字體:小 中 大
字體:小 中 大 |
|
|
|
| 2023/02/14 05:15:09瀏覽2324|回應0|推薦10 | |
我天天在做各種車牌辨識的個案分析研究,真實世界的變化太豐富太有趣,要我每天寫一篇報告,甚至論文!我都有足夠題材的!其中一個很基本也重要的觀點是:「影像是立體世界的平面投影!」如果你的目的是辨識真實目標「原來」的樣貌與意義,當然必須知道你在影像中「看到」的樣子只是一個3D物體的2D投影,也就是扭曲過的形象,你必須設計演算法「復原」這個影像到接近原始的樣貌! 譬如一個N字如果橫著拍就是Z了!如果你拿著N的字模去找影像中的N,但是拍照者拍成45度傾斜的N,你就根本找不到目標了!又或者那個N大到比人還高,超出你預期的N的大小,你也會「身在N中不知N」了!所以正確的物理認知與幾何校正過程不重要嗎?不但很重要,還很不好做!應該是影像辨識過程中的重中之重,絕對不是可以一筆帶過輕描淡寫的!
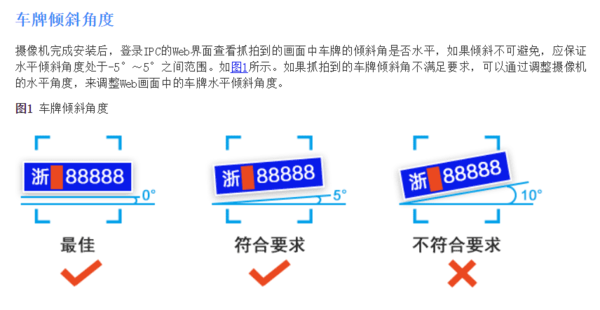
如上的案例其實就有好多故事可以說!台灣七碼車牌字型的V與W本來形狀就有點像,加上斜視讓字變得瘦長,且距離稍遠畫素較低時,在數學上要準確區分它們並不容易,但是我的辨識核心如上的狀況依舊可以正確分辨,不會說成是AVV?或AWW?關鍵就是很合理精準的影像幾何校正過程!但是車牌字元區的四個邊可以是任意角度的,不必是矩形哦?如果我畫錯了,譬如以為A的左斜邊是車牌的邊界,那麼修正出來的A就會倒向左邊了!像這樣:
大家不要小看了上面車牌字元區的四個(紅色)邊界切線線段,它們要如何穩定的計算決定?就是我的車牌辨識技術的精華區了!我的RD剛剛使用特徵字模辨識技術寫完她的碩士論文初稿,預期也可以順利通過。如果她要繼續唸博士,我就會建議她以如何做好這種抽象區域的幾何校正的技術為題!只有我們知道,裡面是有很深奧的物理思維的!否則無法總是能那麼漂亮的轉正各式各樣歪斜狀態的車牌。哪個頂尖大學想知道這種技術嗎?找我的RD去讀博士班就可以了! 接下來又是酸AI的固定單元了!大家都聽過CNN在影像辨識領域正「大放光芒」之類的謠言?事實完全不是這樣的!情況比較像美國有個籃球打得不錯的高中生,正在尋求NBA選秀青睞,但因為某些健康或個人因素,還沒有任何球隊敢貿然用他!CNN這種技術至今仍未廣泛攻佔車牌辨識技術領域,是有顯著原因的!只是他們欺騙外行人避重就輕刻意不說而已,我可以告訴你! 如上車牌辨識圖所示,要在自然環境拍攝的影像中完成辨識車牌的工作,事實上包括三個階段的工作:1.找到車牌→2.幾何校正車牌→3.進行字元比對辨識。CNN的主要技術只限於第一階段而已!他們目前並不包括完成第二三階段工作的技術,距離實現高準確率的CNN架構車牌辨識商業軟體的目標還很遙遠!如前述籃球員的例子,他可能很會灌籃,但是投籃準度非常差?或是很缺乏團隊觀念?總之,如果少了關鍵技術,誰都不敢用他的! 新一代的影像辨識技術,關鍵不只是如何找到目標而已!也必須理解目標影像為何變形?以及如何依據物理原理與原因,開發出可以逆推校正回歸到正常位置與大小影像的第二階段技術!直到七八年前,因為一般影像畫素低(幾萬),車牌辨識系統辨識的對象都只是車牌特寫,如果取景範圍稍微大一點,車牌就會太小,解析度太低,難以辨識了!所以當時可辨識車牌的影像都類似這樣:
這種擺好姿勢拍攝的狀況下,我們可以假設車牌是個寬高比例很固定的矩形目標,只要搜尋全圖找到對比度比較高,黑白分明的矩形區塊就可以找到車牌了!找到車牌之後也只要簡單的平移、縮放與傾斜度微調就可以完成「幾何校正」的第二階段,開始第三階段的切割字元作比對了!所以多數車牌辨識論文的重點都不是第二階段的幾何校正,第一與第三階段說得較多! 事實上直到目前為止,絕大多數的車牌辨識核心還是難以跳脫這個矩形假設的桎梏,我自己2013年第一次嘗試製作商業化的車牌辨識核心時,也是模仿別人的公開論文這麼作的!這有甚麼問題呢?我們都知道在真實世界的立體空間之中,隨著角度距離的不同,原本是矩形的車牌可以被拍成平行四邊形、梯形、甚至任意四邊形!要將車牌抝正為原來應有的矩形,是非常困難需要深入研究的演算法議題! 如果你的辨識核心假設車牌目標是近似水平的矩形時,碰到如下停車柱拍攝的角度你就死定了!這種影像中你一定無法順利鎖定車牌!所以台南停車柱系統的後台才需要大量人力去輔助(補救)他們所用的車牌辨識系統能力的不足!現在大家知道為什麼多數車牌辨識系統只要水平傾斜到10度就掛了嗎?我是如何擺脫這個禁錮了車牌辨識專家數十年的矩形假設的呢?這個故事就足以寫一篇博士論文了!商業價值就是做出幾乎任何角度變形都可以辨識的車牌辨識軟體了!
所以用矩形假設找車牌位置的演算法應該要淘汰了!如何發明新的「鎖定車牌精確範圍」的演算法?如何依據新的鎖定車牌演算法,精準的整合相關資訊,做好車牌的空間幾何校正?這兩者是高度相關的!如最上圖所示:當我把這兩階段的演算法都做得很好時,才有可能正確的復原V與W從正前方看時的樣貌,也才可能正確的區分誰是V?誰是W? 所以幾何校正才是車牌辨識,以及在所有自然環境拍攝影像中,做特定目標辨識的關鍵技術!但是我天天在看CNN等技術發展的相關資訊,從未看到他們關心過物理與幾何學!請問機器要如何學會這種抽象的觀念呢?從大量資料中機器可以「理解」車牌變形的原理嗎?機器可以自行「想出」逆推校正扭曲影像的演算法嗎? 所以聽他們這些ML、DL與CNN的神奇故事,我完全無法入戲!除非他們也開始討論這個無可迴避的問題,否則我就會一直這樣態度輕蔑地罵下去!他們一直在逃避問題,他們自己一定知道的!還要繼續裝瘋賣傻欺騙世人嗎?說說CNN如何應對這個很基本也必然需要處理的問題吧? |
|
| ( 心情隨筆|工作職場 ) |