字體:小 中 大
字體:小 中 大 |
|
|
|
| 2025/06/29 03:36:31瀏覽719|回應0|推薦5 | |
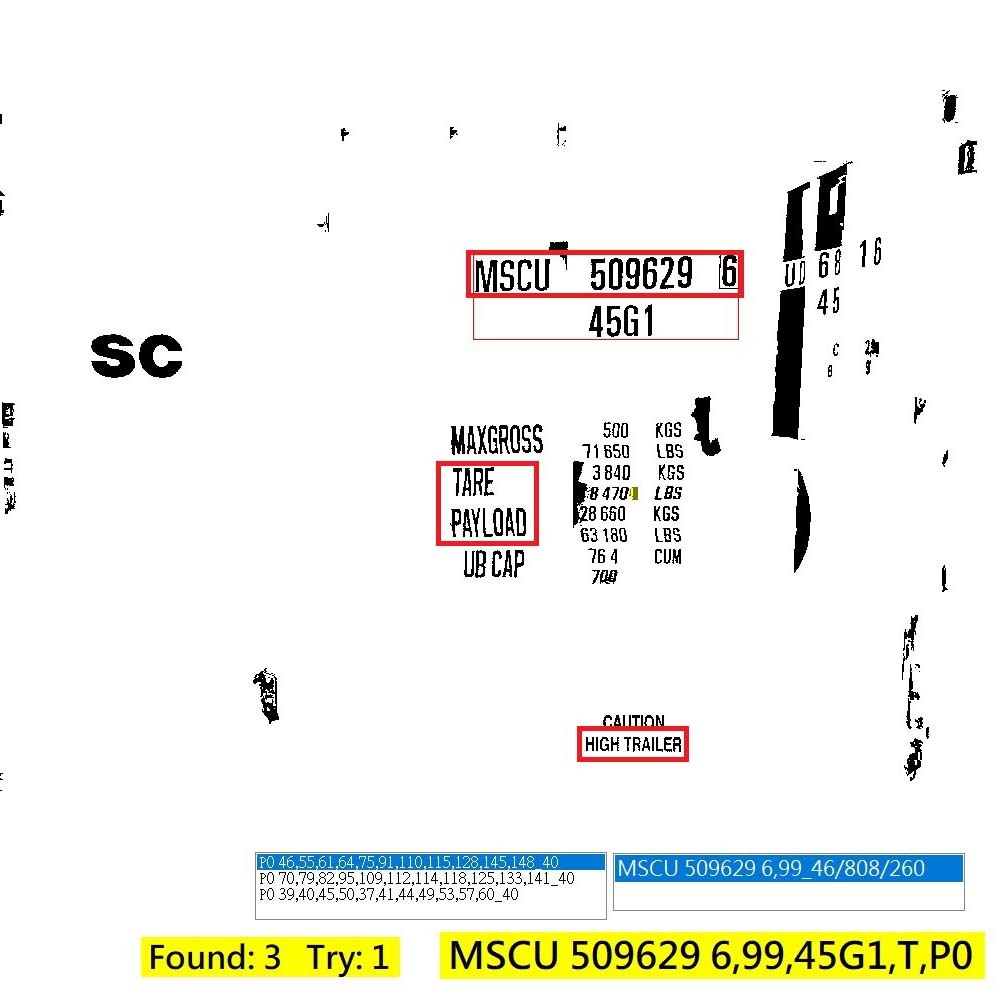
上面是我找到複雜影像中正確貨櫃碼的一個實作案例過程,事實上也非常接近一般人眼視覺判斷的過程!我們都會在找特定目標時先預想好:「要找甚麼?」然後設法簡化與抽象化原圖的資訊,組織或過濾出「可能」的幾個目標,再從這些候選人中進一步細看特徵,分析與評審找出最佳的答案! 如上案例就是會找到三個可能的目標群組,它們都有11個字,符合貨櫃碼的字數,排列方式也符合貨櫃碼可能的三種方式之一,包括:一長橫列、4與7碼二橫列、或11碼一直列!這一階段是只看目標大小形狀與排列方式,還沒「細看」每個目標的內容是甚麼字?所以計算量不大,速度是很快的! 其實這種辨識最耗時的是確認每個目標到底是甚麼字?因為這必須一一比對數十個英數字的字模,找到符合度最高的那個字,如果目標有傾斜變形還必須先做幾何校正,所以為了節省計算資源,我都是先盡量縮小必須啟動字模辨識程序的目標範圍,如果數百個可能的目標都來比對字模,那就會慢如蝸牛了! 所以如何用目標排列方式群組找到可能的貨櫃碼或車牌,是個非常重要的步驟!從二值化目標切割獲得的幾百個零散目標,到有意義的如上案例的三個可能是貨櫃碼的群組,在我的程式中會稱為Align或Group,有點像打麻將找出有意義的特定組合?也很像是實現幼稚園小朋友的連連看遊戲的演算過程!過程很有趣,但是除了我自己寫的書從來沒看過任何文獻深入討論介紹過?說穿了只是這些數學沒有甚麼美感,寫成論文不漂亮而已!不是很難或很神祕神奇! 其實CNN的演算法也是強調模擬人類視覺智慧與思考方式的!但是實際看它們的具體做法卻與我的想法差距極大!關鍵就是他們自己設定了一個矩陣的框架,把如上述「要找甚麼?」的過程簡化成以一個特徵矩陣呈現?就是所謂的Kernel與Convolution了!如果堅持這個框架就不可能做到我做的這些事情了! 所以很遺憾的CNN與OCR兩種演算方式是不可能互相包含或整合的!這或許不是壞事,我們只須讓它們各自發揮最大的功能,各自做最適合它們做的事情就好!顯然像辨識車牌或是貨櫃碼這種事情就極度「不適合」用CNN了! 因為用OCR的方法完全不必經過非常耗時的Convolution就可以得到位置形狀都更精確的目標,再經過合理快速的群組化,答案就呼之欲出了!反之,CNN的特徵矩陣要直接辨識出多樣化的貨櫃碼目標群組是不可能的!辨識出個別字元呢?又太耗時了!即使辨識出每一個字元,還是必須群組化才能得到有意義的答案。那為何不直接用OCR? 現在在影像辨識的領域,大多數人都已經太早放棄或低估了OCR等較傳統的影像辨識技術,太過高估CNN與DL了!大家必須知道CNN與OCR有著非常大的本質差異!CNN是理論上就永遠無法取代或整合OCR的能力的!所以我的看法建議是兩者都不應該偏廢! 我的研發產品多數是以OCR為基礎的!OCR並不完美,但還有很大的進步空間,我的實績就是奠基於我讓OCR更進化了!主要有兩個部分:其一就是如上例的更聰明的目標排列群組化技術!其二就是之前介紹過很多次的目標因為視角傾斜變形時的幾何校正技術!這些都是CNN與DL根本無法取代的功能! 所以不要再相信那些攏統含糊的技術意見說哪種技術一定比哪種技術好?也不要輕易相信哪種演算法可以取代哪種演算法?事實上就是各有所長,我們最聰明的做法就是好好讀書做實驗掌握所有可用演算法的精髓,該用甚麼演算法就用甚麼演算法,不要被半吊子AI專家或玩家耍得團團轉! |
|
| ( 心情隨筆|工作職場 ) |