字體:小 中 大
字體:小 中 大 |
|
|
|
| 2020/11/16 07:57:21瀏覽1451|回應0|推薦8 | |
|
我希望大家注意的是最後一句「這些專用的篩網,我們將其稱之為Kernel(卷積核 )」!這也是我閱讀不少相關文獻後看到最明確的定義,原來這種影像辨識的核心真的就是傳統的Match Filter或Mask(遮罩),也就是我三十年前就學會的影像數位濾波的概念。
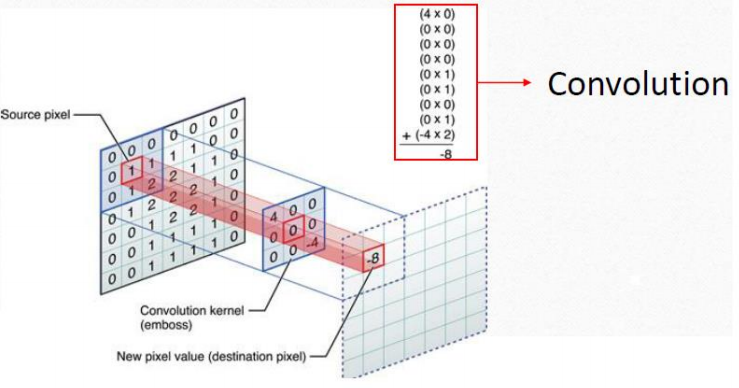
如上圖的3X3小矩陣就是傳統的數位濾波遮罩,也正是CNN卷積層方法中說的Kernel。事實是:30年前我就已經常常使用它們去「凸顯」影像中的某種特徵,譬如用參數中間大週圍小的遮罩去找一個錐狀的火山地形,但是我們會很審慎的,(如上圖)只是算出一個權重值(-8),然後用這些權重值繪出一張新圖,再來評估是不是真的有錐狀火山? 但是顯然CNN中所謂Kernel的概念,不但簡化而且粗糙化了這個審慎的評估程序,他們用一個不知從何而來的門檻值,只要達到門檻,就直接認定他們「找到了」他們想要的那種特徵,譬如一個錐狀物!這當然就留下了一個好大的不確定性,有待後續的程序處理。這個不知從何而來的門檻如果太高,不太明顯的火山就直接被排除了,如果太低呢?雜訊就會很高很多,後續的辨識程序就有得忙了! 按照這些CNN或機器學習或深度學習的想法,因為初期的決策門檻低,造成原始資料過多浮濫並「不是」問題!只要後續的統計機率篩選的數學機制(他們稱之為學習)運作良好,「所有」目標終究都會被找到的!但是我做同樣的事情想法就很不一樣了!我覺得他們用的是非常敗家的思考模式! 遮罩運算的目的是想知道單一畫素周邊的環境特徵,但是一個遮罩至少就是9(3X3遮罩)倍、25(5X5)倍乃至49(7X7)倍的運算量!我自己只有在讀研究所做學術研究時,完全不必擔心運算資源與終端產品的計算時間時,才會放膽大量使用遮罩運算,做為一個研發辨識軟體的公司,我根本是不敢用的! 但是他們這個學派不但毫不猶豫地使用,而且還「多尺度」的使用從小到大的遮罩,還很得意說他們「發明」了可以偵測「不同大小尺度」目標的「有效」方法?計算量太多嗎?設計新型的IC,用好多GPU平行分散大量運算就好了嘛?他們基本上就不太在乎演算法效率的問題,真的是家裡好有錢啊!我們小公司學不來的!要開模製造新型的IC欸!哪來這麼多錢啊? 所以我們如果想引進這種演算法,還希望比我們現有的傳統OCR軟體表現更好,第一關就過不了了!這不是我會不會這些數學,或者我能不能買到這些專業程式模組的問題,而是他們需要的運算量我直接就負擔不起了!我想大多數希望在影像辨識領域崛起的新興小型公司也跟我一樣玩不起的! 相對的,傳統OCR的辨識程序其實可以不必使用大量的遮罩運算,但是如何切割出真正想辨識的所有目標,就會是非常高技術的研發過程。還好的是:因為影像品質日益提升,畫素變高,聚焦準確之後,我們這一派傳統研究者的研發壓力難度其實是在快速降低之中的! 大家可以想像:越清晰,越有足夠解析度的目標,當然更容易正確被切割辨識,加上善用影像之外的目標特性資訊,譬如車牌的顏色與既定格式等等,其實我們真的可以不必花大錢做專屬IC就能開發出高辨識率,但低運算量的辨識軟體。前提是我們必須真的很深入研究每一個不同性質辨識目標的特性,為他們量身訂作最有效的辨識流程,很難套公式得到速食解的! 各位會好奇?我的幾千行車牌辨識核心程式中有沒有這種遮罩,或稱卷積層運算嗎?答案是:完全沒有!我找目標的方式大家可以去買我的書看看,真的有效而且很快,關鍵就是我「沒有」使用這種遮罩式運算!我家很窮嘛!CNN大家還說很有效率?卻是運算量大到讓我難以負荷的技術,你們就可以嗎?評估一下再說吧! |
|
| ( 心情隨筆|工作職場 ) |