字體:小 中 大
字體:小 中 大 |
|
|
|
| 2021/11/01 11:15:24瀏覽1004|回應0|推薦8 | |
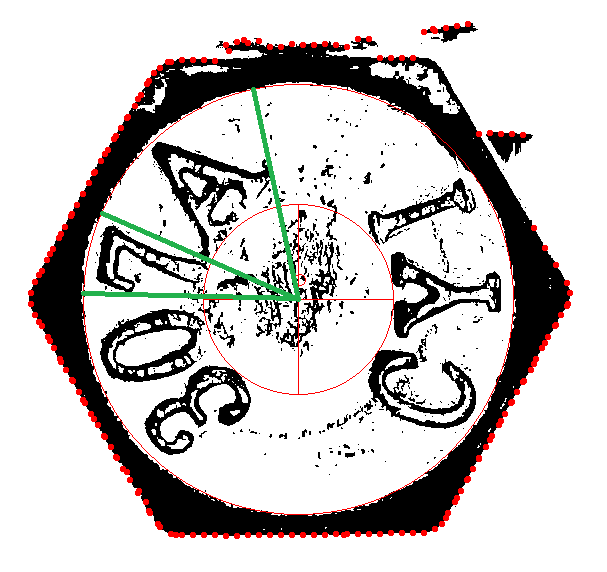
如上圖的字元辨識是個超尷尬的案例,字元清晰到這種程度,如果我跟客戶說無法辨識大概飯碗就不保了!但是以OCR的技術來說,那一組307A其實是很難辨識成功的,原因是如上圈出的部分,7A兩個字是實質沾連在一起的!要進入字模比對的程序,字元切割的處理勢在必行!
但它們是在環狀區域內互相沾連的,人的眼睛要切割它們很容易,只是一個直覺想法而已,但是要寫成程式來合理且正確的做出扇形的切割,變成兩個獨立目標?這個數學邏輯想想就頭大了!所以雖然上周五就已經知道應該怎麼作了,但是因為複雜的數學邏輯太恐怖,就決定放完周末假期再來對付它了! 從清晨到剛剛終於完成這個「小動作」!將7A這個連體嬰正確切開辨識完成了!怎麼作的?切割的第一個步驟是決定要從哪裡切斷?因為它們是扇形分布的,所以切割線的座標既非垂直線也非水平線,而是從中心座標射出的輻射線,我必須統計在這個目標內,哪一個角度的輻射線切過的黑點最少,就最可能是兩個字元的交界處。 你不能偷懶,直接用原來大目標一半的角度硬切的!看上圖就知道,因為字型與扇狀展開的關係,A所佔的角度範圍是遠大於7的!因為A是上窄下寬,7則是上寬下窄,從圓心看過去正好一個角度極小,一個極大!如果不精細統計連結的薄弱點,切出來的結果就無法正確辨識為7與A了! 找到正確角度之後如何切割呢?事實上需要重新編碼,在7字的角度範圍內的像素點,必須和A字的像素點有不同的編碼,編碼完畢再重新搜尋整理整個字元的寬、高、半徑與角度等等目標屬性!因為範圍不大,計算時間不會太久,但是處理的動作好多,寫程式就累翻了!
好家在,小心謹慎之下沒出太多錯誤,算是一次搞定了!當然也建立了之前沒玩過的扇形切割目標的演算法了!逸中版的OpenCV又多一組新功能函數了! |
|
| ( 心情隨筆|工作職場 ) |