字體:小 中 大
字體:小 中 大 |
|
|
|
| 2024/03/04 15:29:08瀏覽580|回應0|推薦1 | |
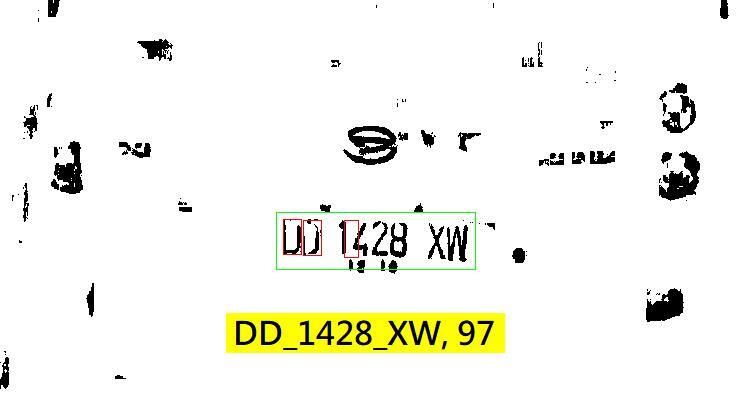
這個案例很有趣!應該是攝影時產生的不均勻反光,前面兩個字元DD非常黯淡還跟背景沾連在一起,我單純使用OCR的辨識方法只能確認1428_XW等幾個字。如果我相信這幾個字是車牌的一部份,從車牌應有的格式推斷,前面一定還有一到兩個英文字,而且應該還有一點空白的距離! 我也可以確定:同一個車牌內的字元高度應該都一樣,寬度部分如果是字元I或數字1會比較窄,如果是字元M或W則會略寬,其他字元大致是等寬的!從已經用OCR辨識成功的1428XW等幾個字我就可以推算出寬字元(W)、窄字元(1)與其他字元的標準寬度了! 也就是說:我已明確知道尚未發現的一或兩個字元的寬度與高度,與它(們)可能存在的概略位置了!即使我無法用OCR的技術將它(們)正確切割出來,但是我可以用CNN的卷積運算(Convolution),就是建立跟字元應有大小一樣的特徵矩陣,去掃瞄搜尋可能的區域,應該很快就能找到那兩個不明顯的字元!就像從一個口袋裡摸出一個銅板一樣簡單,如果要在一整個房間裡找一個銅板呢?那就要找很久了!所以我不建議全圖都用CNN! 上述案例中,我的程式就是這樣順藤摸瓜式的把OCR找不到的字元,用CNN的技巧輔助辨識出來的!OCR的優點是運算簡潔快速,缺點是當目標邊界模糊時就無法辨識;CNN則是以區塊特徵的強度來評估目標的,任何位置都會產生一個加權值(可能性),所以不會有「完全找不到」的問題,總是可以有數據可以猜一個最可能的答案!缺點則是運算量太大很耗時! 如果我們堅持要在全圖所有位置,都用CNN的方式評估各種大小各種字元的可能性,那就會是一場災難了!光是用Convolution計算特徵加權值的計算量就大到不合理的程度了!每一個位置都有所有字元的加權值,又是新產生的巨量資料,會讓分析評估的運算量隨之暴增! 所以才會有那麼多代的YOLO,其實都是在努力減少運算量,讓CNN可以比較快一點執行。整體來說都是引用OCR的ROI觀念,參考很多周邊或過程資訊跳過不重要的區域與資料計算,或是期待更多的硬體GPU來助陣,消化過大的運算量,使用OCR是沒有這種壓力的!所以不要再迷信CNN甚麼都比OCR好?或OCR過時了?之類的謬論!事實根本不是那樣的!他們各有所長也各有所短,充分理解各種方法的特性截長補短才是最佳的AI策略! 如果我在OCR已經把大部分問題解決後,面對OCR無法處理的極端狀況時,限定在極小的區域(某個ROI區域)才使用CNN掃描估算目標字元,當然計算量就很小了!有點類似生病吃藥就會好就不必開刀的概念,將CNN當作無計可施時的最後昂貴手段,整個影像辨識程序就會非常有效合理也很便宜了! 簡單說,把OCR當作車牌辨識流程的主體,CNN當作解決終極困難區域的特殊手段,應該就是最佳整合方案了!我就是這麼作的。
|
|
| ( 心情隨筆|工作職場 ) |