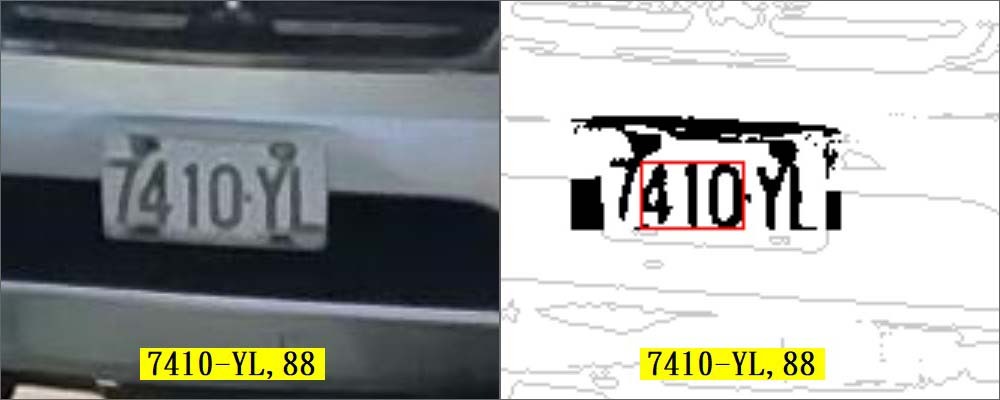

這種狀況的車牌,曾經是我很多年間會感到扼腕心痛的無法辨識案例!因為以人眼辨識是很容易得到確答案的!但是經過OCR辨識的SOP呢?六個車牌字元我只能正確抓到三個字!直到去年我都還是堅持:三人不能成虎!必須找到四個以上成排的目標才會進入正式的車牌辨識程序,去修正或補足車牌字元。
為什麼我會堅持要四個成排目標才開始把它當個車牌來處理?原因是在複雜的背景中達到三人成虎門檻的組合太多了!會消耗太多運算時間!而且從殘缺資訊硬是拼湊出來的答案也多半是不可靠的,誤報率就會偏高了!其實多數現有的車牌辨識技術是直接搜尋整個車牌區域特徵的!但我都試過各有優缺點。
既然我已經選擇以辨識個別字元為尋找車牌的切入點,當然最低字數的門檻越低遺珠之恨就越少!譬如上例在兩年以前的版本是根本不會進入車牌辨識程序的!但因為客戶的眼睛看得很清楚,其他廠牌用CNN的方式找車牌也一定不會錯過!我的軟體卻是視若無睹?那就很不好意思了!所以在巨大的壓力之下,我決定要讓三人就成虎了!
當然正確的車牌不可能只有三個字,所以接下來的工作就是內插或外插遺失的字元了!三個字元雖然不多,但是已經足以提供統計學上算是可靠的統計值了!譬如這個車牌中字元應有的寬度與高度乃至傾斜度等等。有了這些參考值我就可以按圖索驥,在既有確認的字元前後或之間地毯式搜索找出太模糊破碎或與背景沾連的字元了!
但是我上面說過了,太耗時與太多誤報的狀況如何解決呢?其實就是要更充分的用上我們人眼識別車牌的智慧或常識了!就是在嘗試拼湊車牌的過程中也不斷自我檢視,如果發現某件事或某個特徵可以否決此案例是個車牌的可能性,就必須馬上放棄!傻事不要做到底,時間就不會浪費太多,誤報結果也會少了!
所謂的「地毯式搜索」其實就是CNN了!用從三個以上已知字元獲得的資訊設計合乎字元大小的矩陣去字元之間與前後端掃描就對了!因為實施的範圍極小,所以不會耗時到需要GPU幫忙的!如上例一就是可以很快找到前面有個7字,後面有兩個Y與L字元!上例二則是內插找到一個0,再往前外插找到D與P!
所以理論概念說清楚了就一點都不神秘了!但是我會怕別人學師?把我的技術整盤端走嗎?不會的!理論概念只是一個起點或切入點,我自己有這個想法之後,要把所有細節都處理好實作出來也要花上一年半載精雕細琢的!如果沒有我扳手扳腳的指導,任何人要實作一樣的軟體都會跟我一樣或更困難的!在跟隨者努力期間我還會繼續進步的!我不擔心馬上就失去領先優勢。
我想表達的重點是:好的影像辨識必須建立在合理精確的演算法理論之上!只是盲目的經過資料統計磨合訓練出來,根本沒有精確解題邏輯的「模型」不可能很AI,不可能有智慧的!不必幻想XX學習可以做到我的這種等級的影像辨識!根本連門都沒有!如果你還是相信?你就是無可救藥的最好騙的肥羊了!




 字體:小 中 大
字體:小 中 大






