字體:小 中 大
字體:小 中 大 |
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2018/06/28 11:23:08瀏覽1155|回應0|推薦0 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
第四節 產品開發對金融計算的要求 金融市場是一個充滿隨機性的地方,自從BSM模型被提出之後,隨機過程被用於各個金融變數之上,不論是匯率、股價、利率、商品價格,甚至信用價差,都是以適當的隨機過程,進入到財務模型之中。透過金融市場的均衡條件,我們便會求得這些金融變數的隨機微分方程(Stochastic Differential Equation)。這一方法以成為目前金融產品開發時,計算其價格與風險的標準程序。 隨機微分方程一般化的求解方式,可以使用測度轉換的方法求得。在特定條件下,少數的隨機微分方程可以有解析解,如陽春型選擇權。但是,就如目前市場上銷售的外匯結構產品Target Redemption Notes,大部分由於償付條件過於複雜,且是路徑相關的條件,因此無法求得簡單的解析解。此時我們只有利用蒙地卡羅模擬法配合測度轉換的理論,使用大數法則來計算這些產品的價格與風險。 在蒙地卡羅模擬法中,我們進行大量的模擬,每一次的模擬就是一個可能的情境路徑(Scenario Path)。實務上,10萬條的模擬路徑是一般的要求,但這只是計算一個價格。通常我們還需要計算Delta、Gamma與Vega等參數,以做為避險的規劃與涉險值的估算。由於沒有解析解,因此需要使用差分來求的這些數值。保守估計,一個產品需要計算四個模擬價格,也就是40萬條的模擬路徑。如果在每條的情境路徑上,每天走一步,產品為一年到期,則每一產品我們一共需要產生約1.5億個模擬亂數(365╳400,000=145,600,000)來執行相關計算。 上述情況在金融計算上並非特例,在一些利率類的結構產品上,情況更為嚴苛。這是因為在外匯產品上,通常只需要模擬一個匯率因子。而在利率類的結構產品上,可能同時要模擬20個利率因子。至於整體公司部位的風險值計算,那就又是另外一種各加嚴苛的情況,以現今大型銀行的資產組合規模而言,計算能量的要求只有更多了。 然而,多核的硬體結構卻是當今金融計算的一個解藥。傳統個人電腦只有一個計算核心的CPU,因此,同時只有一個程序(Process)在執行。當CPU中的計算核心數目增加後,我們可以使用多執行緒(Multi-Threads)的方式,增加計算能力。也就是說在一個主程序執行後,我們可以將主程序展開程多條的執行緒,分別使用每一個計算核去執行各自的工作,最後再合併到主程序來結束。 然而,這樣的做法前提是這些展開的執行緒彼此的工作有一定的獨立性,可以各自工作,到最後才需整併合一,否則這樣的計算流程變沒有辦法提升計算效率。對於前述的蒙地卡羅模擬法,就剛好滿足此一要求。因為每一次的情境路徑模擬,都是各自獨立執行的,這可說是王八看綠豆,對上眼了。 然而,即使可以在CPU內增加計算核(Core)的數量,但是目前CPU最多也只有8個計算核(AMD),似乎緩不濟急。自然而然,就會想到GPU上大量的計算核心,是否可以成為可用的方案。這裏要說明一點,CPU上的核是通用型的,除了數值運算還有邏輯運算,因此無法像GPU上的專用型核,可以製造那麼多的核。 NAVIA公司於2007年正式發布其泛用GPU(General Purpose GPU)架構,計算統一裝置架構(Computer Unified Device Architecture, CUDA)。在此架構下,程序員可以使用一般的C語言,撰寫執行於GPU上的程式,充分利用GPU多核特性的平行運算程式。自此,摩爾定律的計算紅利,又可以為金融界所共享。
第五節 市場上主流的GPU平行運算架構 目前市場上平行運算的軟體開發架構有兩大類,一類是以CPU的多核架構為主,另一類則是以GPU的多核架構為主。由於金融計算的高運算量,本文著重在後者的架構。市場上GPU的多核架構亦有兩大架構,分別是NVIDIA的CUDA架構,以及由Apple公司提出並得到多家開發商支持,並由Khronos Group設計的開放計算語言(Open Computing Language, OpenCL)。 CUDA是一個專屬於NVIDIA公司的開發架構,因此只支援NVIDIA的GPU顯示卡。由於NVIDIA介入此一領域較早,因此他所提供的工具較為齊全。CUDA所提供的程式庫有BLAS、FFT、Random三大類。另外,CUDA亦提供整合於微軟開發軟體Visual Studio的除錯工具,可以在除錯模式下觀察GPU內變數的變化。另外,除了C語言,CUDA也提供了C++的支援程式庫Thrust。整體而言,CUDA的開發資源相當地好。 OpenCL是近來由Khronos所推出的一個異質性計算的開放架構(註六),他可以同時使用CPU與GPU的資源,他也不限於單一公司的硬體架構,因此不論是AMD、NVIDIA的GPU或是Intel、IBM的多核CPU,都可以支援使用於此架構之下。然而,OpenCL在程式庫的支援方面,相較於CUDA比較不完整。但是基本的BLAS與FFT程式碼,依然可以由AMD的網站上免費取得。另外,AMD也推出C++語言的支援程式庫Bolt。 不論是CUDA或是OpenCL都是以C或C++語言為基礎的開發工具,對於已.NET平台為主的微軟平台,整合度都不是很理想。幸運的是,網路上都有提供相對應的.NET版的開發工具,ManagedCUDA與OpenCL.NET。這兩套工具皆以C#語言封裝原來的程式庫,可以完整的整合到Windows平台系統。 上述的軟體皆是免費的工具,至於付費的商用軟體也有很多選擇,尤其是CUDA的部分,NVIDA的網站https://developer.nvidia.com/cuda-tools-ecosystem有相當多的資訊可供查詢。
第六節 一個比較範例 相較於CPU,使用GPU做為特定運算的運算中心,其優勢是相當明顯的。下面作者以一個陽春式選擇權作為範例,比較這兩種方法的計算速度,以及計算得精準度,由於此種選擇權有解析解,因此可以解析解的質為比較的根據。 此選擇權的契約條件如下,一年後到期買權,令期初資產價格S0=100,執行價格K=100,波動性σ=30%,融資成本4%,資產收益2%。。令K表執行價格,ST為到期日價格,CT表到期日選擇權的的償付,
使用BSM公式解,可得權利金價格為12.567697。 在實作條件上,我們使用簡單的幾何布朗運動程序,每天模擬一步,因此一條情境路徑需要走365步。每一次的計算模擬262,144條情境路徑。 首先,我們以CPU執行單執行緒的傳統程式,作者使用的硬體開發環境為Intel Core i7-3770@3.4GHz,8G RAM,作業系統為Windows 7專業版32位元的作業環境,以C#為程式語言,使用Mersenne Twister亂數產生器,編譯後執行三次結果如下,
由於使用相同的亂數種子,因此三次計算的權利金皆相同。三次計算的平均時間為8.7360223秒。 接著,我們使用CUDA架構來測試平行運算的執行效果,測試的GPU為NVIDIA Geforce GT640,3GB RAM,CUDA Driver 6.0/Runtime 5.5。使用C#語言搭配ManagedCUDA做為開發工具,其他環境與前面相同。在亂數產生器方面,使用CUDA內建的CudaRand程式庫。此處的計算時間不包含CUDA程式的編譯時間。
由於使用相同的亂數種子,因此三次計算的權利金皆相同。三次計算的平均時間為1.1700016秒。相對計算效率約為7.5倍(8.7360223/1.1700016=7.4666)。 最後,我們使用OpenCL架構來測試平行運算的執行效果,測試的GPU為NVIDIA Geforce GT640,3GB RAM,OpneCL Driver 1.0。使用C#語言搭配OpenCL.Net做為開發工具,其他環境與前面相同。在亂數產生器方面,我們使用Random123亂數產生器。此處的計算時間不包含OpenCL程式的編譯時間。
由於使用相同的亂數種子,因此三次計算的權利金皆相同。三次計算的平均時間為0.1433335秒。相對計算效率約為14.1倍(8.7360223/0.6200009=14.0903)。 整理摘要如下,多核運算有明顯的效益,相對單核的模擬,多核的模擬誤差並不會明顯的增加。在OpenCL的模擬中,使用Random123的亂數產生器,甚至可減低模擬誤差到1%以內。
*使用BSM公式解,可得權利金價格為12.567697。
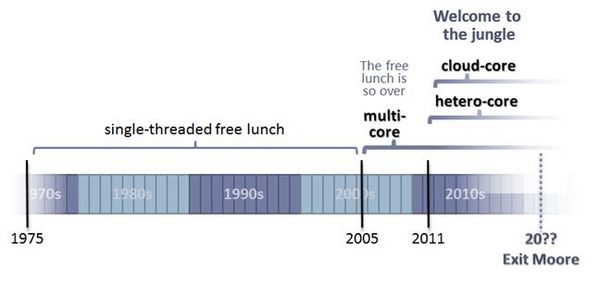
第七節 本書的內容與目標 自從1973年Black、Scholes與Merton提出了著名的選擇權訂價理論,將隨機程序模型引入了金融市場,這40年來的發展已經進入到不同的階段。如今大量的數學模型出現在新產品的開發模型之中,數值模擬已成為計算價格與風險的主流。如何進行快速有效的運算已經不是一個理論問題。銀行做為一個金融創新的研發中心,以及這些新創產品生產、銷售的工廠,需要大量的計算能力。 在實務工作中,從事財務工程的工作必須仰賴電腦程式的使用。程式語言的使用是工程師基本技能。所有理論的了解,需要以程式的方式展現出來,而所有工作的完成,也是在程式上解決。然而,程式的撰寫卻是目前大多數商學訓練的不足。因此,作者先以第一篇的內容,配合傳統的Black-Scholes模型,以C#語言說明如何撰寫基本單線程的程式。 在進行複雜的數值運算中,有些數值方法對於一般商學學生,往往不容易自行開發計算模組。鑒於統計軟體R提供簡單的操作介面,而且R本身是開放軟體,可以免費使用,作者便以R做為輔助使用的工作加以介紹。然而,使用R還有更深一層的考量,在開源軟體中,已有R的.NET免費版本,RdotNET可以整合到C#的開發環境。這對軟體的開發,提供了無縫接合的使用。我們在第三篇中可以看到使用的案例。 然而,隨著財務理論的發展,以及市場的演進,傳統的Black-Scholes模型已經不足以解釋市場的複雜情況。針對權益類與外匯類的資產價格,市場上目前較可接受的模型,是以隨機波動性為主流的相關延伸模型。這些模型都是以Heston(1993)的模型為基礎,在進一步的擴充,包括時變參數隨機波動性模型,具跳躍性質的隨機波動性模型,或是隨機局部波動性模型。 本書打算以Heston(1993)模型為出發,做為現代財物模型的出發點,一方面可以銜接大多數讀者在碩士班學習Black-Scholes模型的基礎,另一方面也足以做為市場實務應用的初步基本模型。因此,在第二篇中,作者將仔細介紹Heston模型以及在商品開發的應用情況。 平行運算已是業界使用的重點, CPU的平行運算在.NET架構下,已經相當成熟易用,本書將在第三篇介紹這一主題。 然而,如果想要充分使用平行運算的效益,則GPU上的編程是不可或缺的。本書將在第四篇介紹這一主題。 對於打算進一步學習的讀者,我們將在第五篇中提供兩個重要的學習對象。QuantLib程式庫中,對於重要的財務模型,都有實作的程式碼可供學習。至於如何充分應用GPU的效能,則可以Kooderive程式庫中做為範本學習。Kooderive是Mark Joshi教授將單線程的QuantLib轉寫為GPU的一項成果,值得有志之士好好參考學習。 著名的程式語言專家Herb Sutter,在其2005年的專文“The Free Lunch Is Over"指出,電腦業的主流計算已經撞牆了(Hit the Wall),他認為唯有將單核的CPU主流機器轉向到多核的CPU主流機器,並且從作業系統到開發工具全部轉換為多核的模式,程式開發人員才有可能繼續享有摩爾定律的紅利。 自2005年開始,電腦產業將個人平行超級電腦放在每一台桌上型電腦,到2011年即使手持裝置也已完成此一轉換。到了2012年,8核CPU已出現在主流平板與桌上電腦之中。下圖中的異質性核(Hetero-core)所強調的是,GPU的多核能力是我們必須重視的資源,因為很多的電腦與手持裝置都已安裝了GPU。最後是雲核(Cloud-core)的應用,指的是如何使用雲端服務的計算效能。
Herb Sutter在其2012年專文“Welcome to the Jungle"中提到,如果我們想要在交付軟體之後,繼續享有除了在目前硬體環境的高效能外,還可以在未來更好的硬體環境下享受更高的效能,則我們目前開發的應用程式就必需要有平行運算的潛能,可以橫跨各種不同計算核心的能力,包含本機與分散的,大型、小型與專用型的計算核心。 第八節 附註 註一:A. P. Chandrakasan, M. Potkonjak, R. Mehra, and J. Rabasey, and R. W. Brodersen, “Optimizing Power Using Transformations,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 14, no. 1 (January 1995): 12-31。 註二:CUDA C Programming Guide, CUDA Toolkit 5.5, NVIDIA Corporation。 註三:http://blogs.nvidia.com/blog/2012/07/02/new-top500-list-4x-more-gpu-supercomputers/。 註四:Mike Giles, From CFD to computational finance (and back again),MIT Center for Computational Engineering, March 14, 2013。 註五:http://www.nvidia.com.tw/object/computational_finance_tw.html。 註六:https://www.khronos.org/opencl/。
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ( 創作|其他 ) |