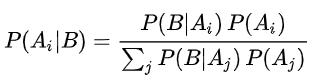字體:小 中 大
字體:小 中 大 |
|
|
|
| 2023/09/10 05:17:03瀏覽573|回應0|推薦8 | |
這是一個很有趣的實際案例,因為車牌小又模糊,我的辨識程式其實勉強辨識出了正確的車牌號碼:LAM-1116,但是原始的字元比對符合度其實只有75%,根據我自己設定的80%算是不及格,應該把它忽略的!但是我偵測到了它明確是一張黃色的車牌,而且第一個字元是「L」,這是黃牌重機非常明確的特徵! 如果是你用眼睛看到這個畫面,即使因為距離遠有點模糊,但是主要特徵已經很明顯是個黃色重機的車牌,你會直接忽略它?說我根本沒看到它嗎?即使因為模糊可能七個字元中有一個字元有錯誤,但「有個黃牌重機」和「沒有車牌」兩者資訊的意義與價值也是差很多的! 一個車牌辨識軟體碰到這種情況時,應該怎麼作?怎麼反應?才能讓使用者覺得這個軟體很「AI」呢?如果我一板一眼按照SOP判斷「沒有車牌」會比較符合使用者的期待,還是報告出「我看到了一個黃牌重機的車牌」呢?根據我的經驗統計,只要是七碼的車牌,字元交叉誤認的機率是很低的,也就是75%的符合度已經幾乎不會誤認任何字元了!答案LAM-1116的正確機率其實是很高的! 我現在做車牌辨識的目標已經不是寫出數學模式漂亮完美的SCI論文了!而是想盡量滿足客戶對於AI辨識軟體的期待與需求!所以如果我放棄這個符合度「不及格」的案例,說此地「沒有車牌」?使用者是不會滿意的!如果他們因此低估我的軟體,認為不夠AI?不買了!那就比論文沒被SCI錄取的傷害更大了! 但是我也不可能守候在我賣的所有軟體旁邊,隨時幫我的軟體做出最合乎客戶想法的判斷,所以我還是必須建立合理的數學模式,讓程式可以做出最接近一般人智慧的決定!這就是我做AI影像辨識的理念,也是我天天工作的方向與內容。所以符合度75%只是我使用的資訊之一,我還會注意到車牌是很特別的黃色,與字首是L這些特徵,給我的辨識結果加權計分,最後就是上面的結果了! 那現在大家說的AI,就是以機器學習為核心的那種AI是怎麼作的呢?他們的核心就是機率統計學的貝氏定理:
即使需要參考的條件很多時也都是以此為架構,「整合」更多條件的整體機率而已,公式會變得看起來很複雜有學問,但是其實只是資料的統計,並沒有辦法實現如上案例的思考判斷!要用數學來辯論嗎?請注意到如上摘自維基百科的公式,貝氏定理適用的前提是「隨機事件」!但車牌是不是黃色?車牌第一個字元是不是L?則都是很確定的資訊,也影響限制了整個最終答案的判斷,光用貝定理是絕對無法實現我前面敘述的「思考」過程的! 我自己是先使用了我的邏輯做出了商業產品,才開始學習機器學習理論概念的!我當然很想利用大家都看好吹捧的AI機器學習讓我的商業產品更上一層樓!但是幾年下來還是覺得格格不入,無法替我的既有產品加值。甚至覺得他們太僵硬愚蠢了!即使我放棄既有基礎,完全改用機器學習,我也想不出任何可以做出合理AI產品的可能性。你們如果聽懂了我的理念和機器學習的原理,拜託幫我想想這個問題吧! 至於最近瘋迷的「生成式」AI大家也不要太高估它們了!他們很像培養生物,用既有的資料,在限制條件與環境下隨機選擇,可以很快產生一些看似「合理」的成果,像是一篇文法沒錯,內容與預設主題不衝突,可以拿到及格分數的報告! 但是要正確辨識一個略模糊的車牌呢?那是一個完全不同的AI,是解決明確問題的AI,過程中沒有隨機選擇的空間,隨機選擇對於得到正確答案也完全沒幫助!這種AI需要的是充分理解問題與分析問題,正確使用所有資訊來解題的AI!如ML、DL與CNN之類的以機率統計為基礎的演算法其實是根本不適合使用於此的!我現在只感嘆它們已被炒作過頭,回頭太難,影像辨識科技的進步至少會被這些假AI技術擾亂耽誤十年以上! |
|
| ( 心情隨筆|工作職場 ) |