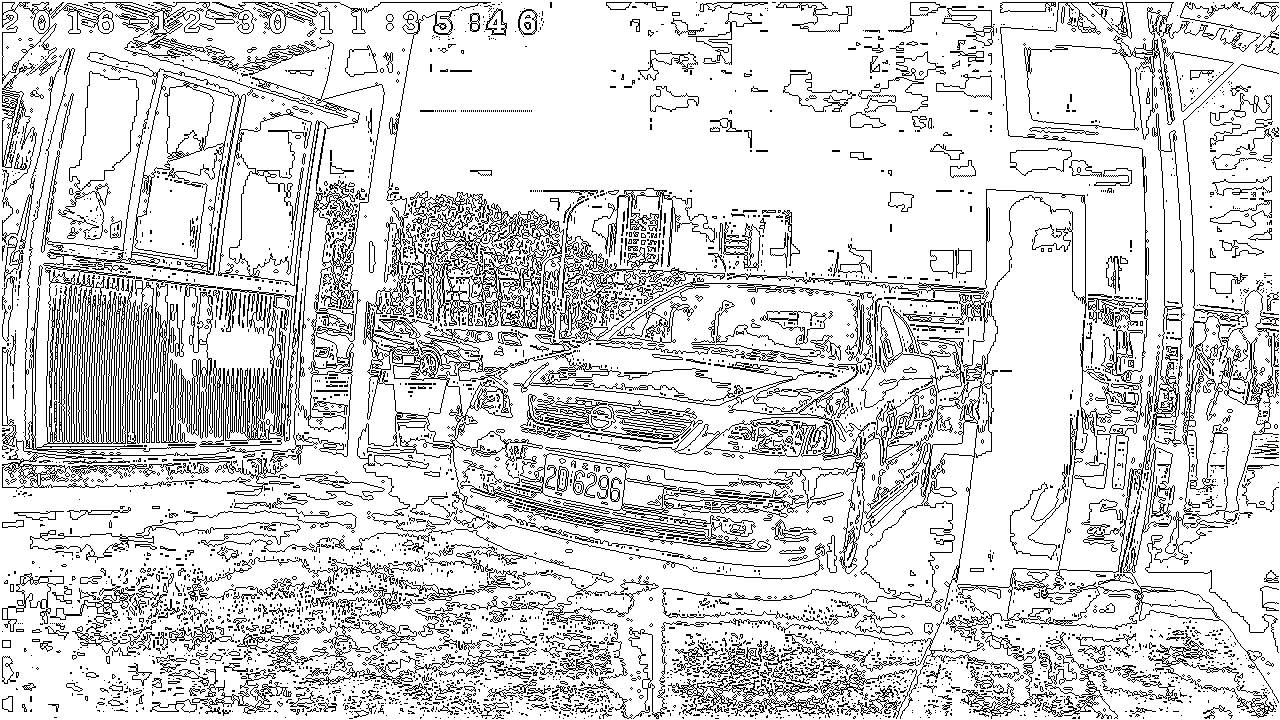字體:小 中 大
字體:小 中 大 |
|
|
|
| 2020/09/01 15:32:36瀏覽1387|回應0|推薦5 | |
理工科系的人應該都知道傅立葉轉換這個數學方法吧?但是它能在電腦領域發光發熱的一個重要發明是「快速」傅立葉轉換Fast Fourier Transform!同樣的運算結果計算速度快了非常多倍,在電腦計算速度還不快的時代,這是極為重要的演算法創新,沒有它很多包含頻率計算功能的機器都做不出來了! 在剛開始研發我的商業版車牌辨識核心時,我走了一條多數車牌辨識前輩都直接放棄不走的路!就是堅持作全圖的二值化→輪廓化→建立目標物件。一般的車牌辨識大概是像下圖這樣找車牌的,就是找到亮度對比較大的跳躍點,這些點集中的矩形區域就可能是車牌:
這樣找車牌是很快,我2013年第一次作嘉義市的路口監視器車牌辨識系統時就是模仿前輩們這麼作的!但是也因此發現它有很多難以克服的缺點,其中最糟糕的就是無法辨識傾斜的車牌!原因是它有個假設是:車牌是水平的矩形,但傾斜車牌就不是那個形狀,所以在全圖中根本找不到傾斜的車牌。如果車牌只是略微傾斜個10度就無法辨識,這種辨識軟體怎麼看都很笨!
所以我決定來個大突破,回歸傳統的OCR辨識正途,但是如果我想看到不同明暗區域的車牌,用了動態的二值化門檻,結果就會遇到這種看起來很可怕的困境:
要在這麼複雜的線條中找到所有的封閉曲線,然後評估它們的大小形狀作篩選找出可能的字元,我必須大量使用所謂的氾濫式演算法!其實更早以前2009年我已經發現這會算得很慢,所以2013年時我才沒有用自己的OCR想法而是模仿其他車牌辨識演算法。2014年我決定好好研究讓它變快的演算法,結果也真的發明了一個很抽象但是快速的演算法!基本動作大概像下圖這樣:先將獨立目標進行唯一的編碼,再收集同號的編碼點成為一個目標物件。
它讓原本慢吞吞的目標搜尋變得很快,快到百萬畫素的影像作好目標分類只需要20-30毫秒!我當然如獲至寶,以為自己也發明了一個類似FFT的好東西?一直用在我的所有產品之中,當作我的秘密武器。原本打算保密到我退休的那一天才公諸於世,只讓我的公司核心員工可以看到原始碼! 但是兩三年前開始碰到一個尷尬的狀況,我替某大出版社寫手機閱卷程式,他們很希望我可以釋出原始碼,給的價錢也不錯,但是我捨不得讓這個「特殊」演算法曝光,就開始回頭研究傳統氾濫式演算法的改良,也有了一些成效,加上考卷的辨識不像戶外拍攝的車牌影像那麼複雜,就用比較一般的氾濫式演算法交差了! 之後有幾個案子也都是這麼處理,給客戶原始碼,但是避開不給他們我的「最高機密」!但是有點尷尬的情況慢慢出現了!就是我改良的氾濫式演算法速度已經逐漸逼近我的「機密演算法」了!計算複雜輪廓線的時間幾乎難分高下了!而且程式碼還會簡短很多,維護更加容易。我因此陷入天人交戰?要不要全面改回使用較簡單邏輯的氾濫式演算法? 大約一個月前終於下定決心,如果根本不是神奇寶貝就不要再繼續敝帚自珍,捨不得放棄使用了!開始將所有軟體內的這種特殊演算法慢慢抽出改掉了!回頭看這段歷史,說穿了其實只是我自己當年對於氾濫式演算法的理解還不夠深入,寫出來的程式效率不夠高而已!我的「神奇」演算法只是避開了沒有優化前的氾濫式演算法的一些重複計算而已。 所以我認為演算法的世界沒有太多「神奇」或「神秘」的事情,只要研究清楚了,必須計算的動作一定跑不了!不必算的,或重複算的如果能省下來,最終每個研究者能作出的軟體運算效能都不會差太多的!我現在的影像辨識速率與效能的CP值應該是能在台灣稱霸的!但我相信別的研發團隊,只要持續研究如何去蕪存菁,也一定會跟上來,甚至超越我的! 如果你的研究深入到我的程度,就一定不會迷信任何演算法裡面會有神了!當你聽說甚麼新的演算法很神奇的時候,重點是要去深入理解為什麼?而不是開始跟人家鬥嘴,硬說哪個演算法就是比較好!就像信教的人去爭論耶穌、佛祖或阿拉真神,哪個比較強大?那是一定不會有結論的!科學不是這樣運作的!別再嘴硬自居是甚麼派,最後讓自己出洋相了吧! |
|
| ( 心情隨筆|工作職場 ) |