字體:小 中 大
字體:小 中 大 |
|
|
|
| 2026/02/10 04:55:59瀏覽106|回應0|推薦5 | |
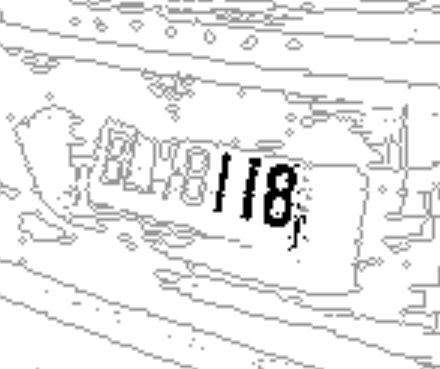
這種清晰程度的車牌如果無法辨識當然是非常讓人無法接受的!但是以OCR為基礎的辨識技術來說,這真的是很尷尬很難辨識成功的案例!看看下面經過二值化切割後找到的獨立目標圖就知道,只有後面的118三個字可以被正確切割,其他的字都會與背景沾連無法被切割為獨立字元。
之前的版本,我在全圖搜尋可能是車牌的目標組合時,目標數下限是四個!也就是如上三個整齊排列的目標會被忽略,當然就不可能找到這個車牌了!為什麼會有這個四個目標的門檻限制?首先是為了減少運算量,其次是越少目標的組合要經過後續處理逐步切割、拚合甚至挖掘出所有的車牌字元,演算過程就會越複雜,出錯的機率也就越大,成功機率太渺茫的路線就先不考慮了! 但是當我以四目標為起點的運算架構都成熟穩定之後,我開始將門檻下修到三個目標的排列組合,當然會減少很多遺珠之憾,上面就是一個很經典的例子!好像是在一團亂絲之中找到一個頭緒,如果我認為118是某個車牌的一部份,我只要按照它們已經形成的規律,如字元的寬高與距離等等,往左右區間強制切割搜尋找出其他的字就可以了! 譬如從第一個1字往左在一個概略應該有字的小區間使用類似CNN的特徵矩陣Convolution運算方式,就可以很快找到一個清晰正確的8字了!確認有個8字之後再繼續嘗試往左搜尋,很快又可以找到M字了!依此類推,直到再往左就找不到字元符合度夠高的目標時就停止了!往右搜尋的過程也是一樣! 所以即使OCR的基礎運算只能直接找到七個車牌字元中的三個,我也可以仰賴CNN的技術把所有合理的字元湊齊!所以嚴格講我也是有使用CNN技術的!只是在此它們是OCR技術的配角與延伸,如果要在全圖中毫無前提的狀況下使用CNN搜索出所有的七個字元呢?那就會讓運算量大到需要YOLO技術來減量,即使如此都還是運算量大到非用GPU幫忙不可!我沒那麼笨的!那是一場大災難!而且是可以避免的! 所以不要再誤以為使用GPU是甚麼蓋高尚的AI策略了?他們其實是有苦說不出,因為演算法的效率太差,導致運算量太大才不得不用的!以影像辨識來說,我就是找到其他不必那麼多計算量的演算法解決了一樣的辨識問題!所以不要再誤以為我宣稱不用ML、DL與CNN就是不夠AI了!我其實是更有效率的AI研發者!買我的辨識軟體不必使用GPU還更快更準!你說是誰比較AI呢? |
|
| ( 心情隨筆|工作職場 ) |