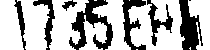字體:小 中 大
字體:小 中 大 |
|
|
|
| 2022/06/30 06:38:23瀏覽829|回應0|推薦4 | |
這是一張很難辨識的小又模糊的車牌影像,左邊是原圖320X240畫素的大小,右邊是車牌局部放大圖。以OCR辨識的角度來說,困難點是因為影像模糊,二值化切割後很難看到完整的字元目標,不是與周邊環境沾連,就是字元本身不夠黑而連貫,就破碎了!
我找車牌的方式跟人眼搜尋方式是幾乎一樣的!使用二值化簡化影像之後,即使字元破碎,還是可以根據一些蛛絲馬跡,譬如目標概略的大小與排列方式,找到圖中最可能是車牌的區塊,因為我不假設車牌一定是水平的矩形方塊,可以是一個任意四邊形,所以我的辨識核心才能抓到傾斜度很大的車牌。也因為可以定義四個任意傾斜的準確邊界,就可以很準確的正規化扭正車牌到標準大小。 重點是我知道全圖的二值化過程牽涉環境因素很多,用來找到車牌的位置或許還OK,但是如果碰到模糊的車牌影像,全圖二值化的結果如上圖,破碎的程度是根本無法比對字模辨識出是甚麼字的!所以我會根據那個可能是車牌位置的「任意四邊形」,回去原始資料中挖出灰階,甚至RGB的資料,也將它們投影轉正為標準車牌大小,如下圖。
從這裡開始,我就可以不計時間成本的使用任何影像處理手段,甚至用七八種方式反覆嘗試辨識字元,發現少字時,還可以回原圖,擴大那個任意四邊形的寬度再抓一次資料重新處理,直到我評估已找到最佳答案為止!因為我的處理標的已經縮小到只剩下一個標準車牌的小影像了!即使用很多方法嘗試辨識也不會花太多時間的!
譬如我的某個二值化程序可以把模糊的車牌處理成上圖這樣,比對之後得到整體符合度最高的答案:1735-EH!我就答對了!這個階段我的作法有點類似機器學習,就是用很多種可能的資料處理方式,建立自我評分機制,遍歷各種處理結果之後選擇最佳的答案輸出。須知嘗試多種方式處理資料再擇優輸出,是一個很浪費資源的過程,如果全圖都這樣玩的話你的軟體就笨死了!再多的GPU都救不了! 這個過程很像我最愛看的警察辦案的影集劇情!一開始警察不知道兇手是誰,必須用最節省資源的方式快速找到嫌犯,一旦鎖定嫌犯就可以投入所有資源,查出他的所有底細,跟蹤監視追捕施壓等等甚麼手段都來,確定是他的幹的壞事時,就立即逮捕結案! 這就是我的影像辨識策略了!全圖搜尋資訊是最耗費資源的!就像你不可能笨到滿街攔查路人,如大海撈針一樣的普查來找殺人犯一樣!你必須先「依據」嫌犯的特徵縮小搜尋範圍!搜尋的項目越少,範圍越小,就可以越快鎖定嫌犯。 現在流行的CNN目標搜尋概念也是類似的!用特徵的組合找到要找的目標。但是他們在研發階段就不是像我這樣,「自以為是」的用我已知道的抽象思考過程來決定我的搜索範圍。我是直接依據我想搜尋甚麼東西?譬如車牌具有的特徵,直接設計我的搜尋方式與特徵,但CNN搭配機器學習的做法是這樣的: 先蒐集大量已知正確答案的影像,所謂正確答案,當然是用大量人工去一一檢視標記的!有了正確答案的大量標記資料(有答案但無解法的題庫)後,就開始用CNN蒐集「所有」可能有用的特徵,如直線或斜線線段,或是轉折點,或是顏色區塊等等。因為目標有大有小嘛!這些特徵還要「分層」每一層抓不同大小的同樣特徵! 跑死電腦收集到這些「海量」特徵之後,開始「訓練」它們的模型,其實就是嘗試錯誤,慢慢縮減對答案對錯無關的特徵,讓機器慢慢「學會」哪些特徵與判斷對錯「比較」有關,不斷嘗試錯誤調整特徵項目與權重,直到找到:以目前的資料集來說,答對率最高的那個模式! 光看到這裡我就知道我的公司是根本用不起這種技術的!太花錢耗時了!巨量資料的蒐集與標記是燒錢!地毯式的蒐集所有大小層級的特徵,反覆天文數字的計算嘗試「學習」更是燒錢,你需要極佳的電腦做大量計算,還需要「懂得機器學習」的高薪專業人員長時間做這種「實驗」! 最後得到的結果只對你的資料集有用,辨識目標性質稍有改變時,就必須「重新訓練」了!很多人覺得這種說法很有學問?我是覺得很蠢!因為是「猜題」,所以猜對猜錯的過程與原因,連開發者也無法知道。簡單說:根本沒有誰學會了甚麼東西!況且機率統計並不是精準的解題過程,很難像傳統科學一樣,做到精準的高辨識正確率,能到九成大約就是極限了! 這種高耗能低效率的研發方式與預期成果,你覺得值得投資嗎?我知道對於需要98%以上辨識率的車牌辨識是絕對不行的!所以我不敢,也不會嘗試使用CNN與ML研發影像辨識產品的!除非用的錢不是我的!
|
|
| ( 心情隨筆|工作職場 ) |