字體:小 中 大
字體:小 中 大 |
|
|
|
| 2024/01/25 05:37:01瀏覽663|回應0|推薦10 | |
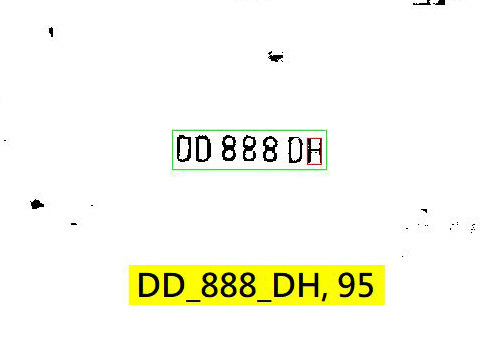
我天天撰文批評CNN等技術當然表示我也確實有在研究這些技術,否則不會有話聊的!但我會只為了找話題罵人而每天認真學習原本不熟悉的技術嗎?我沒這麼無聊的!又不是打選戰,只要抹黑對手就有優勢了?我是在積極替自己尋寶的!把我的影像辨識做得好我才有錢賺,罵死CNN也不會有人給我錢的,甚至可能得罪當道被開罰單或套布袋捱揍的! 我的大量批評是因為我跟著大家說的藏寶圖找到寶藏了,但是左看右看對我來說九成以上都沒用處,我家已有的工具寶物就比它們更好用了!但有沒有真的能用的概念技巧呢?當然還是有的!上面的這個車牌辨識案例就是一個非常簡單易懂,CNN幫我解決了難題的例子!
按照我的OCR技術操作,就是要設法切割出所有獨立的字元湊成完整的車牌,但是碰到如上的意外,車主莫名其妙加上的白框跟H字元完全相連,我的OCR就無法正確切出H了!H字元等於埋藏在整個好大的邊框目標內部了!如果只是兩個字太靠近而沾連形成不合理的較大目標時,我可以找個近似的中線做字元切割,就像連體嬰雙胞胎的分割手術。 但是這個案例,H與邊框形成的目標根本大到我不會將它視為有可能是字元的目標,想切割也不知道如何下手?沒有合理的量化評估準則啊?在以往我只能看得吐血忍痛放棄承認失敗了!但是CNN說任何特徵只要拿著適合的特徵加權矩陣去掃描搜尋(Convolution)就一定可以找到!理論上只要這張影像中有一個H字,地毯式掃描下去,根本不做OCR也可以找到的! 我批評CNN的是做全圖掃描太愚蠢太耗時不切實際,但是我不否認這個方法真的可以找到任何有指定特徵(如H)的目標,而且不會受到OCR方法必須有合理正確的目標切割之後才能辨識的限制!我只用OCR辨識這個車牌功敗垂成,只差一個字!但我已經知道夠多這個車牌的資訊了! 就是它的字元應該是多大(寬高),字元排列的方向(傾斜)與字數等等,如果我發現或懷疑邊緣還有字元被遺漏了!我可以立即知道:我如果要用CNN找這個疑似漏字時,應該用多大的特徵矩陣?以及應該掃描哪個概略的位置範圍?這樣使用CNN就不會很耗時了!
這表示我可以很精準高效率的使用CNN技巧,很快就找到那個我已經知道有多大,位置可能在哪個範圍的H了!如上圖,我幾乎功敗垂成的OCR失敗辨識用CNN的技術緊急救援之後就活了!而且不必忍受CNN超大耗時的不合理計算量!整個辨識過程畢竟還是以快速有效的OCR為主體,不是低效率的CNN嘛!200萬畫素影像的辨識也不到0.3秒。
|
|
| ( 心情隨筆|工作職場 ) |