字體:小 中 大
字體:小 中 大 |
|
|
|
| 2020/06/30 15:48:02瀏覽1570|回應0|推薦3 | |
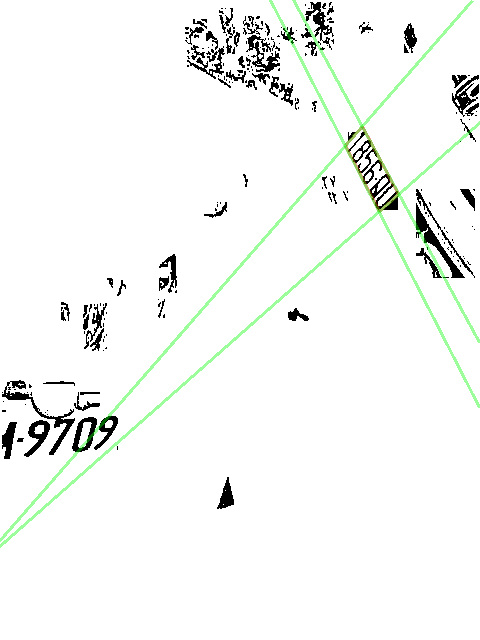
我追趕人類智慧,也就是作AI研究的腳步沒有停止,這幾天努力的方向是如何辨識更傾斜角度的車牌!在立體世界所謂的偏斜有兩個意義,一是從車牌正面到左右方斜視的角度,一是整個車牌底線與水平線的交角!做過車牌辨識演算法研究之後你就會發現,其實高角度的左右斜視比較簡單,只要影像畫素夠多夠清晰,字字分明就不難辨識,只是字變得比較瘦長而已。 真正對於傳統車牌演算法的終極考驗是水平傾斜的角度,因為大多數的車牌辨識演算法為了追求速度,都不會真的在全圖上做完整的目標搜尋,就是全彩→灰階→二值化→字元目標→組織車牌。而是假設車牌是個水平放置的矩形,如果畫面中的車牌不是水平的,那就會連車牌都找不到,就不必談辨識車牌內容了! 那我怎麼作的呢?其實我只是回歸到OCR字元辨識的原理,老老實實的做完全圖的影像處理,篩選出像是字元的目標,不管他們是不是水平,只要靠在一起「群聚」的目標就當作是車牌,開始嘗試辨識了!如果發現不是車牌,再找下一組嘛!在物理觀點上,我用的才是標準的OCR辨識程序,傳統的車牌辨識找車牌的方式反而是投機取巧的粗糙程序,所以才解不開傾斜車牌的難題,資訊不足嘛! 譬如上圖傾斜達60度的車牌,從二值化與篩選目標的結果看,其實是很清楚的!重點只是它是斜的,我必須有很精準的幾何運算讓他投影成標準大小與方向的車牌子影像。
正確找到車牌字元,再正確判定它們的邊線,將四條綠線切出的任意四邊形投影成車牌的標準大小即可!到這個程度,應該學過影像辨識的學生都會辨識是甚麼字元了!
所以基本上我沒有神奇的密技,只是老老實實按照課本上說的步驟實作而已!有趣的是為什麼其他人,尤其是以前作車牌辨識的人不這麼做呢?第一是他們不願意認真面對現實困難的狀況,實作這些過程需要很多的幾何運算,即使傳統的影像辨識書中也不會介紹,但要處理立體世界的影像,複雜的幾何操作是不可避免的!現在多數的影像辨識者還是很掙扎猶豫不願深入研究,總是想著有甚麼AI大神會下凡相助?所以機器學習才會這麼流行,想偷懶嘛! 第二個原因是要作出完整通用的程序,計算量就會很大,車牌辨識常常是需要即時反應的,辨識正確之外還要考慮執行速度,也不能總是買超級電腦來玩,太貴了!辨識車牌耗費的「成本」也是必須考慮的!還好電腦一直進步,以前不太可能變成商品化的演算法,現在有高效率多核心的電腦加持,我們軟體設計者揮灑的空間就大多了! 即使如此,一樣的電腦效能限制之下,如果你的演算法效率不好,能算出的結果資訊就會比較少,像我一樣能「完整」作完OCR程序的「玩家」應該很少!我可以做到這些事,其實跟我的演算法效率有極大的關係!就是一樣的動作過程我的程式會算得比別人快一點! 這其實也沒有太多的神祕色彩,就是不斷的思考數學公式,如何可以達到一樣的計算目的,但是盡量節省不必要的運算次數,點點滴滴不斷研究,久而久之該省的都省了,速度就快了!這真的是非常科學化精準的研究過程,絕對不是亂踹就能踹出一個洞來的!亂踹只會把你的腿踢斷! 上次我嘗試研究推進可辨識的傾斜角度時,大概是可以穩定達到±45度!這幾個月辨識核心大更新後,我再度嘗試在較新的辨識核心基礎上來挑戰這個議題,大概的成績是可以推到±60度左右,應該隨手亂拍的照片都難不倒我了!看看我的FB吧?
|
|
| ( 心情隨筆|工作職場 ) |