字體:小 中 大
字體:小 中 大 |
|
|
|
| 2026/06/26 15:10:57瀏覽24|回應0|推薦0 | |
近年來,生成式AI(Generative Artificial Intelligence, GenAI)的技術發展迅速,特別是大型語言模型(Large Language Model, LLM),不僅能進行自然語言處理,還可以生成文章、回答問題,應用範圍相當廣泛。然而,當面對一些特定領域的問題,或是使用者的提問涉及機密或專業資訊時,LLM的表現有時卻不盡理想,例如可能給出過於籠統的回答、不夠精確,甚至產生錯誤的資訊。 為了提升大型語言模型回答的準確性和專業度,傳統方法是對模型進行微調(Fine-tuning),過程中需要透過收集特定領域的訓練資料,讓模型在這些資料上進行訓練並調整參數,從而使其能夠掌握專業領域的知識,並生成更貼合需求的回應。然而,微調過程往往需要大量的計算資源和高品質的資料支持,不僅成本較高,且在應用情境中可能存在一定的局限性。例如,當需要快速更新或處理新知識時,模型必須重新進行微調,這將限制更新的頻率,並在一定程度上影響模型的靈活性和實用性。 針對這些挑戰,一種名為檢索增強生成(Retrieval-Augmented Generation, RAG)的技術應運而生。RAG不直接改變LLM模型本身,而是將檢索機制融入生成過程,透過結合外部資料來輔助LLM模型生成回答,讓回應可以更精準、更靈活,接下來,本文將介紹RAG的運作機制以及如何實作。 RAG的運作機制 RAG的運作原理是將語言模型與外部資料庫結合,構建一個動態的檢索生成框架。當使用者提出問題時,語言模型首先會分析問題並判斷自身知識是否足夠,如果不足,模型則會啟動檢索機制從外部資料庫中搜尋相關資訊,並將這些資料與問題結合,以生成具有參考價值的回答。 這樣的機制設計帶來了幾個好處:
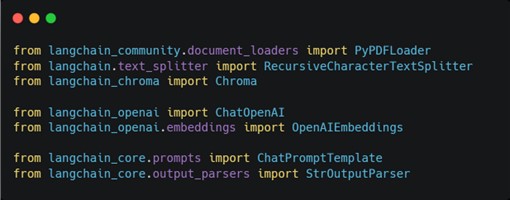
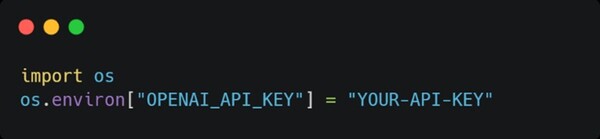
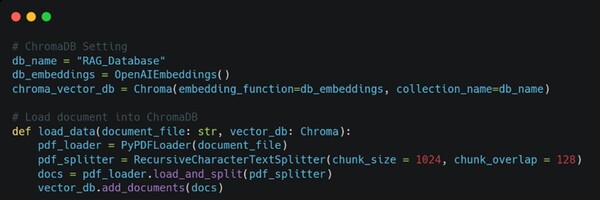
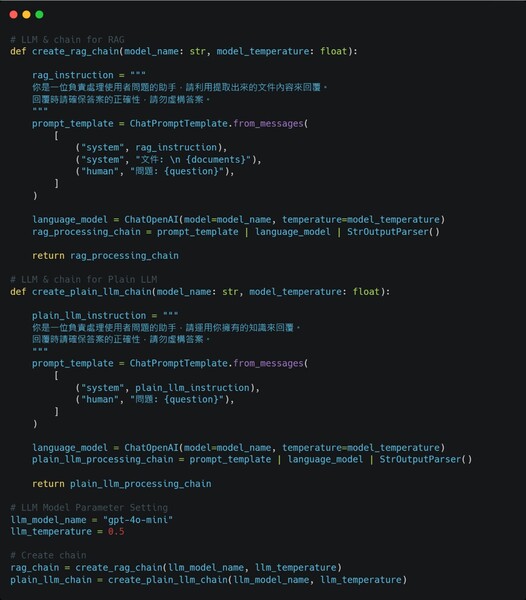
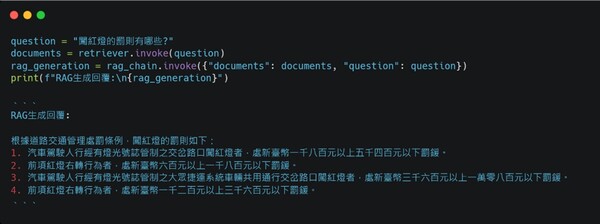
實作RAG應用 接下來本文將透過Python結合LangChain與OpenAI API,演示如何實作一個基礎的RAG問答系統。LangChain 是一款專為 LLM 開發設計的開源框架,不僅提供多元的工具集來建構語言應用,還支援多種API平台的整合,並且允許結合外部資料來源與自定義邏輯,讓開發者能更方便的選擇適合的模型資源進行開發,使開發過程更加靈活並快速滿足多樣化的應用需求。 本次範例以交通部的「道路交通管理處罰條例」法規文件作為外部資料來源,展示簡易RAG問答系統的實作方法:
以上就是一個基礎的 RAG 問答應用演示。當然,在實際應用中還可以考慮更多的細節與功能,例如如何處理某些敏感或禁止回答的情境、如何優化檢索機制以更好的符合使用者的期待,甚至可以結合爬蟲技術或串接搜尋引擎 API使LLM能即時搜尋網頁並進行分析等。此外,也可以加入更多的安全性和隱私保護措施,確保資料檢索與回答過程中的資訊安全。 結論 本文介紹了RAG技術及其實作的基礎方法,並通過Python與LangChain展示了一個基礎的RAG問答應用。作為解決大型語言模型回答不夠精確問題的一種有效方案,RAG結合了檢索與生成的優勢,使語言模型能夠提供更加準確、清晰且具有參考價值的回答。RAG技術不僅擴展了語言模型的應用範圍,為開發過程提供了更多靈活性,在企業應用中也能提高知識管理的效率,同時有效保護敏感資訊的安全,從而為企業帶來更高的價值和競爭力。 |
|
| ( 知識學習|其他 ) |