字體:小 中 大
字體:小 中 大 |
|
|
|
| 2026/02/23 16:16:53瀏覽101|回應0|推薦3 | |
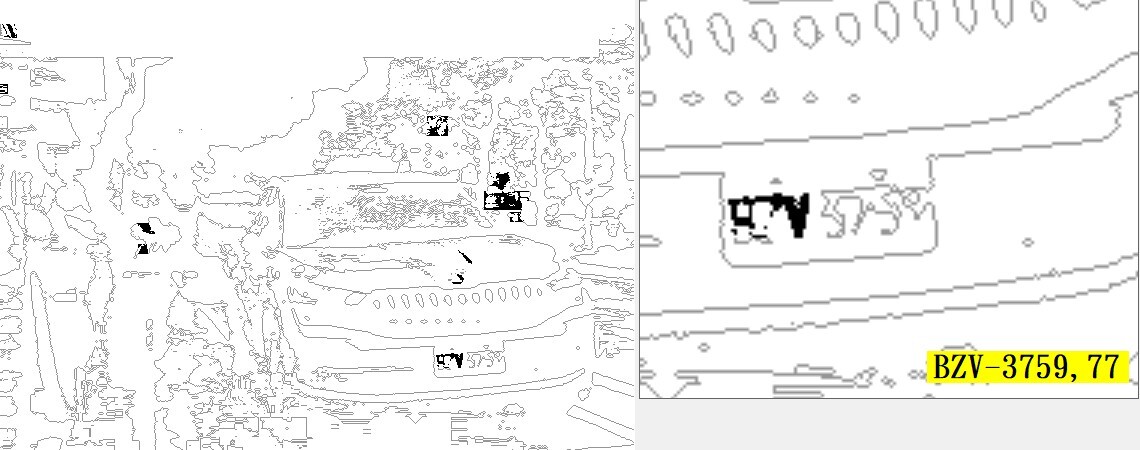
各位知道為什麼很多人說CNN,就是類神經網路,的辨識方法很厲害嗎?關鍵就是傳統的OCR辨識必須經過二值化目標切割的程序,碰到如上這麼模糊的影像要將字元正確切割出來幾乎是不可能的!但是CNN是直接用特徵矩陣去掃描原圖影像的!只要有個模糊的影子,某些特徵有點像是某個字?就可以經過訓練學習統計後抓(判斷)出來了! 但是CNN的問題是因為事前不會知道字元到底是多大?所以只能盲目的地毯式搜尋全影像,所以計算量很大,大到必須努力研發YOLO等技術,在不脫離CNN的架構下減少運算量。即使如此,最終運算量還是大於OCR數十倍!所以必須仰賴GPU來消化過多的運算量,不然影像辨識就會慢到讓人抓狂了!這也間接讓CNN變成高價位昂貴辨識系統的商標了! 我的辨識技術是以OCR為基礎的!我碰到的問題跟CNN不同,我可以很快速地找到可能是車牌的目標,如下圖。但是顯然它們還不足以讓我辨識出每一個字元!所以我就針對可能的目標區做進一步的幾何投影校正,及影像增強處理,然後再從這些已經比原圖更清楚的小影像中做精準的CNN特徵字模掃描!
所以我終究還是利用到了CNN的模糊辨識能力!可以正確辨識出如上圖這麼模糊的車牌!所以任何人都不能說我的影像辨識技術有任何地方不如CNN了!而且我不必做地毯式的CNN全圖掃描,所以完整的全圖辨識時間還是只需要約0.2秒!當然因為計算量不大就不需要GPU,使用我的軟體就不必買昂貴的電腦硬體了! 所以大家不必再爭論是OCR比較好?還是CNN比較厲害了?答案是兩者可以水乳交融充分整合!你只需要知道逸中軟體的車牌辨識包含了兩大主流技術的精華!兼具OCR與CNN的辨識優點,辨識又快又準又便宜就好了! |
|
| ( 心情隨筆|工作職場 ) |