字體:小 中 大
字體:小 中 大 |
|
|
|
| 2020/03/01 05:09:31瀏覽1362|回應0|推薦8 | |
我曾經協助精益科技做幕後的文件與證件辨識核心的研發,兩年之間也有很好的成果,但是僅限於掃描影像的辨識,基本上就是二維的影像,在目標定位上需要的動作就是:旋轉、平移與縮放三個動作,搭配他們公司既有的的掃瞄機硬體就是很棒的「辨識機」產品了! 但是因為手機拍照太好用了!現在很多客戶都希望用手機拍照之後辨識文件或證件目標,雖然我總是先介紹需要文件辨識的客戶去找精益科技,但如果他們堅持要辨識手機拍的影像,還是只能找我們開發辨識核心!因為手機是在三維立體空間中拍攝的,影像變形的情況就不是二維影像了!我們完全技轉給精益科技的二維影像辨識技術也Hold不住的! 這種案例最經典的就是替翰林出版社設計的手拍閱卷辨識核心了!如前面兩篇文章所述,也是用到很多非影像辨識本身的外在物理限制條件才能成功的!而且專案完成後,他們的資訊部門也希望完整的技術移轉,我花了兩天上課真的將原始碼與辨識技術都教他們了!我不是隨便說說的,我真的願意教給客戶他們需要的所有知識。給我合理的工作費用就好!
上面是原始的影像轉為灰階的樣貌,下面是二值化影像:
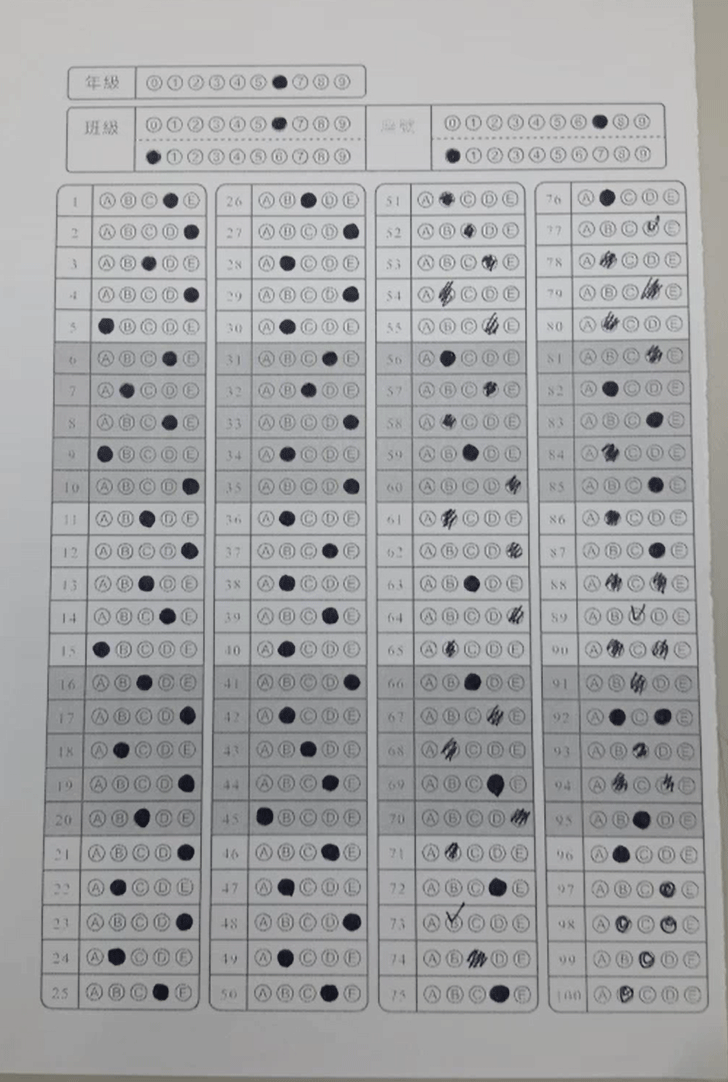
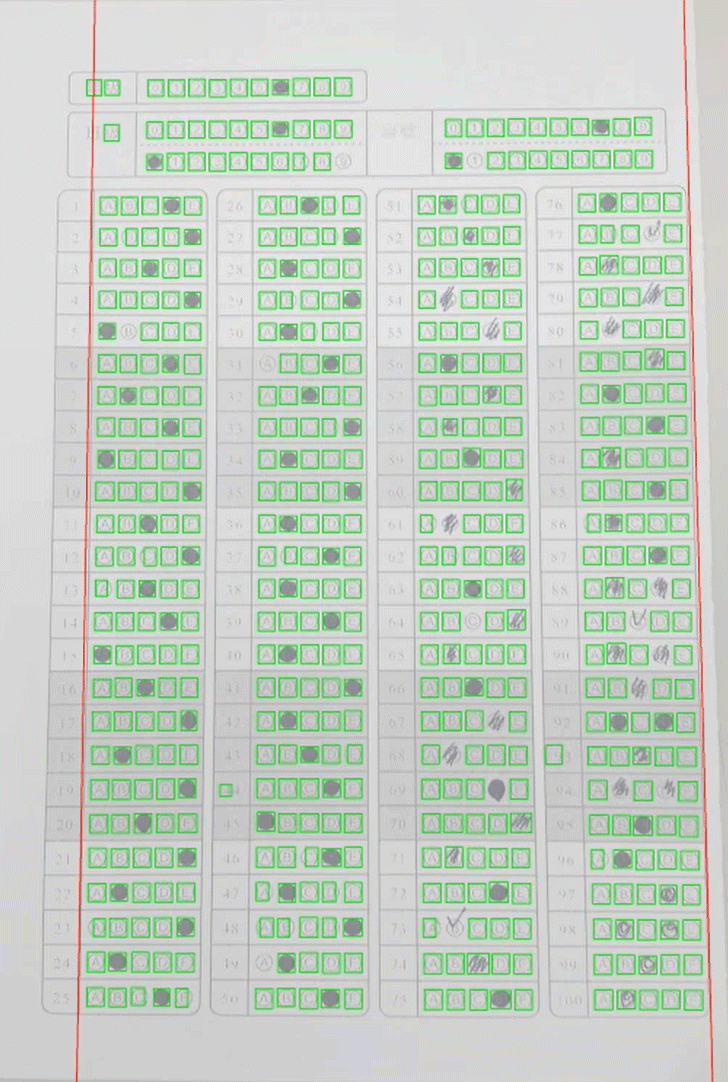
在影像不會完美的狀況下,我們初步辨識塗選格的目標總是不完整的,尤其是有塗選的框框常常就不像標準的空格了,如下圖所示,綠框是確定為格子的目標,可以看到很多缺漏:
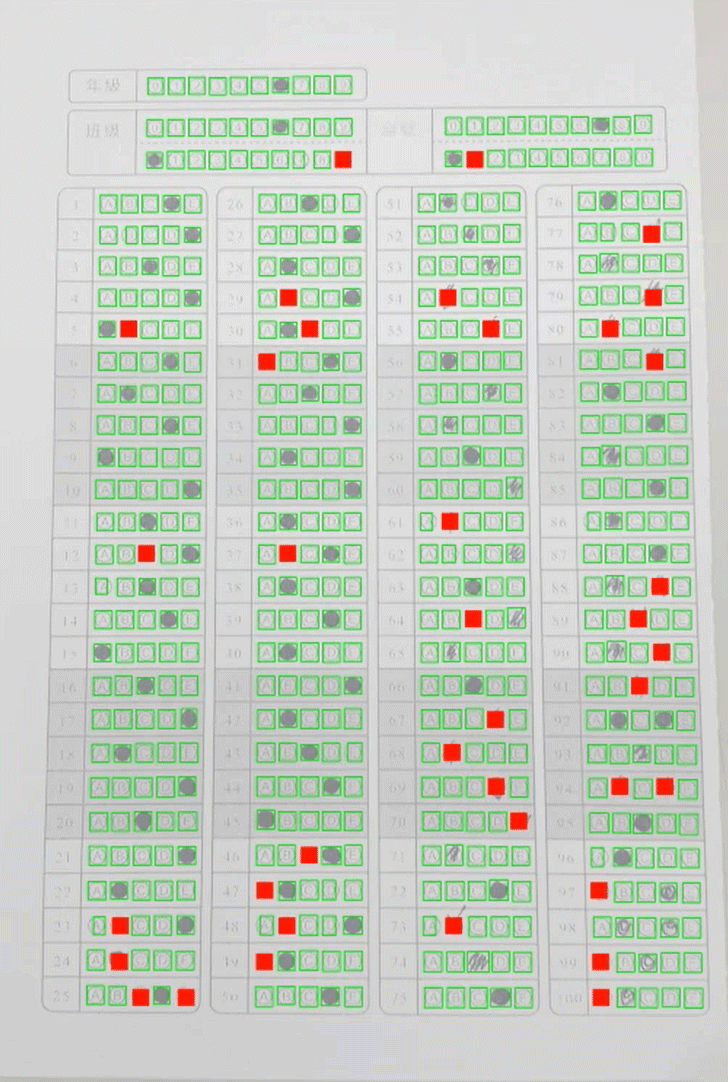
雖然初步辨識不完美,但是已經足夠我們找到邊界(紅線),這是很重要的!因為邊界不保證是矩形,我們必須依照此資訊做出幾何關係,知道每一個格子屬於第幾行第幾列?如果某個目標根本不在隊伍之中,我們也可以明確地排除它!隊伍中誰在初步辨識中缺席了?也能正確補足了!如下圖就是我們可以找到的經緯線,再下圖的紅色方塊就是程式補上的應有目標位置:
至此所有格子的位置我們都能精確掌握了!就可以在那些小區域內做很準確的辨識它們是不是有被塗選?這一部分其實就很好做了!有如車牌辨識,字元目標找到之後,就是比對字模的例行工作,很簡單的!在此就不再贅述了! 在不完美的全圖影像中辨識幾百個格子總會有遺漏的狀況下,我們可以正確鎖定「所有」目標的關鍵並不是我們的「影像辨識演算法」特別厲害,而是我引用了考卷預設格式的資訊:他們總是成行列矩陣方式排列的!找到他們「應該」對齊的直線與橫線,我當然可以準確推算缺席者的位置,不必再刻意做「強化」的影像辨識把它們硬找出來了! 這就是我說的:影像辨識不只是影像辨識,為了達到目的,並不是永遠只在影像中找更細微隱晦的資訊來解決問題,手拍影像總是不完美的,再好的影像辨識演算法都會力有未逮。但是如果你能善用影像之外的資訊,常常可以很簡單的就解決問題! 這也是我說機器學習派的思維方式很難跟我競爭的原因之一!它們是不講究引用外在條件資訊的!如這個案例中,我用幾何學準確的推算出缺漏目標的過程,機器學習派要如何完成呢?你告訴我吧!如果他們也想到這麼多細節,將這些邏輯都加入他們的演算程序,就根本不必使用機器學習的那些「學習」過程了! 我開發這個專案使用的影像樣本大約四五十張,開發時程大約三個月,做出來的軟體實用起來就辨識率很好了!另一家南一書局風聞很好用,也跟我要求了一樣的技術轉移。試問如果使用機器學習的方式我要怎麼做?要收集多少影像樣本去「學習」?才能達到很高(>95%)的辨識率,還有非常快的辨識速度,我的軟體辨識一張都是一百多毫秒而已! |
|
| ( 心情隨筆|工作職場 ) |