字體:小 中 大
字體:小 中 大 |
|
|
|
| 2016/04/06 08:11:14瀏覽1499|回應9|推薦23 | |
AlphaGo - Stronger than human's at Go? 本文是大俠長子英文課(科目:ENGL 390 / 老師: Dr. Nick Bujak)上所寫的報告,寫於3/10/16。 Recently, a friend of mine saw a Facebook post by Google announcing that they have created a program called AlphaGo, a computer program that has successfully beaten Fan Hui, a professional Go player and European Go champion. Why is this significant? This is an unprecedented feat and marks the first time a professional human player has been beaten by artificial intelligence without the benefit of a handicap (compensation stones placed in the beginning of the game due to difference of ability.) Even more impressive is the fact that the computer won five to nothing; a solid victory in a series that leaves no one questioning the abilities of the computer. History The history of Go dates back to around 2,500 years ago where it was considered one of the four pastimes (along with music, painting, and calligraphy) worthy for a gentleman. The game is relatively simple. It is a turn-based game played on a 19 by 19 grid with black and white stones. Each player takes turns placing down pieces on the intersection of the grids with the objective of controlling more than 50 percent of the board. The game gets interesting when complicated patterns arise from both players trying their best to outwit their opponent. Programming Nightmare The first reason why it is so difficult for computers to be programmed to play Go is because of the massive number of combinations in the game. There is an estimated 10 to the power of 700 possible variations of the game of Go. By comparison, Chess only has 10 to the power of 60 possible scenarios. Secondly, it is hard for computers to estimate at any board position whether white or black has the advantage. This is different from chess or checkers because oftentimes one may be winning because they have one more piece on the board than the opponent. In Go, the status of stones being alive or dead may be ambiguous. Coupled with the fact that positional strength is hard to judge, Go is a programming nightmare. Since it is impossible to accomplish this task of solving this game directly, a different method is required. The Solution Prior to AlphaGo, Go programs generally focused less on evaluating the state of the board and more on looking at how the game may play out. Crazy Stone used an algorithm called the Monte Carlo tree search to sample some possible moves to choose between rather than trying to calculate every possible sequence. Using this method, Crazy Stone is able to defeat high level amateur players. The research team at Google DeepMind, however, decided to confront the issues of Go directly. Instead of determining the best move through randomly generated options, it distinguishes a good move from a poor one and assesses the strength of its position based on the state of the board. To accomplish this task, AlphaGo is programmed with the ability to utilize a combination of a Monte Carlo tree search along with deep neural networks, or programs that attempt to learn through interpreting data through examples and experience. In combining an already popular method for calculating Go moves along with cutting edge computer learning technology, AlphaGo is able to be to crush a human Go professional. Despite this, many other top professionals remain skeptical of its ability as some would describe the program's play style as being too passive. AlphaGo would have to take more professional opponents in order to sway disbelievers.
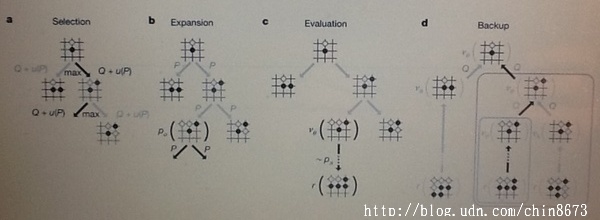
AlphaGo: Reinforced Learning In Go Following the defeat of professional Go player Fan Hui, I am interested in how the program AlphaGo displays such a high level of skill. For this research, I will go in depth in describing how AlphaGo works and explain how it is better than its predecessors. The game of Go has been considered the one of the most, if not the hardest challenge in game programming due to its massive search space and the difficulty it is to judge board positions. Past attempts to solve Go relinquish the idea of tackling the task of evaluating every position head on. In the case of Crazy Stone (the previous strongest Go program), a Monte Carlo Algorithm was used to simulate up to fifty thousand random games per second in order to evaluate a move. If, for example, black wins more often than white because of a particular move, then that move is more favorable to black. This strategy, however, may miss out on the best result since Crazy Stone is not analyzing based on position. Deep Neural Network In order to attempt this difficult task, a new approach to solving the game must be undertaken. As a result, a Go computer that employs the use of 'value networks' to assess any given position along with a 'policy network' to select the optimal move is created. Combined, these networks form what is called a 'deep neural network', which is 'supervised learning' by looking at past human games along with 'reinforced learning' by playing itself. Using this method, AlphaGo has maintained a 99.8% win rate against Crazy Stone. Supervised and Reinforced Learning In order to create a neural network that is efficient, AlphaGo is given supervised and reinforced learning in the form of networks. Supervised learning (SL) works by predicting the opponent's moves through the use of a multi-layered policy network (pσ) containing 30 million board positions from the KGS Go Server. Using this information as an input, AlphaGo's policy network is essentially trained to be able to predict expert level moves of the game 57% of the time. Improvements in accuracy led to improvements in playing ability with the sacrifice of slower reaction times. Next, a reinforced learning (RL) policy network (pρ) improves upon the SL policy network by optimizing what happens later in the game by making AlphaGo play itself millions of times. This policy allows trains AlphaGo how to win games, rather than just predict what previous experts may do in specific situations. Lastly, a value network (vθ) predicts the winner of the game. This network is trained and optimized by the games against itself through the RL policy network. AlphaGo uses this knowledge gained from the facilitated training in policy networks with the Monte Carlo Algorithm in order effectively play Go at a high level. Monte Carlo Algorithm Along with the deep neural network, AlphaGo uses the Monte Carlo Algorithm in order to facilitate the selection process of each move. The Monte Carlo Algorithm simulates repeated random samplings of tens of thousands of games that are already pre-programmed within the AI's database. Its method evaluates the possible inputs and aggregates the results in order to find a move. Figure below: How Monte Carlo Algorithm works for Go
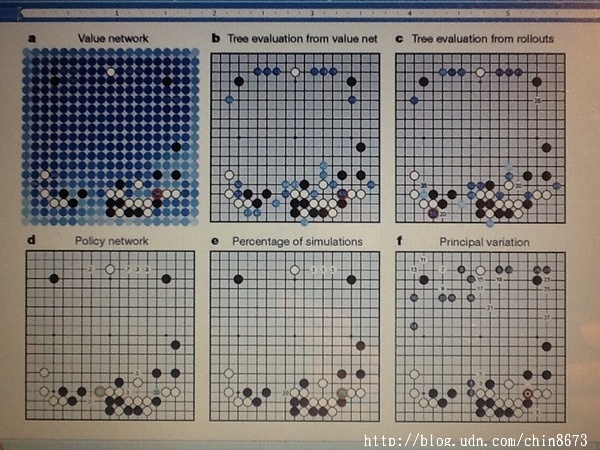
In the diagram, a) proceeds through a tree by selecting moves that have maximum action value Q, plus a function u(P) being the result of prior stored probability P. In b), each node of the tree search may be processed by pσ or the policy network and the outputs are stored as P for each following action. At c), the evaluation of each leaf node goes two ways: using the value network vθ and by rollout policy pπ in order to predict what may happen later in the game. For backup, d) shows action values Q that continue to update evaluations in c) in order to better respond to the opponent's actions. Value and Policy Networks Figure below: How AlphaGo selects a move in the game against Fan Hui
This diagram is an example of a position in which AlphaGo must make an optimal move. In a) it evaluates all possible moves highlighted by the different shades of blue. The darker shades indicate a higher chance of winning. The circled position in orange indicates the point with maximum value according to the statistics AlphaGo calculated. b) Shows possible actions that may occur averaged over the value network purely. c) Is similar to b) but it shows the best possible action from a positional point of view. d) Shows the frequencies of the actions that were picked out by the policy network. e) Presents the frequencies the moves were selected based on numerous trial and error results from AlphaGo's search tree. f) Alphago selects to play the move indicated by the red circle. Fan Hui responds by playing the move indicated by the white space above the red circle. AlphaGo indicates that the move (labeled 1) would have been the most optimal result. Conclusion By utilizing the both the policy network for SL and the value network for RF, AlphaGo is able to optimally evaluate game positions in a way that has never been done before. Combined with previous technology (Monte Carlo Algorithm), AlphaGo is able to defeat a professional Go player. This is a feat that has never been achieved by past Go programs.
Bibliography Borrell, Brendan. "AI Invades Go Territory." WIRED. 19 Sept. 2006. Web. 8 Mar. 2016. "Google Achieves AI 'breakthrough' by Beating Go Champion - BBC News." BBC News. 27 Jan. 2016. Web. 23 Feb. 2016. Cho, Adrian. "'Huge Leap Forward': Computer That Mimics Human Brain Beats Professional at Game of Go." Science AAAS. 2016. Web. 23 Feb. 2016. Gibney, Elizabeth. "Google AI Algorithm Masters Ancient Game of Go."Nature.com. Nature Publishing Group, 27 Jan. 2016. Web. 23 Feb. 2016. Naughton, John. "Can Google's AlphaGo Really Feel It in Its Algorithms?" The Guardian. Guardian News and Media, 31 Jan. 2016. Web. 23 Feb. 2016. Nunez, Michael. "Google Just Beat Facebook in Race to Artificial Intelligence Milestone." Gizmodo. 27 Jan. 2016. Web. 23 Feb. 2016. Silver, David, and Demis Hassabis. "AlphaGo: Mastering the Ancient Game of Go with Machine Learning." Research Blog. Google, 27 Jan. 2016. Web. 23 Feb. 2016. Silver, David, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. "Mastering the Game of Go with Deep Neural Networks and Tree Search." Nature 529.7587 (2016): 484-89. Web. |
|
| ( 不分類|不分類 ) |