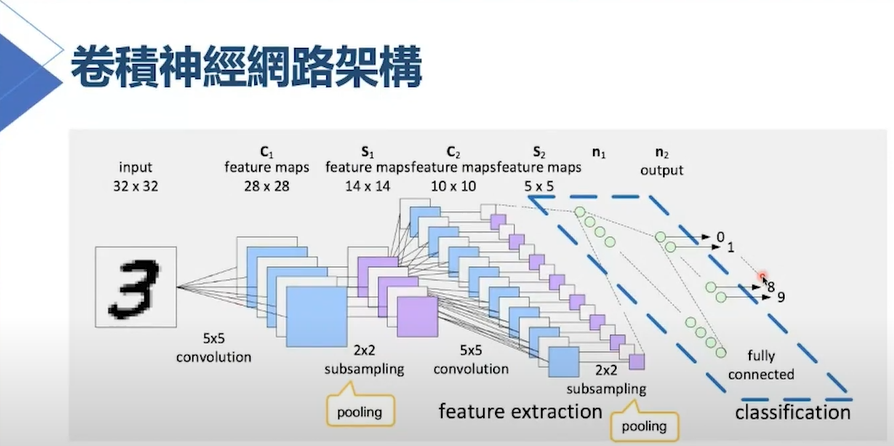
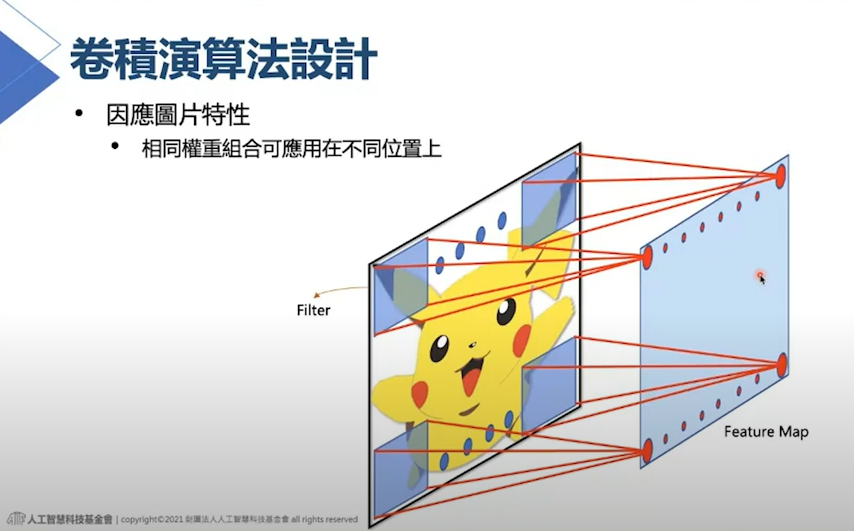
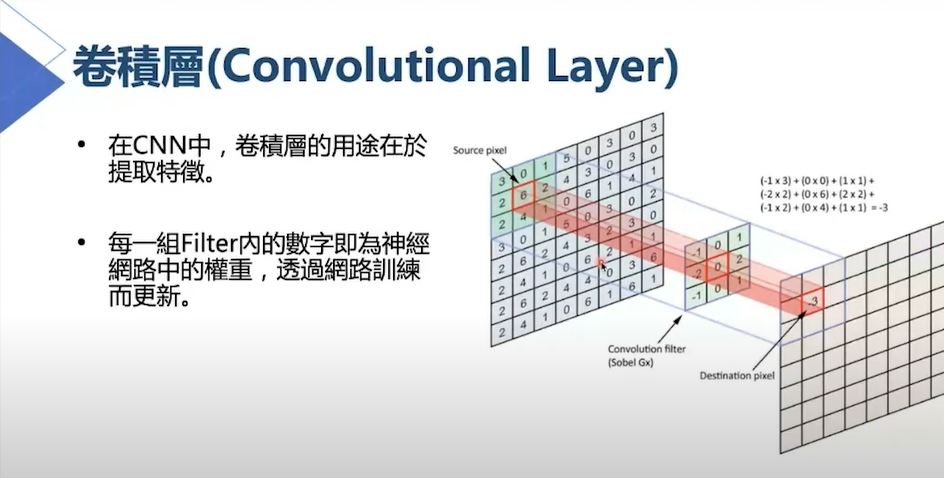
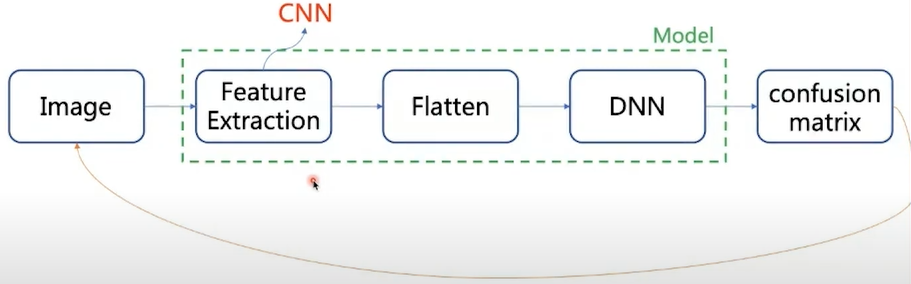
字體:小 中 大
字體:小 中 大 |
|
|
|
| 2023/01/18 05:53:54瀏覽1433|回應0|推薦10 | |
|
我覺得上面的文章與視訊是非常好的解釋CNN理念方法的文獻!我也很認真看完,甚至反覆熟讀了!但是也再度肯定了我的看法:CNN乃至其進階的YOLO等等演算法最大的罩門與騙局是甚麼?就是他們的運算量實在太大了!基本上就不應該是一個合理的影像辨識邏輯!但是他們很努力讓大家以為:這是找到特定目標(如皮卡丘)的「必然」程序! 如果他們成功讓所有人都相信了!這個影像辨識的產業技術內容與方向也就定調了!大家都必須在這個錯誤前提的框架之下追求更高的效率與正確性!這將會是一個世紀級的大災難!現在其實已經有很大的災情了!我實在忍不住想戳破國王的新衣其實是假的!我們真的不必一定要「只走」這條路的!至少我自己就證明了可以走不一樣的路,還更成功! 他們口口聲聲說這是「模擬」人類視覺認知物件的方式?所以沒有更聰明有智慧的方式了?他們最大的錯誤盲點或許在人類智慧認知上無關緊要,但是實務上卻造成極大的無謂運算量!讓整個CNN概念的演算法注定要以失敗收場!其實這個前提是不必要的!你知道嗎? 關鍵是甚麼?就是他們假設特徵擷取必須以數位矩陣的掃描為唯一的基石!其實不是的!人類視覺根本不是這麼運作的!我們會認知那隻皮卡丘,除了局部特徵之外,目標整體的特徵,如大區塊的顏色或輪廓,其實更為重要,或至少一樣重要!但是CNN演算法是直接忽視這件事的!就像管中窺豹或瞎子摸象,他們預設我們「看不到」整隻豹子或大象!只能用局部特徵拼湊事實?其實不必如此的! 因為他們的前輩,OCR演算法就是想直接找到完整目標的演算法,當然在數學上這並不容易,但並不是做不到!我的技術理念與實務成就,就是努力修正這種尋找整體特徵的OCR技術缺點,我也真的克服了很多這類困難!我就做到現在我做的事,成為台灣業界的一家穩定營運的影像辨識公司了! 只要跳脫CNN所說的「必然」架構,我不必被迫一定要搜尋所有「局部」特徵作為影像辨識的基礎!就像跳脫升學主義,我只要在家自學寫程式不必讀高中大學碩士博士就可以變成唐鳳,直接當部長了!我其實就是這樣走到今天的!大家聽懂了嗎? 不要被CNN的複雜數學架構唬住了!事實上他們自以為是的前提是有漏洞的,他們的影像辨識前輩並不是迂腐的笨蛋!那些OCR前輩的智慧甚至超過他們,是他們(ML、DL與CNN)太早驟下定論,太早否定前人的智慧了!所以才會陷入現在的困境!他們的方向是一定會陷入演算量地獄的! 稍微懂一點數學物理與電腦的人如果看看上述視訊影片都會感受到!這種以矩陣運算為主軸的邏輯就是會陷入計算量爆表的困境!但是其實一開始就不必一定要走這條路的!OCR的概念方法就完全沒有這種問題!就是直觀全圖找不預設大小形狀的目標,完全不必多層次Convolution的。只是現在AI影像辨識的牛皮吹太大了,ML、DL與CNN學派很難回頭認可學習OCR之類的前人科技概念了!面子掛不住啊! 我是覺得錯誤的道路不管你再堅持,終究還是會撞壁失敗的!越早醒悟改弦易轍就越好!CNN的邏輯是確定沒救了!有必要直接從根基改起!就是去請益OCR的全景目標辨識的技術概念了!先嘗試看(偵測)皮卡丘的整體顏色區塊與輪廓吧?那才能真的脫離CNN的運算量噩夢! |
|
| ( 心情隨筆|工作職場 ) |