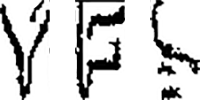字體:小 中 大
字體:小 中 大 |
|
|
|
| 2021/10/06 08:35:20瀏覽884|回應0|推薦6 | |
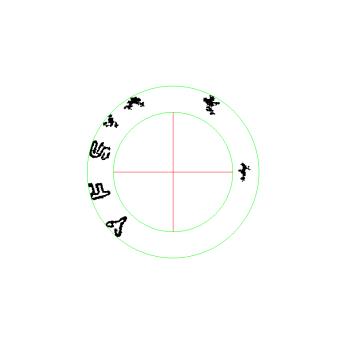
好像有一段時間沒談螺絲釘的辨識了!也算是好消息吧?因為演算法的可行性已經獲得證實,大成鋼公司正在積極採購組裝測試拍攝的設備,最終當然是要做成一個制式化的辨識機器的,就是要從實驗環境變成產品化,他們也遇到一些小問題正在處理,我就比較少新的研究資料,多半在整理混亂複雜的辨識流程,以及思考如何優化辨識速度。目前光是螺絲釘頭的辨識核心就有5000行了!規模已經直追我的車牌辨識核心了! 這幾天剛好有一些車牌辨識的新客戶詢問與舊客戶的維護工作,螺絲釘辨識停工了幾天,就介紹一下這個辨識案例,讓大家深入理解一下我工作的方式。 首先是這個案例的字元與背景的對比度很低,還加上內外圈有比字元更深色的區域,事實上目標區就有三種代表性的亮度,要正確分割字元其實需要的是「三」值化而非「二」值化,因此其實門檻值決策是要相對調整的,通常我會有三種以上的不同二值化流程,最佳狀態可以做成這樣:
接下來是要去除同心圓的圓心與圓周全黑區域,這當然需要仰賴精準的圓心定位,還有殘餘似圓弧的雜訊清除機制,整理之後的剩餘資訊就變成這樣:
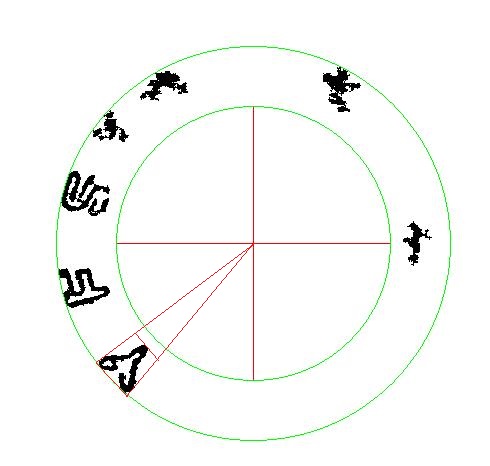
此時可以用很多條件篩選可能的字元,包括與背景的灰階對比度、目標形狀的寬高比等等,最後依據剩餘目標之間的間格規律性鎖定哪幾個目標可能是規格或商標字串。如上圖就是不太完整的Y、F與S了!但是他們位居環狀邊緣各自有不同的旋轉角度,就必須以極座標為基礎做變形轉正:
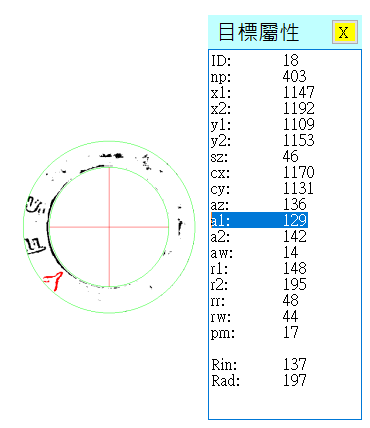
換言之,每個目標除了有直角坐標之外,也會換算出它們的極座標屬性,譬如上圖的Y字扇形分布範圍是從129度到142度:
三字元都轉正並排後影像如下,就可以拿出標準字模來比對了!
我想大家都會覺得Y與F還看得出來是Y與F,但是S就很難說確定是S了!因為原圖本來S就很破碎,我們勉強抓到組合幾個碎片之後也只能做到這樣,確實我的程式直接辨識的結果並不是YFS,而是YFE,此時我們還有一個參考資料,就是廠商與規格字串的名單! 三字的可能字串有大約20個,與YFE比較,沒有一個是字元全對的,所以YFE就不可能是正確答案了!那退而求其次,找出三字中有兩字一樣的,就只剩下一種可能:YFS,所以應該就是它了!如果還不放心,可以去查詢辨識成E的那個字元目標,如果以S字模來比對,是不是也有一定的相似度?Y+F+S這個答案的整體總分,是否也可以達到被認定有效的低標?如果可以,就說答案是YFS吧! 所以我的這個辨識核心與車牌辨識核心一樣,已經建構成一個有如大都市一樣,道路四通八達的複雜體系了!不僅路線很多,也會在每個階段都有自評與補救機制。也很像警察辦案,我們已知有人犯罪了,才會啟動辦案,每條線索追下去未必會有結果,但過程一定是要步步合理前後連貫的!這絕對是一個立體的複雜架構。 所謂的自評就是拿已知,或前面程序中已確定的限制條件,來檢驗目前的階段性結果,如果根本不可能,就要做一些相應處理,可能是放棄這整個處理流程,開始另一個辨識流程;也可能是硬改一部份的結果,使符合可能的範圍,繼續走完這個辨識流程,譬如將YFE這個答案否決,改測試YFS的可能性等等。 目前居於主流派的機器學習思維,基本上就假設每個辨識流程都要引進到機率統計的決策模式。在我的觀點是沒必要,也不合適的!就算要用到多種方式嘗試錯誤找到最佳解答,每一種嘗試其實也必須是一個自成體系的完整流程。譬如一樣都必須有灰階化→二值化→目標切割→目標排列組織等等程序,才有機會產出可能的答案。 簡單說,有效的影像辨識設計主體應該仍然是傳統的,不包含機器學習概念的辨識流程,不必一定要受限於CNN或ML或DL的數學模式架構,數學方法不會是主角,科學、物理與人為設定的已知條件,才是影像辨識流程中最需要關注遵循的方向。 我不會排除使用任何CNN、ML或DL的相關技巧,但絕對不會認為它們是前提或必須使用的項目,如果有人說影像辨識的核心技術是這些東西?我認為是嚴重的誤導!不必相信或受限於這種觀點,好好理解傳統影像辨識技術,從確定的資訊開始逐步建立你的辨識程式,才是最簡單合理,也可以迅速達到目標的做法。 最近跟著在讀碩士班的RD也看了一些新的論文,我發現其實真正的科學家,即使自認是ML或DL專家的AI學派學者,實際研究影像辨識的做法跟我也沒有太大差異,構思研究方法的主軸與骨幹依舊是物理現象與事實,並不會迷信ML或DL本身就有神力,可以產生超越人類智慧的結果。奉勸對影像辨識有興趣的初學者,千萬不要被過度簡化還別有居心的AI廣告誤導了!影像辨識不是那樣做的。 |
|
| ( 心情隨筆|工作職場 ) |