字體:小 中 大
字體:小 中 大 |
|
|
|
| 2021/12/09 15:03:52瀏覽734|回應0|推薦2 | |
現在螺絲釘的辨識核心主要演算法大致底定,多半已經在處理細節的調整,包括很多門檻的合理性調整,與各種子流程的優先次序與互斥的片段等等,其實還是天天花很多時間研究。上面這一張就是一個讓人扼腕揪心的錯誤案例!甚麼都對了!卻把C字辨識成G字,規格型號中還真的F593C與F593G兩種都有! 放大來看就知道為何產生這個錯誤了!好死不死,C字應該缺口的地方硬是出現了要黑不黑的雜訊?如果它更黑一點,眼睛都會看錯,我可能就算了!但是「視覺上」字的部分還是比雜訊黑的!所以「理論上」影像處理應該可以解決!就是更正確的把他們切割出來!
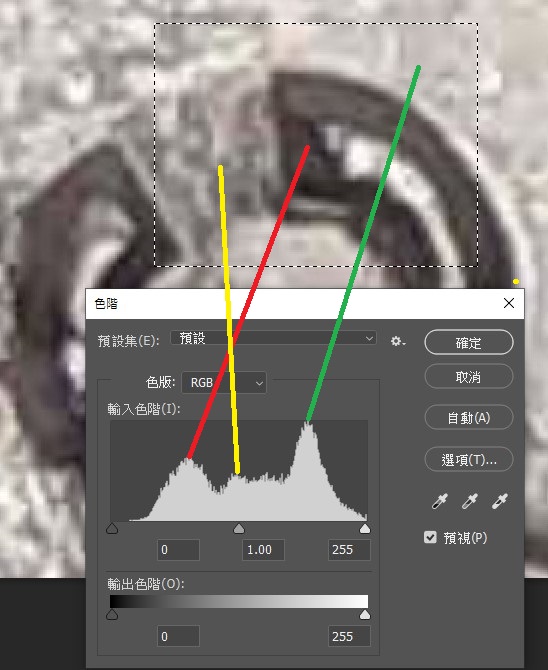
上圖右方的二值化切割是以全圖為基礎做的,大致上可以幫我們鎖定可能的目標了!如果我已經知道有個字在那裡,我可不可以縮小演算邏輯的範圍?更精準地找到多深的顏色是字?多深的顏色是背景?以及多深的顏色是缺口內的雜訊?下面這張用PhotoShop做的色階分布圖就可以說得很清楚了!綠線指示出背景色的峰值,紅線是字的筆劃峰值,黃線就是我希望鎖定排除的雜訊了!知道它的顏色概略範圍當然就可以清除它了!
如果我能掌握精確的數學在已經切下的目標區內做上面的分析,更局部區域精準的排除那個缺口內的雜訊,而不會損失真正的目標,我就成功了!下面就是有沒有做目標內的再度二值化的差異,當然已經經過旋轉縮放到標準字模的大小了。
左邊未處理的狀態別說是看成G了?看成0或O都很可能,只是被我的已知字串資料庫排除了是0或O的可能性,剩下可能的字元中,它比較像G而不像C,所以答案就判斷錯了!但是經過縮小區域更精準的第二次二值化之後,缺口的障礙物清掉了,當然就沒問題確定是C了!如下圖,不但辨識正確了,那個字串的得分(符合度)也從78變成81了!表示辨識的可靠度確實提高了!事實上這個處理程序加入之後,即使答案一樣的分數都提高一兩分了!
所以要「看清楚」字元,不是只能做一次二值化!第一次的全圖二值化目的是幫你找到目標的概略位置,鎖定單一目標之後你可以嘗試「把它看得更清楚」,數學上就是在更小區域,更針對性的二值化處理了!影像辨識就是那麼有學問,那麼好玩!最重要的是:我們用眼睛看東西的過程也是這樣的!我的AI哲學就是模仿人眼的認知過程,在此再一次得到印證! |
|
| ( 知識學習|科學百科 ) |