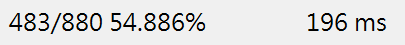字體:小 中 大
字體:小 中 大 |
|
|
|
| 2021/01/04 15:56:12瀏覽1447|回應0|推薦5 | |
雖然我常常批評ML與CNN等等所謂的AI技術被過譽高估,已經誤導了影像辨識的正確認知與發展。但是我也一直同時強調:任何一種存在的技術都一定有其價值,但是必須配合物理事實與現狀,只要正確的用在對的地方,沒有所謂「不好」的技術!為了證明我的理念,也希望可以讓我的技術升級,所以我一邊批評,卻也一邊積極學習所有我能接觸到的AI新技術。 我認為影像辨識的正確處理概念應該是:「知之為知之,不知為不知」,已知確定的事情絕對要用傳統OCR的概念精確的處理,不應該用ML的機率統計概念來猜測或「學習」?至於不太確定的部分呢?那就很適合引用ML的機率統計概念了!不要輕率的靠著一時心情好壞,或眼前的一兩個案例來決定,我以前就是常常如此的。 這段時間我照著這個理念認真做了,也真的大有進展,該是做個整理報告的時候了!雖然終端客戶可能不會感覺到我的明顯進步,畢竟對於整體辨識率來說差異只是進步個零點幾趴而已。但是以研發的角度來看,成果相當驚人!ML真的幫了我的大忙。下面是一筆總數880張的路邊開單拍照的照片,其實是某個車牌辨識系統辨識失敗的照片集錦,所以裡面不會有「很好辨識」的簡單案例!算是一個有相當大難度的題庫吧!
上面是用我之前的辨識核心辨識的成績,雖然我常常PO出困難辨識成功的案例,好像很厲害?但我也說過,碰到辨識困難的影像,成功率常常是不到一半的!前述的880張影像舊版核心的辨識成功率就只有54.886%,還是一個不及格的成績! 但是經過我引進ML的機率統計概念強化我的二值化門檻判斷機制之後,模糊字元的辨識能力增強,我將以前因為字元模糊衍伸出來的很多補救程式也大幅簡化了,空出的時間就可以做更多樣化的二值化嘗試,也就是我總能將字元切割得很清楚,辨識成功率當然就高很多了!結果是很驚人的從54分進步到95分!
上面就是一個案例的差別,以前是絕對無法辨識的!車牌既陰暗還傾斜加上螺絲孔干擾等等,卻因為人的眼睛還是可以勉強辨識,所以總會讓我心癢癢的!如果人眼都能辨識,一定有合乎邏輯的程序在人腦之中,很希望我可以探索人腦後辨識成功。現在很多這種難度的案例因為更準確,且多樣化的二值化流程,都能辨識了!多出來的技術主要就是ML的多變數機率統計整合的技巧了!
具體的說,像上面這種車牌狀況複雜的情形,人的眼睛可以很容易的排除不利因子,譬如車牌背景掉漆的部份,正確的看到字元。我的物理觀念足以理解這些干擾辨識的變因,但是顧得了東就顧不了西,對於多個變因的通盤考慮,之前我就是想不出全面整合的數學公式。 但這正是ML的強項!他們從來不會直接以單一變因做判斷的!都是以機率統計的方式將所有變因影響的機率量化整合之後做一個整體判斷。譬如判斷是不是垃圾郵件時,他們不會因為某個字出現就判定是垃圾郵件,而是嘗試計算出這個字,或某些狀況出現時,此郵件真的是垃圾郵件的機率!綜合所有可以「看出」是否垃圾郵件的條件機率,才是他們判斷的依據。 當然要正確的算出每個變因的機率,還是需要大量資料統計的!我的880張照片其實還不夠,就是對於每一個變因的狀況涵蓋度還不夠做出很正確的機率,但我光是引用他們整合多變因機率的技巧就獲益良多了,統計資料不足的部分就用經驗或實驗值補足了,影響不大的!這樣就足以讓我的車牌辨識核心能力大幅度進化了! 所以即使以最狹隘的觀念說:凡是AI都必須使用ML,我的辨識核心也已經正式引進ML的技術,可以對外宣告我的產品也AI化了!當然我很希望大家知道,主角依然是OCR的辨識流程,ML只是在二值化的過程中,擔任了整合多個變數成為機率統計架構的角色!這就是我說的適才適所,如果硬是要將整個辨識流程都用機率統計來做,應該會是一團亂,怎麼作都沒有好結果的! 目前新版的辨識時間長了好多,但這是大幅增加演算法的必然結果,第一階段當然是先追求功能,就是提升辨識能力,接下來才是追求效能優化,給我幾天繼續研究,預計應該可以讓時間縮短到與原來的程式表現相近!如果是有辨識時間壓力的情境產品,我也會研究如何在對辨識力影像最小的狀況下簡化辨識流程,所以一個車牌辨識的題目下我才會有五六種產品。
|
|
| ( 心情隨筆|工作職場 ) |