字體:小 中 大
字體:小 中 大 |
|
|
|
| 2025/01/14 08:00:33瀏覽534|回應0|推薦11 | |
我們是一個以影像辨識軟體研發為業的公司,從一開始就是從已經發展大半世紀的傳統影像處理與影像辨識技術出發!根據需要辨識的目標實例,一板一眼兢兢業業的研究傳統技術的優缺點,再逐一根據辨識的需要與舊方法的缺點改進演算法,也不斷加入新的創意,讓傳統演算法變得更精準也更快速! 以我們的主要產品車牌辨識來說,就是以傳統的OCR技術為主軸!上圖就是我日常研究車牌辨識的研發軟體介面中的截圖,可以看出我們是非常嚴謹精密的在做研發,每一個從原圖到辨識成功的過程,都可以檢視到每一個畫素的精度!每一步驟使用的時間與次數也都精準掌握,所以才能做到最高的準度與速度!我們從來就不是靠甚麼密技?或運氣?獲得優勢的!就是嚴謹精密的科技研究而已!
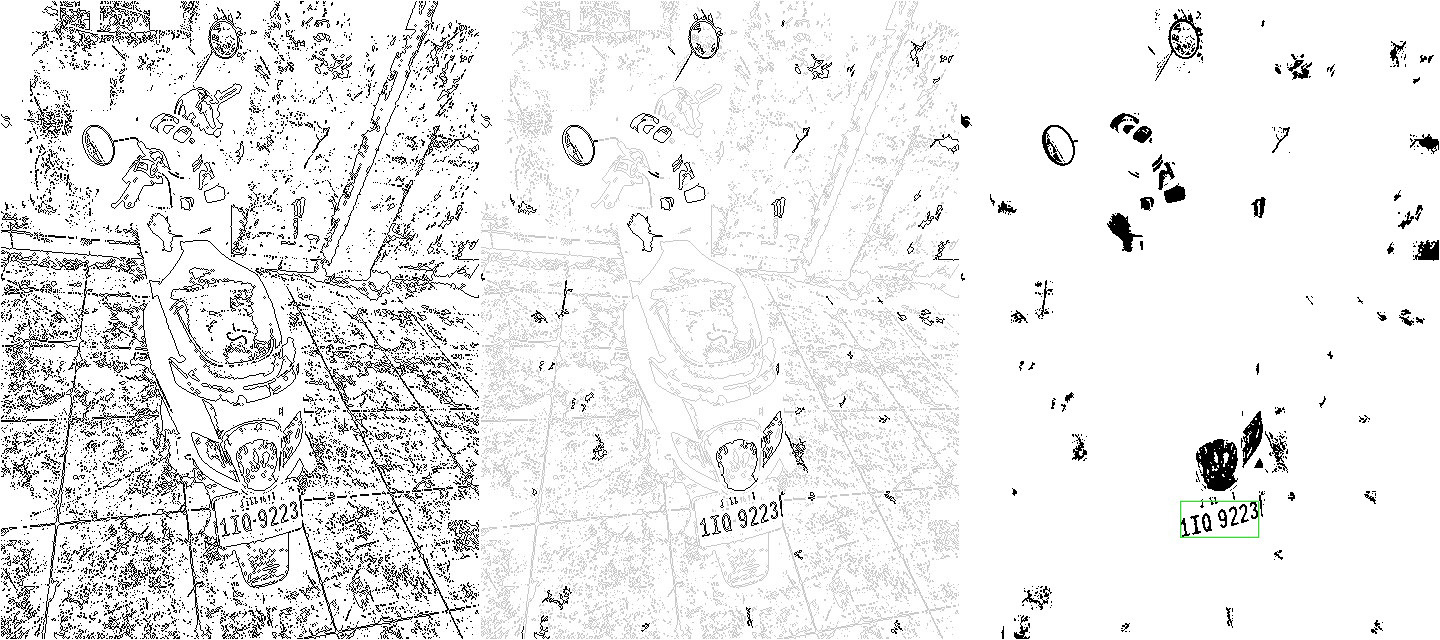
面對現在非常強勢的ML、DL與CNN等所謂的AI技術大舉入侵影像辨識領域的浪潮,我們總是帶著非常戒慎恐懼的心情面對!在商言商嘛!如果這些技術真的比我們之前使用的技術更好,不必懷疑,我們一定會立即改用新技術!畢竟做出精準快速的辨識軟體才是目標,也才是我們公司繼續在業界生存之道!本位主義?學派之爭?那是愚蠢的學術界人士才會有的堅持。 所以在繼續使用傳統技術研發的同時,我們也持續學習研究與觀察ML、DL與CNN等新技術的發展,甚至要求我的RD去讀研究所學習AI新知!所以至今尚未改弦易轍使用這些新技術,絕對是以非常嚴肅嚴謹的科學態度做出的決策!我們至今只在一些細節步驟上引用了一些這種以統計學為基底的新技術,用來處理真的無法精準掌握的模糊狀況。 我們沒有跟隨ML、DL與CNN主流浪潮的原因是很明顯的!我們既有的技術本來已經像是運作良好,穩定且快速的精密儀器!如上的四格漫畫就是我們的前置處理作業,就是簡化影像抽取有助於最終得到車牌內容的特徵抽取過程,也就是傳統的:全彩→灰階→二值化→輪廓線! 從灰階產生的過程就已經針對強化車牌字元的對比做了最佳化!二值化過程也是根據區域亮度做動態調適的,所以位於較暗陰影區或亮度太高區域的車牌都可以被穩定凸顯出來;輪廓化則是準備用來取得目標的形狀與範圍,若直接用黑白二值化圖來找目標,就會需要處理太多區塊內部的黑點,浪費時間又無助於取得我們想知道的字元目標形狀,追蹤輪廓線就足以圈出目標,速度快多了。
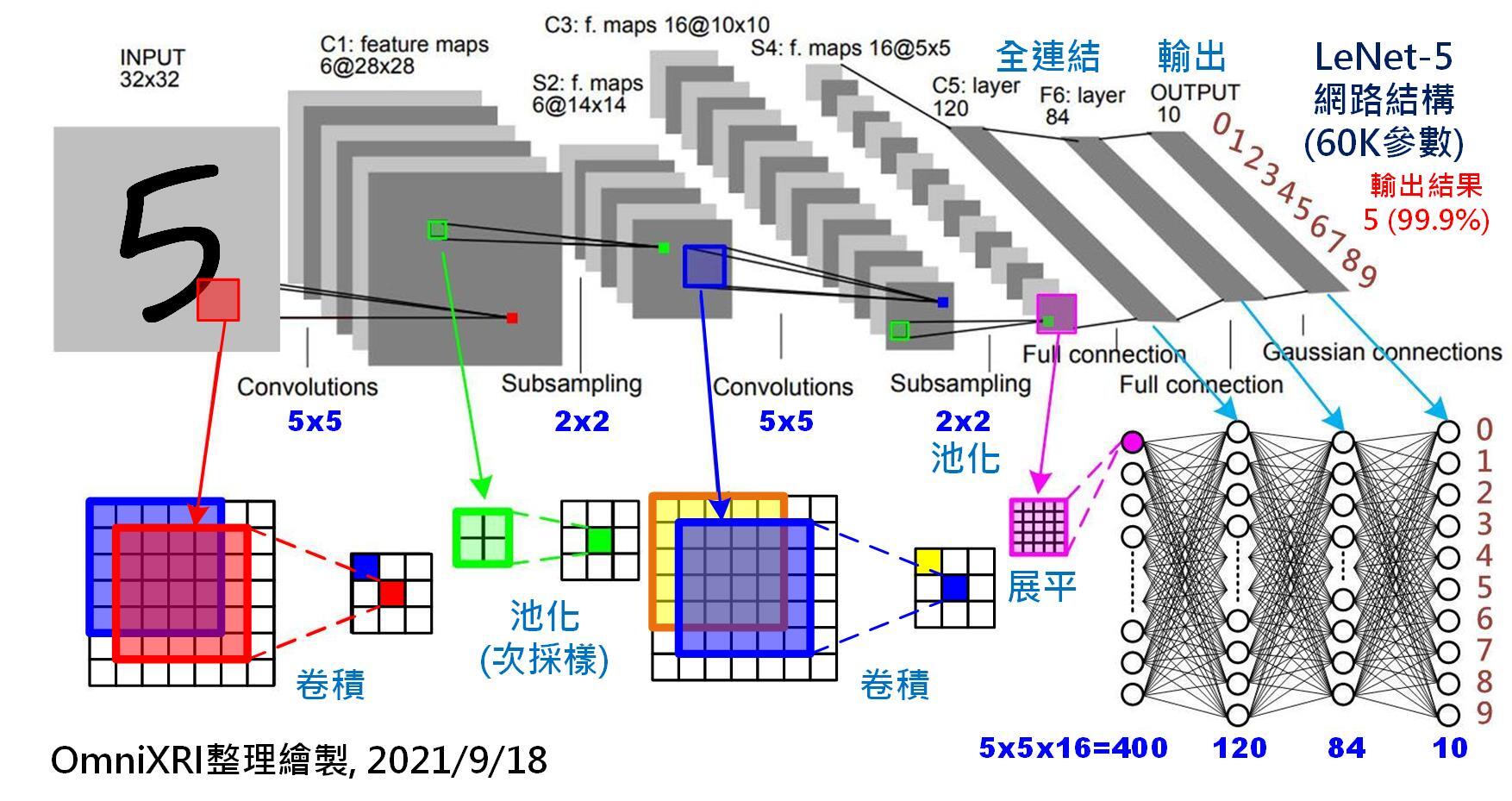
相較於上圖基於ML、DL與CNN技術的辨識架構,我用的辨識過程最大的特色是:完全不必做任何矩陣的疊加或掃描等耗費計算量的運算!這就是我們與CNN最大的區別!CNN的前處理取得特徵資訊的過程就是Convolution(卷積運算),非常消耗計算資源,所以他們非得依賴GPU的螞蟻雄兵才能勉強跟得上傳統運算的速度! 這種矩陣掃描運算的架構,也是YOLO所以被AI支持者稱頌的原因,因為YOLO就是在CNN的基礎上努力嘗試減少運算加速的技術,但是他們不願面對的是:很多時候其實也可以用傳統方式取得辨識需要的特徵,根本不需要做Convolution的運算過程,而且速度比任何YOLO運算量更少也更準更快,這就是我在做的事情!以我們舉的這台機車的車牌辨識為例,前置處理只需要14毫秒!也就是0.014秒!
看到上圖中密密麻麻的輪廓線可能會嚇到很多人?但是我們可以用氾濫式演算法直接「追跡」這些亂絲,很像小朋友玩的連連看遊戲,很快就可以分析出所有相連的獨立線團,也就是二值化黑白圖上的一個一個色塊目標,然後根據它們的形狀、大小及每個目標前景背景的對比強度,篩選出可能的車牌字元,再嘗試將它們群組成可能的車牌組合,以此例來說這些過程也只需要8個毫秒!
接下來就是把從原圖切割出來的車牌區域影像當主角繼續處理了!首先是將車牌本身與每個字元都盡量用幾何學的公式技術處理轉正!再一一縮放到標準字模的大小作字元符合度的比對!具體的車牌內容答案就跑出來了!這些聽起來很複雜的過程所需時間以此例來說也只需要4個毫秒! 當然有可能全圖中會出現好幾個車牌候選人,可能是真的數個車牌,也可能只是跟車牌相似的幾何形狀或非車牌的字串,我們最後還需要根據上述字元辨識的結果參數審核哪個是真的車牌?哪些必須排除?這段程序需要的邏輯判斷原則很多,但沒有甚麼迴圈運算,處理時間通常不到1個毫秒!所以最終在我的一般規格電腦上,不需要GPU的助拳,就可以用25毫秒的驚人速度辨識成功!
我歡迎任何人拿一樣的影像用任何技術製作的車牌辨識軟體做比較!如果可以更快,非常歡迎來踢館打臉!我甚至會考慮奉送我的一套軟體!好像金庸小說中說的獨孤求敗,我也是一個研究影像辨識的武痴!如果知道有任何技術可以做得比我更好,我一定會虛心求教的!以商業的考量,當然也是追求更好的產品才是我的生存之道! 相對我的追求精密精準與效率,ML、DL與CNN的問題就是基於統計學的原罪,需要的資料量大、需要的計算量更大、還不保證精準,每個細節過程都會加入統計資料的不確定性,最終就是要花很多錢買資料處理資料,花很多電腦時間、硬體成本與耗電作巨量的計算,計算的結果還只是統計學上妥協出來的「最適」解答!根本不是精密穩定的最「合理」準確的解答! 所以我始終沒有投入資源嘗試使用這些所謂的新AI技術來取代我既有的做法!這是完全根據科學理解做出的決定!也讓我的產品持續保持效率高與成本低的雙重優勢!我非常樂意提供這些心得與經驗供大家分享參考。
|
|
| ( 心情隨筆|工作職場 ) |