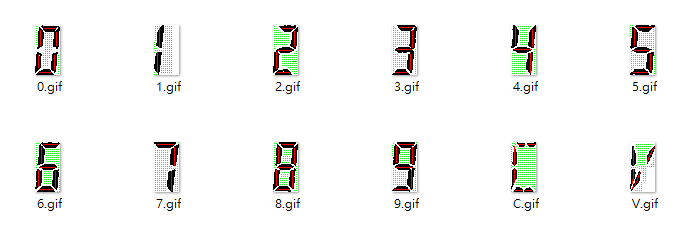字體:小 中 大
字體:小 中 大 |
|
|
|
| 2026/02/28 02:26:40瀏覽42|回應0|推薦0 | |
前文說我只用兩天的時間,就從無到有完成辨識上面這種英數字的程式,也說好只會跟客戶收12萬元,就要做到完美的辨識率?好像這件工作很簡單?事實上,開發過程內發生的故事也可以寫成幾篇論文了!絕對不是像一般半吊子工程師們想像的,找OpevCV或一些網路程式碼範例就可以迅速組裝完成的!這絕對是一個需要高度專業知識技術才能做到的事情! 即使簡化到我們事先就知道瓦斯表數字區的位置,如上字元區的二值化之後,每個字元其實也都不是獨立的黑色塊狀目標,很像辨識中文字,一個字其實可能是由多個獨立不相交的筆劃目標所組成(如川字)!如上圖的C字,其實是六個獨立目標的集合!每一個數字也都是多個獨立的LED燈的亮或暗區目標的組合! 所以如何在這種其實是在破碎狀態的初步資料中定義何謂「一個字」?就可以有很多故事可說了!對於一般人的智慧來說,這是下意識的一瞬間就可以認知的簡單事情,但是如何寫成具有一樣認知能力的程式呢?OpenCV也沒有完整範例說明與示範的!你必須真的理解與掌握這個過程中的數學化內涵!
所以建立出如上圖的幾個字模只是還算簡單的一部份工作,真正麻煩的是去認知圖中哪些破碎目標可以或應該視為一個獨立的字元?但是要建立出這種我們公司(我的RD)發明的特徵字模就需要好幾個小時!如何製作?也只有我們自己知道,沒有公開資訊可以參考的!如果你用一般簡單的黑白二色字模呢?辨識率會被二值化的過程參數嚴重影響的! 而且別忘了!我們的辨識核心是不能預設知道瓦斯表顯示面板位置的!即使我們知道攝影畫面是固定的!但是日後這個軟體會用在不同的廠區地點,每個地點的取景範圍是不會完全一樣的!我們也不想讓使用者事前還要手動設定每個新畫面中的數字面板位置在哪裡?這個動作感覺很不AI嘛!
所以在全圖中自動鎖定需要辨識的數字面板也是工作的一部份!如上圖的搜尋鎖定過程也可以寫成一篇論文了!沒有簡單現成的函式庫或範例程式可以直接抄襲模仿的!因為我懂得所有需要知道的專業知識與技術,我的車牌辨識不是可以在複雜的街景中迅速找到車牌嗎?所以我可以非常流暢的只用兩天做好這麼多複雜的工作!其他只會用機器學習套公式交給電腦訓練模型的公司是完全做不到的! 所以我開出的12萬元價格是太便宜?還是太貴?哪有人兩天工作就要12萬?上班一天就要一個助理教授的月薪?但我可是花了超過十年才對影像辨識懂得那麼多的!內容還多半是自行研發累積的成果!還沒入行時我對這些報價應該多少毫無概念,現在我懂了!也希望所有人,尤其是會找我研發的客戶都一清二楚! 對於客戶來說,更重要的是:我的報價一定比使用ML、DL與CNN的公司低很多!辨識率呢?一定是大於或至少等於他們的產品!辨識速度也一定比較快,執行辨識需要的硬體成本與耗電也一定是低很多的!現在我還挺閒的,產能還很多!有需要的就快來找我開發辨識產品吧! |
|
| ( 心情隨筆|工作職場 ) |