字體:小 中 大
字體:小 中 大 |
|
|
|
| 2024/01/24 05:42:56瀏覽634|回應0|推薦5 | |
|
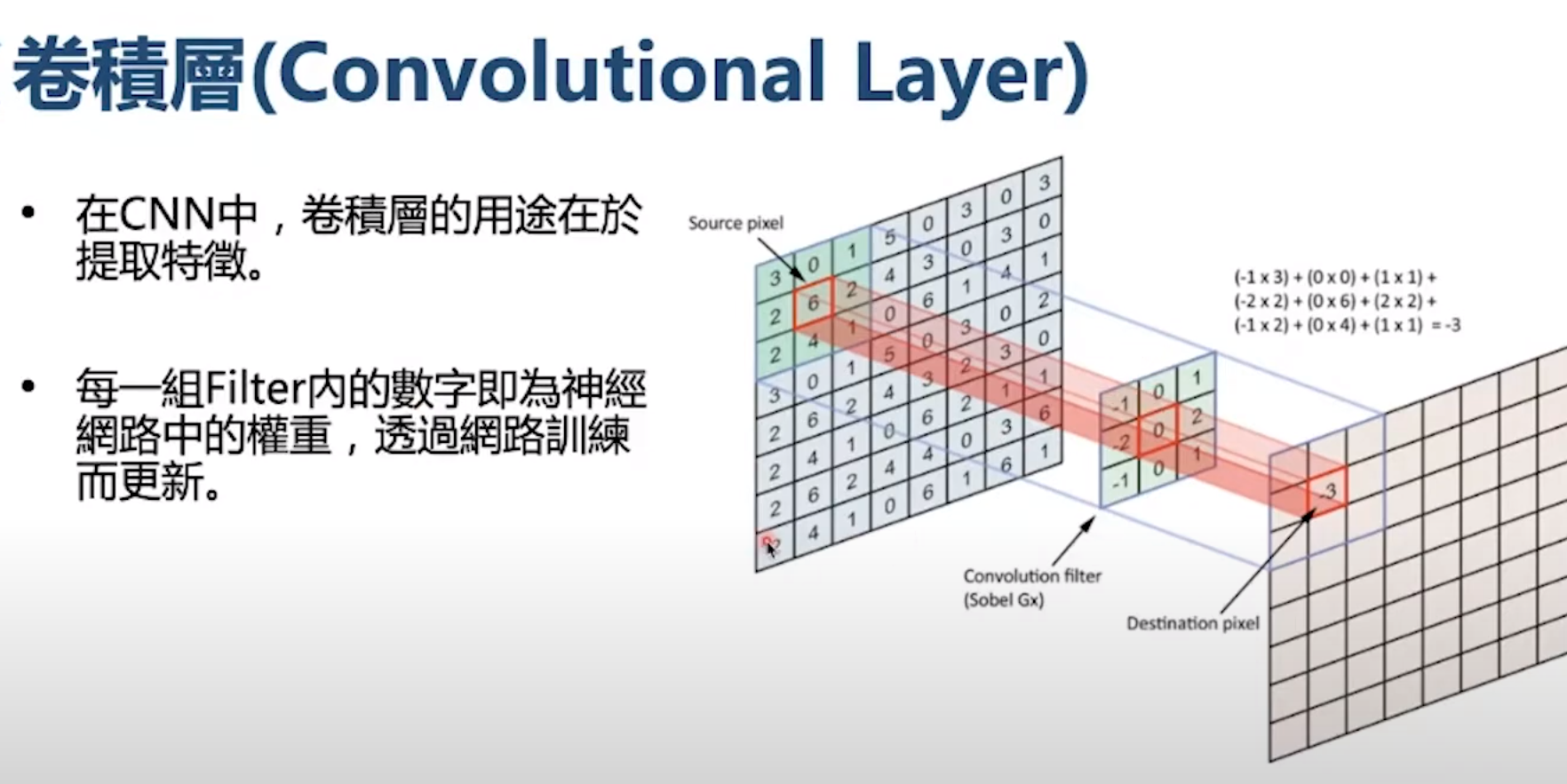
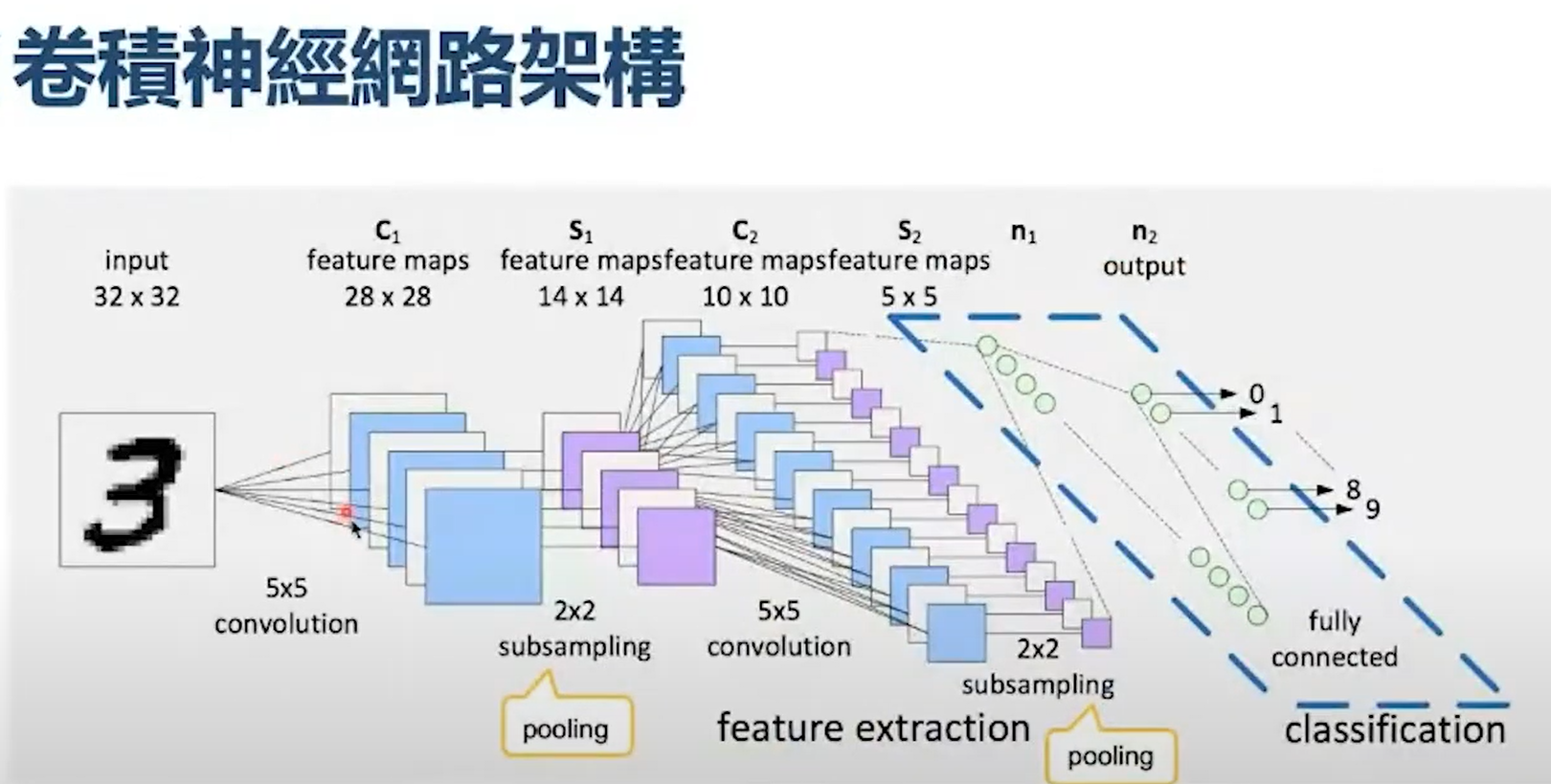
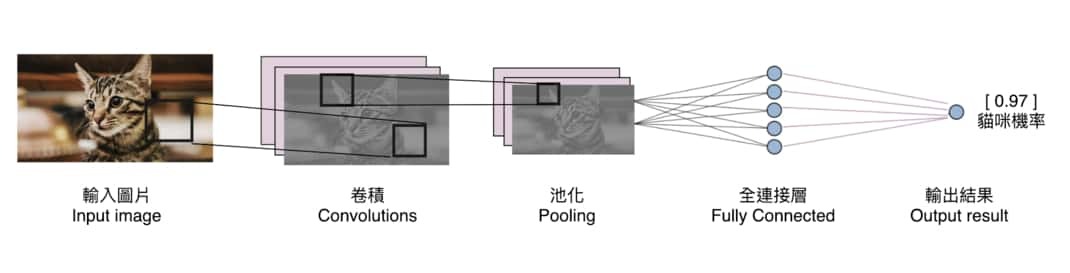
ML、DL與CNN(類神經網路)等AI技術的基本特徵,對於一般人來說,就是數學的抽象程度讓人望而生畏!當你好不容易上了很多課,終於摸索到一點頭緒,也開始可以操作它們做一些事情時,就很容易自信爆棚而飄飄然自以為高人一等,我是AI專家了嘛!但是我奉勸這些人等到真的做出AI產品之後再得意,因為通過這個技術門檻的人絕大部分最後都毫無建樹,空歡喜一場。 事實上正因為這些方法在數學理解上的困難,讓多數人都肅然起敬,拋棄了自己的常識與直覺,很容易就被誤導,忽略了這些方法論基本上存在的大問題,所以玩到走火入魔之後,還是無法解決大部分需要高度精確的影像辨識問題!這些技術當然不是沒有用處,但是對於需要高辨識率的應用,其實是理論上就做不到的!選用CNN表示你已經放棄辨識率高於九成的可能性! 我們是使用傳統影像辨識技術執業中的公司,在完全沒有使用這些AI技術時,已經是經營成功的公司,從車牌辨識到閱卷辨識到瓦斯表辨識,做任何產品或專案都無往不利!這些產品的辨識率都是95%起跳,通常是高於98%的!但是當全世界都說那些AI技術很好時,我們當然不會像義和團一樣,相信自己有神功護體?我們一直都很認真關注學習與理解那些AI技術的! 詭異的是:好多年過去了!這些山雨欲來的挑戰對手始終是「只聞樓梯響,不見人下來?」我們沒有感受到這些AI技術的實質挑戰?我們做的影像辨識始終還是優於使用那些所謂AI技術的公司?一開始我們真的非常疑惑?但是真的認識CNN之後我們就越來越放心了!他們沒「跟上來」是很合理的結果!而且應該永遠都不會跟上的!因為我們也開始截長補短,善用CNN等技術的少數優勢融入我們主要使用的OCR技術了! 如上CNN介紹文章與影片所述,CNN影像辨識的第一步就是用原始影像經過矩陣的卷機運算得到Feature map,大家看出問題了嗎?好聽的說法是「抽取特徵」,但實際上也是「簡化影像」就是一開始就自己揮棄了最高精確度的原始資料細節!一次簡化還不夠,還很多層的一再簡化(Pooling)咧!自宮還不夠,連頭髮體毛都要剃得乾乾淨淨嗎?
所以如果你希望辨識的目標就是細到只有幾個畫素寬的文字筆畫,如街景中的車牌呢?第一次Convolution就已經把目標洗掉了!還玩甚麼?先把原圖的高解析資訊簡化、抽象化、特徵化或許有助於在叢林中找到兔子,但是對於精確辨識兔子的五官特徵,想藉此辨識兔子的種類呢?當然就不可能了!上圖不是越Pooling越模糊了嗎?根據已經失真的影像繼續做下去,會出現奇蹟嗎? 最新的CNN如YOLO強調他們只需要掃描影像一次就得到需要的資訊,但那只是定位目標大概在哪裡?如果要做精確辨識就必須回到原始資訊再做局部的「傳統」影像辨識了!就是不能用任何矩陣卷積,必須乖乖使用OCR的技術流程的意思!所以這麼複雜的CNN卻只能作影像辨識的半套流程?後半段的精確明確辨識是無法直接用CNN做到的!那不是純心整人嗎? 那如果我完全使用OCR就可以連目標定位都做到呢?我就根本不需要CNN了!我們公司的技術內涵基本上就是這樣的!簡單說:CNN的卷積運算就是先「揮劍自宮」降低影像的解析度,這就讓精確的辨識變成不可能了!已經不存在的資訊可以用後面程序的複雜數學模式再變出來嗎?你去問上帝吧! 所以你覺得CNN這樣揮劍自宮之後還可以「練成神功」嗎?或許吧?但顯然很難,所以在我的公司做的諸多影像辨識工作中,那些CNN團隊始終還是看不到我的車尾燈的!希望他們繼續慢慢走,我就不送不陪了! |
|
| ( 心情隨筆|工作職場 ) |