中 大 |
|
|
|
| 2024/10/31 04:46:02瀏覽495|回應0|推薦6 | |
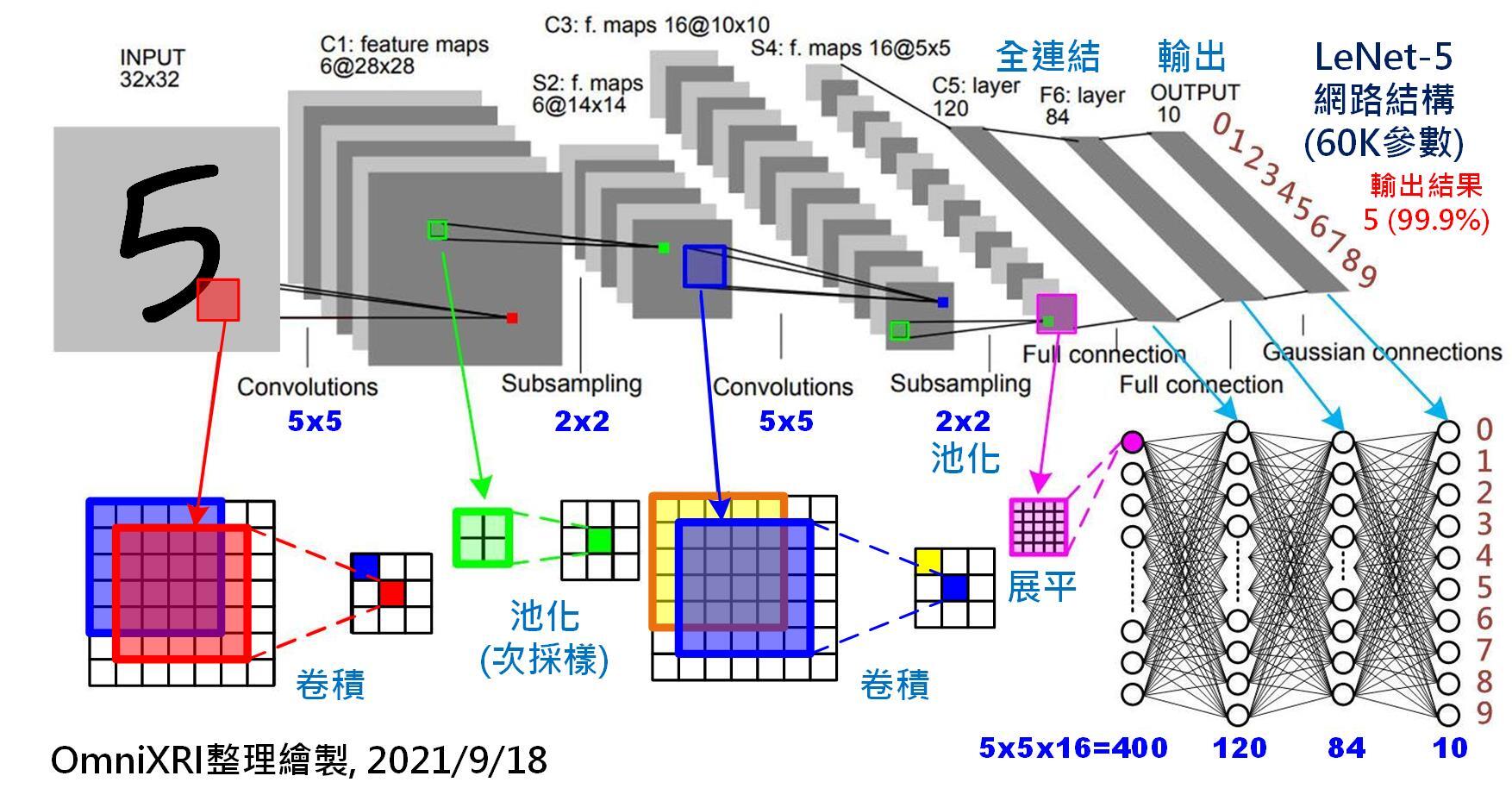
當所有人都在吹捧CNN(類神經網路)作影像辨識有多好?甚至快被視為「唯一」指名的影像目標搜尋方式時,我的各種影像辨識研發工作始終都還是對CNN敬而遠之的!最多只是在極小的模糊區域使用來猜字之用,這絕對不是積習難改或是偏見,而是實務上真的不能用! 因為一旦使用CNN計算量就會大上數十倍,辨識時間也會拖慢數十倍,要讓辨識速度變得合理,我就必須使用GPU的螞蟻雄兵來幫忙,那就表示我的成本會增加很多很多倍!如果辨識率會因此提高或許還值得?但事實上不會!很多開發者是根本不太會使用傳統的OCR方式,所以必須使用套裝軟體較多的CNN,但我知道有比CNN更快更有效的演算法,當然不必靠CNN討生活,不是我不會用,而是事實上不能用! 如上的案例,我使用OCR的方式辨識車牌,1920x1080的影像只需要120毫秒,也就是0.12秒。基本上是將全圖做二值化,再一一圈出黑色的區塊,因為黑字白字都有,所以正負片都要做目標切割,如下圖:
上面兩張圖上事實上我可以切割出13,556個區塊目標,聽起來好像很多?但這種運算使用氾濫式演算法是非常快的!完全不必使用甚麼矩陣掃描運算,就是沿著目標輪廓線連起來就可以了!找到那些原始目標後,可以依據它們的大小形狀與前景背景的對比度(亮度差)等資訊,很快就篩選出只有幾十個可能是字元的目標,如下圖:
要用這極少數(僅24個)的資料組織出合理的車牌,當然也是很快很容易辦到的!車牌組織好之後每個字元是甚麼字?就將每個車牌內的目標縮放到字模大小比對即可!這時候我的演算法才須用到最耗時的矩陣運算,但是範圍極小,所以我才能用這麼短的時間辨識成功!也可以很快將注意力集中於字元破損模糊等等例外的處理,提高極端狀況的辨識成功率,我的辨識軟體才能既快又準! 但是如果要跳過上述OCR的方式,用CNN的矩陣掃描方式直接從全圖中找到各個字元的特徵呢?那(全圖)每一個點的位置都必須做一次矩陣的相乘疊加計算,如果特徵矩陣是11x11那就是200萬畫素的121倍的乘法計算了!而且不同的字元特徵不同,你不可能只用一個特徵矩陣掃描就得到辨識所有字元需要的資訊。所以計算量又要乘上好幾十倍了!
如果你有好好讀書上課,CNN的概念是不難理解的,加上有OpenCV之類的工具函式庫幫忙,要實作也不難的!但是好像那些AI學者玩家都故意隱誨這種演算法天大的缺點?它的計算量實在太大了,大到作出來的辨識軟體「速度慢到賣不出去」!所以他們才需要GPU來救命的!還不斷研究YOLO來減少運算量,讓辨識率持續下探!而且要用GPU就表示要花更多錢買特殊規格的電腦,至少需要特定規格的顯示卡,還要買CUDA中介軟體,最後的結果就變成產品「貴到賣不出去」了! 我作影像辨識不是退休後的消遣,而是想靠這些研發賺錢討生活的!所以即使我真的很認真學會了CNN的概念甚至實作方法,但是淺嚐之下就發現完全不能用!速度太慢辨識率還很難提升,我用OCR前處理得到的資料就是字元目標了!但是CNN前處理之後還是散亂分布於全圖的特徵資訊,連可能的車牌字元在哪裡都還不知道! 所以我絕對不是標新立異,故意跟ML、DL與CNN這些熱門技術唱反調!這些技術至少以車牌辨識來說,完全比不上OCR的技術,簡直是天與地的差別!尤其是當你想做出可以賣的商業影像辨識產品時,用CNN是一點成功的機會都沒有!不是太慢就是太貴!只能等著被我這種不用CNN技術的廠商羞辱了! |
|
| ( 心情隨筆|工作職場 ) |