
問題描述:
詮力的簡訊發送平台使用了SQL Server做為平台資料儲存的資料庫,但當大量發送的交易資料日漸變多時,不定時的在SQL Server記錄檔裡會出現『SQL Server has encountered XXX occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [X:\XXX\XXX.mdf] in database id XX. The OS file handle is 0x0000000000001AF0. The offset of the latest long I/O is: 0x00000a9ef02000. The duration of the long I/O is: XXXXX ms.』的警告訊息(如下圖1),看到此警告訊息代表的涵義是I/O寫入延遲超過15秒,也代表此時平台將資料寫入資料庫的時間變久,甚至導致平台在執行SQL語法時有逾時的錯誤產生。

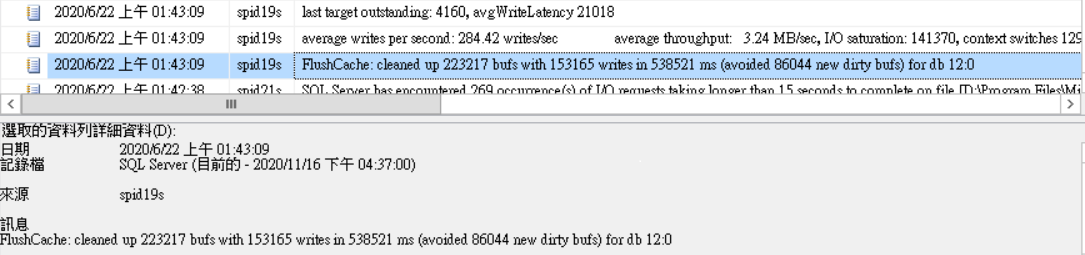
為了找出此警告訊息發生的原因,我們反覆查詢了SQL Server記錄檔裡前後的訊息,發現在I/O寫入延遲超過15秒前,會先出現幾次『FlushCache: cleaned up XXXXXX bufs with XXXXXX writes in XXXXXX ms (avoided XXXXX new dirty bufs) for db XX:0』的訊息(如下圖2),其相關性是訊息2的發生不一定會造成訊息1的發生,但訊息1的發生一定有訊息2的出現。且經過一段時間的觀察後,發現訊息2通常在進行資料庫維護工作-索引重建時或有大量交易資料寫入時發生。
接著在網路上尋找FlushCache的說明資料(Ref 1, Ref 2),得到了以下結論:
FlushCache的運作方式:
因硬碟速度慢,記憶體速度快,故SQL Server利用Cache將常用的資料儲存在記憶體內。 每當資料寫入或從 SQL Server 資料庫讀取時,緩衝區管理員都會將其複製到記憶體中。Buffer Cache將分配給它的記憶體,盡可能的保存資料。當Buffer Cache填滿時,也會清除較舊和較少使用的資料,讓新的資料能放入Cache。 儲存在Cache裡的資料,可區分為clean page和dirty page:dirty page是自上次寫入磁碟後有更改的頁面;clean page則是未更改的頁面,其中的資料仍與磁碟上的內容相同。SQL Server會定時發出checkpoint的動作,該檢查點會將dirty page寫入磁碟。
大型記憶體的挑戰:
隨著記憶體的容量越來越大,這個檢查點的實作需要花費越來越多的時間,因為它需要掃描整個Buffer Cache,以12TB的記憶體為例,即便沒有任何dirty page,也需要花12秒掃描完。 SQL Server 2016使用了Dirty Page Magager(DPM)來解決此問題,但仍保留了一些情境是繼續使用FlushCache(如下表1)
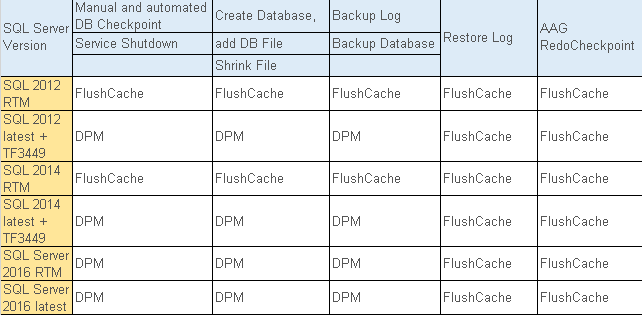
而我們的情境剛好是遇到了Always On Availability Groups (AAG),導致仍繼續沿用了舊的FlushCache技術,而非DPM技術,而且更重要的問題是checkpoint除了在主要伺服器執行外,也會在次要伺服器執行,所以設計成互為備援的幾台資料庫,因為它們的mdf都放在相同硬碟,反而變成互相干擾效能。
解決方案:
最後整理出兩個方案來解決資料庫I/O延遲的問題:1.將Always On的資料庫搬到不同硬碟,讓互為備援的伺服器不要在互相影響;2.將索引從mdf移到ndf,並另存到不同硬碟,因為交易資料異動時,索引的資料也會一併異動,將資料與索引分開來,也可降低對硬碟的影響。
Ref 1: https://www.businessintelligenceinfo.com/business-intelligence/bi-news-and-info/sql-server-large-ram-and-db-checkpointing
Ref 2: https://www.sqlshack.com/insight-into-the-sql-server-buffer-cache/
Ref 3: https://www.quest.com/community/blogs/b/database-management/posts/buffer-cache-what-is-it-and-how-does-it-impact-database-performance




 字體:小 中 大
字體:小 中 大






