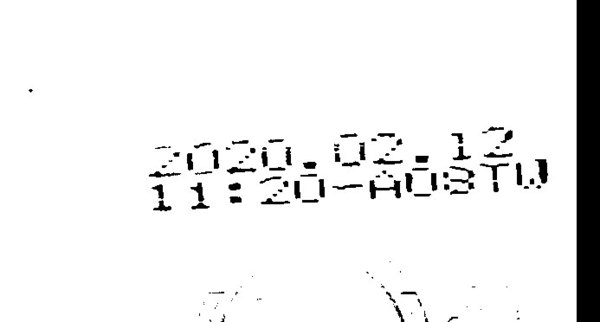字體:小 中 大
字體:小 中 大 |
|
|
|
| 2020/10/13 05:41:50瀏覽964|回應0|推薦9 | |
|
這樣的文字怎麼辨識啊?傳統的OCR軟體辨識能力我們是領教過的,這樣鐵定是甚麼都辨識不出來,所以才會需要比較特別進階的辨識軟體,這就是一家叫威視康公司的產品展示影片。 好厲害不是嗎?其實你自己要作也不難的!以上例來說:其實不必寫程式,只用PhotoShop就可以很快看到關鍵的字元了!
灰階化
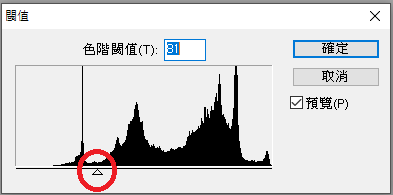
二值化 怎麼樣?從這裡做起就不會太難了吧?我唯一作的影像處理「思考抉擇」只是二值化門檻的選擇而已,下圖是灰階圖的畫素分布直方圖,其中紅圈圈標示的三角形左邊的山峰,就是你想看的那些黑黑的字元了!用物理學的說法呢?你要辨識的就是彩色繽紛的圖上最黑的那些東西!
所以我們常常是因為對於影像辨識原理掌握不夠好而被迷惑的!多數「專家」們知道的招數也未必很多,可能剛好不會使用簡單的傳統OCR解法。或者為了搶學生,刻意誤導初學者,必須使用自己熟悉推薦的方法!這樣老師開的課才有人選啊!所以會讓初學者誤判了各種影像辨識問題的難度。 如果是業者,當然更會刻意故弄玄虛,讓客戶們目眩神迷,以為這些影像辨識內涵著神奇的技術,就比較容易開出較高的售價了!事實呢?如果你夠清楚影像的基本知識,掌握到需要辨識目標相對於背景的特性差異,就像中國武術說的點穴一樣,抓到重點(痛點)給他點下去,就可以輕易克敵制勝了! 我認為要作好各種特定目的的影像辨識,有效的核心工作應該是分析問題對症下藥,而不是選擇使用甚麼特殊神奇的演算法!目前大家標榜的那些CNN捲積層之類的東西,其實都太傾向於想要一次解決所有的狀況,但那是陳義太高的目標,很難作到的!所以他們想要達到特定的辨識目的時,還是必須做很多實驗調整演算法參數的,這些過程他們就稱之為「學習」了! 譬如上面這種例子,需要辨識的目標其實不會比背景的各種「特徵」明顯,但是如果你使用了某種特徵演算法就只能一路跟著玩下去!你其實不知道為什麼它們要設計得那麼複雜?只能按照操作手冊玩下去,辨識結果不好就繼續「學習」到好為止!其實只是慢慢挑掉比印上去的點矩陣黑字更明顯的目標。 經過漫長的「學習」過程,把不想要的特徵物件用參數控制都挑乾淨時,就可以得到像我上面展示的那種二值化圖了!此時要辨識出那些是甚麼字?還是需要回歸到OCR的標準程序的!所以如果你在這裡用了CNN之類的演算法,你其實是把事情變複雜,工作也變多了!辨識準度呢?完全沒有提高。演算時間呢?當然會更久! 這就是我對於影像辨識技術現況發展的一個悲觀認知!太多使用傳統影像處理與辨識可以快速準確得到結果的工作,都變成了漫長而且未必較有效率的「學習過程」!這是我們想要的人工智慧合理的發展方向嗎?事實上我看上例中威視康公司的展示,估計也不是使用機器學習之類的新技術作的,稍有OCR處理經驗的人都知道不需要用到ML,但是為了「跟上」AI風潮,也適度隱藏自己用的關鍵技術,他們一定不會說清楚講明白的!就讓你以為是深度學習吧!對廠商比較有利。 所以大家就繼續這樣上下交相賊,懂得的故意裝傻,不懂的卻努力裝會,打一陣子AI迷糊仗吧!這個領域大概只有我這麼白目,總是忍不住要戳破國王的新衣,實話實說吧? |
|
| ( 心情隨筆|心情日記 ) |