字體:小 中 大
字體:小 中 大 |
|
|
|
| 2021/09/16 05:31:16瀏覽792|回應0|推薦3 | |
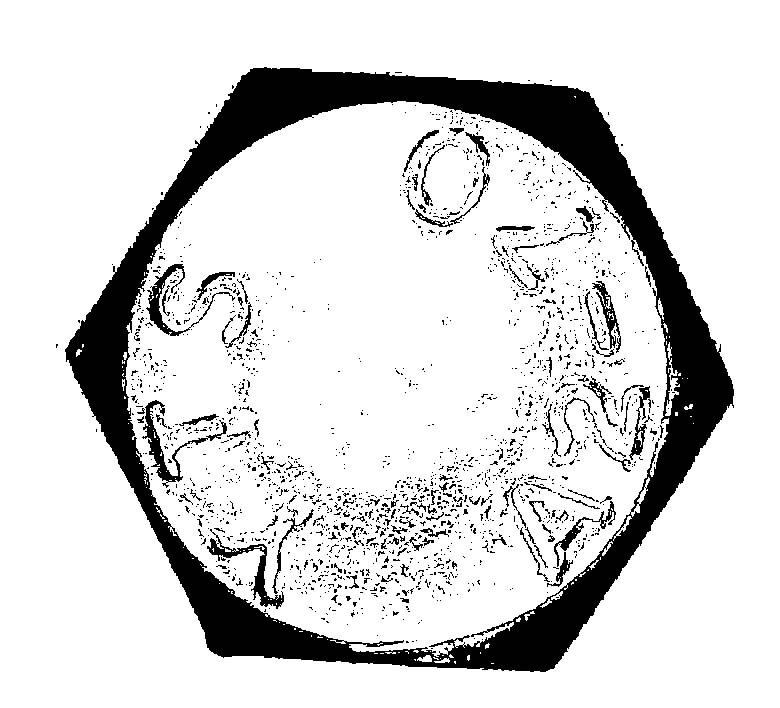
我是很認真執行傳統影像辨識技術研發的人,書上說:要辨識出某個目標字元,關鍵就是做出正確的Segmentation!把目標字元正確切割為單一目標之後,經過「旋轉」→「平移」→「縮放」到標準字模比對,你就可以「知道」是甚麼字了! 所以傳統的,認真的影像辨識書上,都會詳細介紹如何切割目標的種種方法技術,相關論文也很多的!不必懷疑,這些技術我都知道,還做得比他們講得更多!如果我只是一個渴望發表更多SCI,尋求賴此升等的教授,光靠這個議題我就可以發表很多篇SCI,當然我也早就賴以升到正教授,甚至可能到頂大任教了? 但是我很明確知道:沒有任何一種已知或未知的二值化影像分割技術,可以保證將字元切割為獨立完整的目標!所以「正確切割」的研究是有極限的,即使你達到了極限,也無法保證你要辨識的字元,可以變成「一個」獨立的目標,所以你終究無法只用Segmentation的技術完成OCR辨識目標的!相對來說,我能否升上教授太不重要了!我要的目標是真的可以突破這個研發關卡!
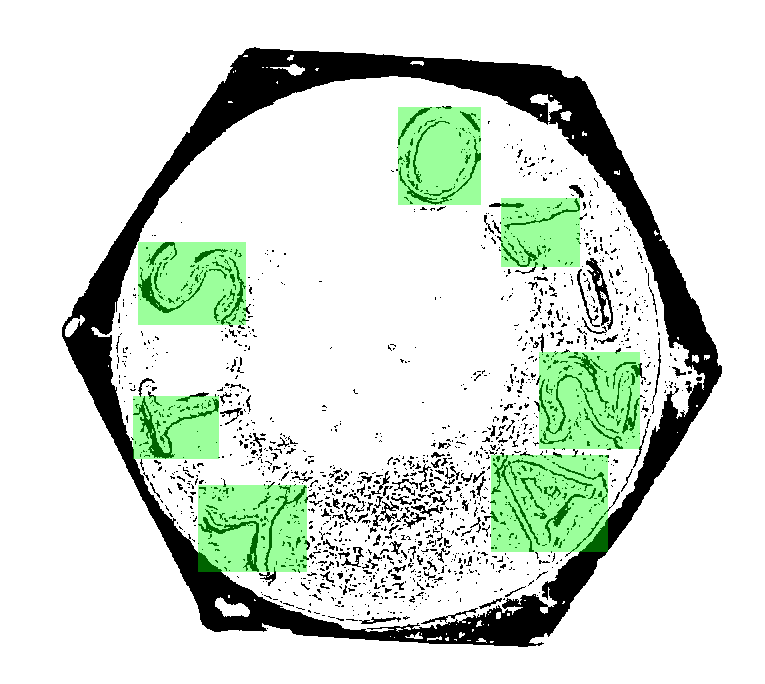
上圖的案例就是一個明確也殘酷的案例!我只是用PhotoShop軟體示意一下很難將字元切個為獨立目標,不管你怎麼切割,字元不是與背景沾連就是變得破碎。事實上我嘗試過更多二值化切割的技術,甚至包括書上沒說,我也沒發表的特殊技巧,但如果影像就是如此不清晰,任何以影像資訊為基礎的技術方法都無法完成任務的! 這就是所有影像辨識書本知識的極限了!他們都沒告訴我真的碰到這一個無法超越的障礙時,我還可以怎麼作?現在熱炒的AI技術則是更含糊地說:你只要根據眼睛判斷正確答案,給電腦很多資料,讓電腦自己去摸索,就「一定」可以辨識出來的?
事實是:不僅我不相信,也沒有任何事實證明ML或DL有這麼聰明!可惜的是:這個詐術運作得很成功,多數人都已經相信這是「有可能的」!這個研究領域預期也必然會因此空轉好多年,影像辨識的AI科技也會因此停滯很久了! 我沒有那些AI學者那麼浪漫還不負責任!其實他們自己也很清楚,ML或DL是不可能自己產生那種複雜的認知過程的!但是騎虎難下了,他們必須硬抝下去。但是我不必!我會善用影像辨識之外的常識邏輯幫我將影像上實質破碎的目標組合起來,再進入字模比對的過程,所以我可以辨識出上面這種模糊的字元。
以我目前研究如何組織拼湊破碎目標的邏輯,我已經可以做到上面的程度!仔細看還是有些瑕疵,但已經足以讓我正確辨識出我要的結果了!我用到的「合理拼湊」邏輯,就是任何影像辨識書本或SCI論文都沒有說過,但是任何普通人都知道的常識!譬如實際文字的碎片目標對比度會略高於背景雜訊,譬如一個文字目標寬高比大約是1:1到1:2等等。
看懂了嗎?我不會比各位聰明多少,我只是認真地讓每一個人都有的常識變成程式,也就是變成高科技的成員,我就可以辨識如此模糊的目標!這就是我的AI理念最經典的實現範例了!AI絕對不是CNN+ML+DL之類的抽象概念組合的產物,你應該相信:你的腦袋想的事情就是AI影像辨識的最佳導師與規範了!忽視看輕你的常識想法的專家,應該只是AI詐騙集團的成員! |
|
| ( 心情隨筆|工作職場 ) |